
一、前言
上一期在这里🥰:大数据项目 在线教育实时数仓-01-用户行为采集平台 - 滕王阁 。
简介
在线教育业务流程可以以一个普通用户的浏览足迹为例进行说明,用户点开在线教育网站首页开始浏览,可能会通过分类查询也可能通过全文检索寻找自己中意的课程,这些课程都是存储在后台管理系统中的。
当用户寻找到自己中意的课程,可能会想要购买,将商品添加到购物车后发现需要登录,登录后对课程进行结算,这时候购物车的管理和课程订单信息的生成都会对业务数据库产生影响,会生成相应的订单数据和支付数据。
订单正式生成之后,还会对订单进行跟踪处理,直到订单全部完成。
在线教育的主要业务流程包括用户前台浏览课程时的课程详情的管理,用户课程加入购物车进行支付时用户个人中心&支付服务的管理,用户支付完成后订单后台服务的管理,这些流程涉及到了十几个甚至几十个业务数据表,甚至更多。
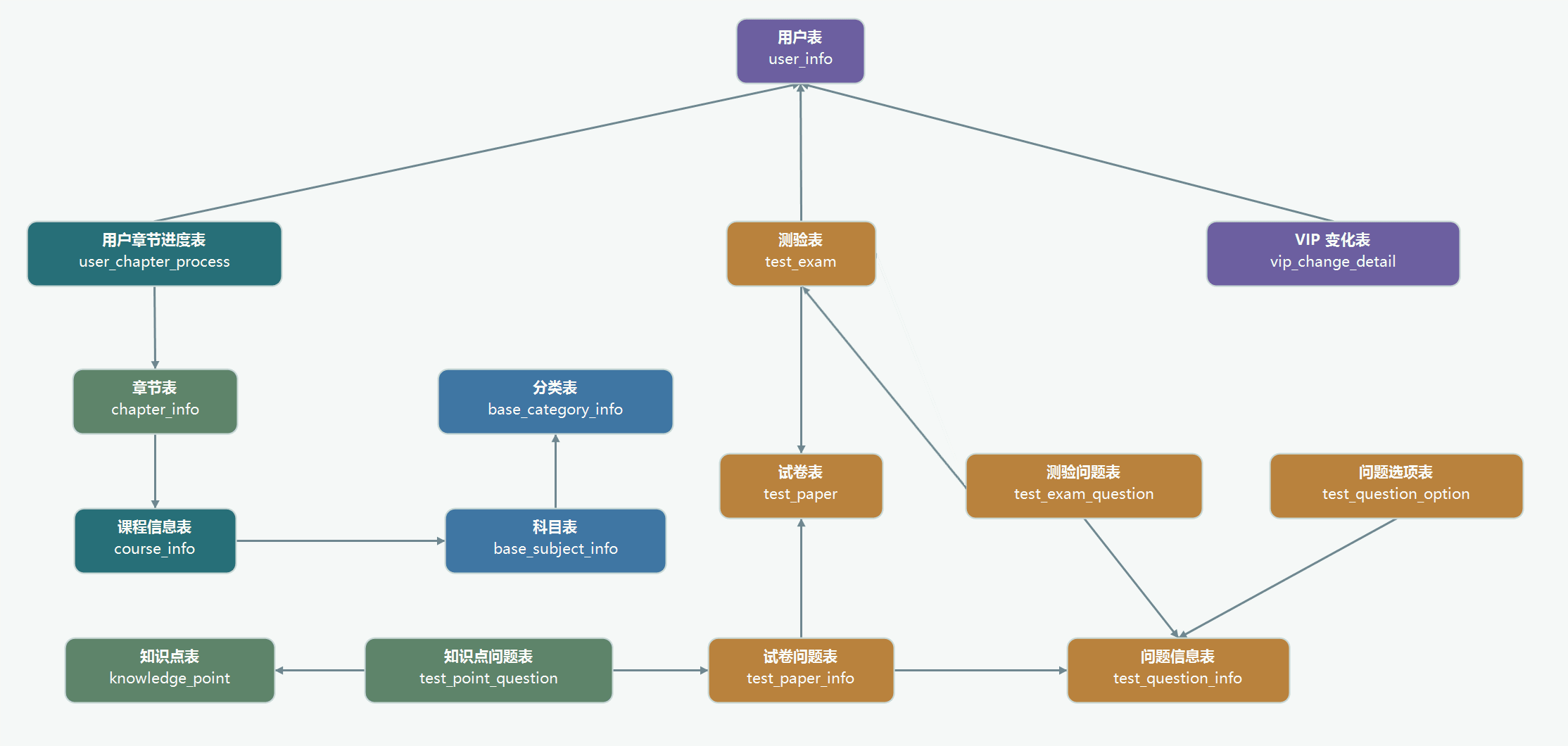
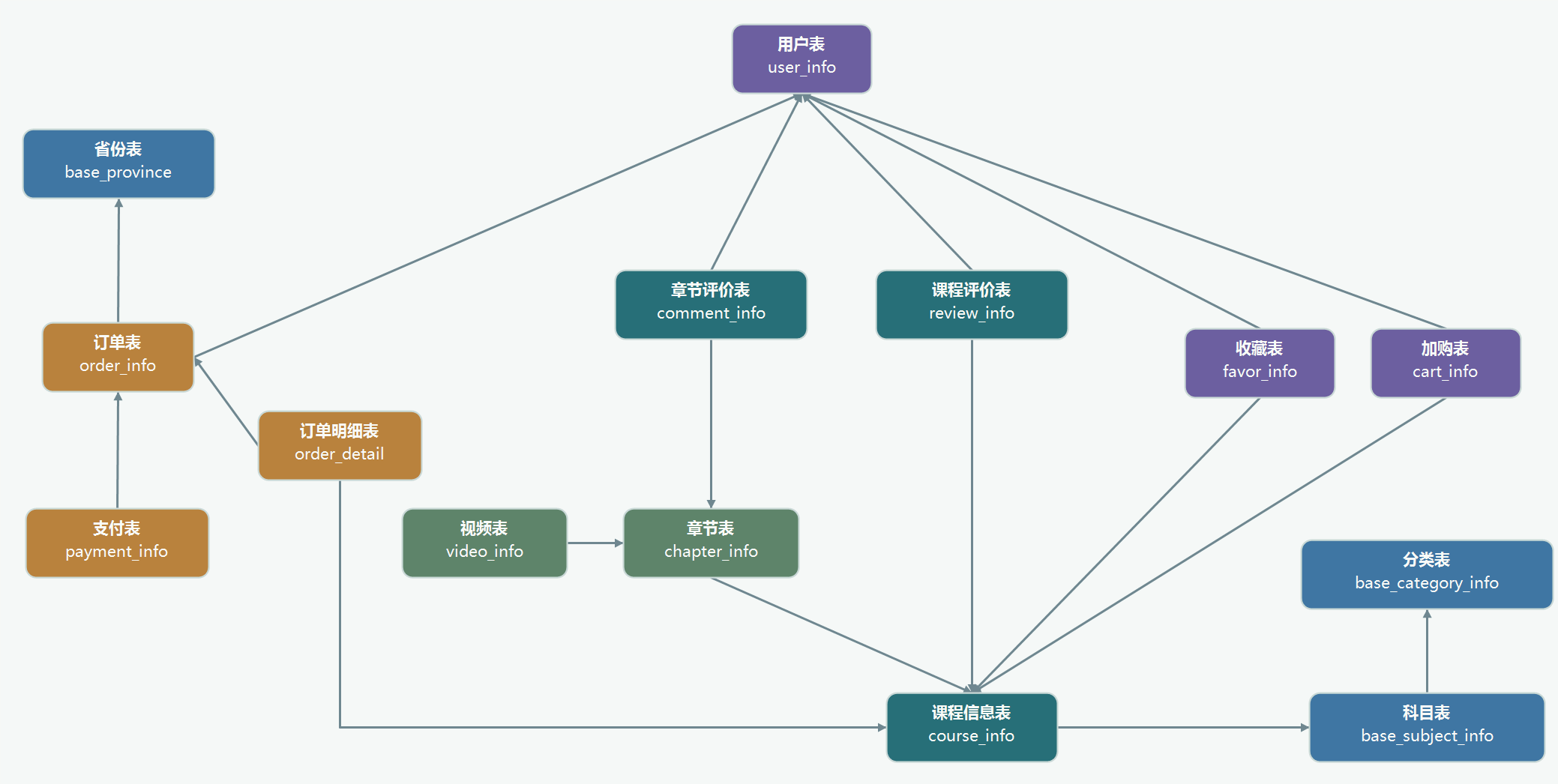
二、表结构
以下为本在线教育系统涉及到的业务数据表结构关系。这 25 张表以订单表、用户表、 课程信息表、测验表和用户章节进度表为中心,延伸出了支付表、订单明细表、章节表、课程评价表、科目表、试卷表、知识点表等,用户表提供用户的详细信息,支付表提供该订单的支付详情,订单详情表提供订单的课程等情况,课程表给订单明细表提供课程的详细信息。
分类表(base_category_info)
| 字段名 | 字段说明 |
|---|---|
| id | 编号(主键) |
| category_name | 分类名称 |
| create_time | 创建时间 |
| update_time | 更新时间 |
| deleted | 是否删除 |
省份表(base_province)
| 字段名 | 字段说明 |
|---|---|
| id | 编号(主键) |
| name | 省份名称 |
| region_id | 大区id |
| area_code | 行政区位码 |
| iso_code | 国际编码 |
| iso_3166_2 | ISO3166 编码 |
来源表(base_source)
| 字段名 | 字段说明 |
|---|---|
| id | 编号(主键) |
| source_site | 引流来源名称 |
| source_url | 引流来源链接 |
科目表(base_subject_info)
| 字段名 | 字段说明 |
|---|---|
| id | 编号(主键) |
| subject_name | 科目名称 |
| category_id | 分类 |
| create_time | 创建时间 |
| update_time | 更新时间 |
| deleted | 是否删除 |
加购表(cart_info)
| 字段名 | 字段说明 |
|---|---|
| id | 编号(主键) |
| user_id | 用户id |
| course_id | 课程id |
| course_name | 课程名称(冗余) |
| cart_price | 放入购物车时价格 |
| img_url | 图片URL |
| session_id | 会话id |
| create_time | 创建时间 |
| update_time | 修改时间 |
| deleted | 是否删除 |
| sold | 是否已售 |
章节表(chapter_info)
| 字段名 | 字段说明 |
|---|---|
| id | 编号(主键) |
| chapter_name | 章节名称 |
| course_id | 课程id |
| video_id | 视频id |
| publisher_id | 发布者id |
| is_free | 是否免费 |
| create_time | 创建时间 |
| update_time | 更新时间 |
| deleted | 是否删除 |
章节评价表(comment_info)
| 字段名 | 字段说明 |
|---|---|
| id | 编号(主键) |
| user_id | 用户id |
| chapter_id | 章节id |
| course_id | 课程id |
| comment_txt | 评价内容 |
| create_time | 创建时间 |
| deleted | 是否删除 |
课程信息表(course_info)
| 字段名 | 字段说明 |
|---|---|
| id | 编号(主键) |
| course_name | 课程名称 |
| course_slogan | 课程标语 |
| course_cover_url | 课程封面URL |
| subject_id | 科目id |
| teacher | 讲师名称 |
| publisher_id | 发布者id |
| chapter_num | 章节数 |
| origin_price | 原价 |
| reduce_amount | 优惠金额 |
| actual_price | 实际价格 |
| course_introduce | 课程介绍 |
| create_time | 创建时间 |
| update_time | 更新时间 |
| deleted | 是否删除 |
收藏表(favor_info)
| 字段名 | 字段说明 |
|---|---|
| id | 编号(主键) |
| course_id | 课程id |
| user_id | 用户id |
| create_time | 创建时间 |
| update_time | 更新时间 |
| deleted | 是否删除 |
知识点表(knowledge_point)
| 字段名 | 字段说明 |
|---|---|
| id | 编号(主键) |
| point_txt | 知识点内容 |
| point_level | 知识点级别 |
| course_id | 课程id |
| chapter_id | 章节id |
| publisher_id | 发布者id |
| create_time | 创建时间 |
| update_time | 修改时间 |
| deleted | 是否删除 |
订单明细表(order_detail)
| 字段名 | 字段说明 |
|---|---|
| id | 编号(主键) |
| course_id | 课程id |
| course_name | 课程名称 |
| order_id | 订单编号 |
| user_id | 用户id |
| origin_amount | 原始金额 |
| coupon_reduce | 优惠券减免金额 |
| final_amount | 最终金额 |
| session_id | 会话id (当前会话id 继承购物车中会话id) |
| create_time | 创建时间 |
| update_time | 更新时间 |
订单表(order_info)
| 字段名 | 字段说明 |
|---|---|
| id | 编号(主键) |
| user_id | 用户id |
| origin_amount | 原始金额 |
| coupon_reduce | 优惠券减免 |
| final_amount | 最终金额 |
| order_status | 订单状态 |
| out_trade_no | 订单交易编号(第三方支付用) |
| trade_body | 订单描述(第三方支付用) |
| session_id | 会话id |
| province_id | 省份id |
| create_time | 创建时间 |
| expire_time | 失效时间 |
| update_time | 更新时间 |
支付表(payment_info)
| 字段名 | 字段说明 |
|---|---|
| id | 编号(主键) |
| out_trade_no | 对外业务编号 |
| order_id | 订单编号 |
| alipay_trade_no | 支付宝交易编号 |
| total_amount | 支付金额 |
| trade_body | 交易内容 |
| payment_type | 支付类型 |
| payment_status | 支付状态 |
| create_time | 创建时间 |
| update_time | 更新时间 |
| callback_content | 回调信息 |
| callback_time | 回调时间 |
课程评价表(review_info)
| 字段名 | 字段说明 |
|---|---|
| id | 编号(主键) |
| user_id | 用户id |
| course_id | 课程id |
| review_txt | 评价内容 |
| review_stars | 评价星级 |
| create_time | 创建时间 |
| deleted | 是否删除 |
测验表(test_exam)
| 字段名 | 字段说明 |
|---|---|
| id | 编号(主键) |
| paper_id | 试卷id |
| user_id | 用户id |
| score | 分数 |
| duration_sec | 所用时长 |
| create_time | 创建时间 |
| submit_time | 提交时间 |
| update_time | 更新时间 |
| deleted | 是否删除 |
测验问题表(test_exam_question)
| 字段名 | 字段说明 |
|---|---|
| id | 编号(主键) |
| exam_id | 考试id |
| paper_id | 试卷id |
| question_id | 问题id |
| user_id | 用户id |
| answer | 答案 |
| is_correct | 是否正确 |
| score | 本题得分 |
| create_time | 创建时间 |
| update_time | 更新时间 |
| deleted | 是否删除 |
试卷表(test_paper)
| 字段名 | 字段说明 |
|---|---|
| id | 编号(主键) |
| paper_title | 试卷名称 |
| course_id | 课程id |
| create_time | 创建时间 |
| update_time | 更新时间 |
| publisher_id | 发布者id |
| deleted | 是否删除 |
试卷问题表(test_paper_question)
| 字段名 | 字段说明 |
|---|---|
| id | 编号(主键) |
| paper_id | 试卷id |
| question_id | 题目id |
| score | 题目分值 |
| create_time | 创建时间 |
| deleted | 是否删除 |
| publisher_id | 发布者id |
知识点问题表(test_point_question)
| 字段名 | 字段说明 |
|---|---|
| id | 编号(主键) |
| point_id | 知识点id |
| question_id | 问题id |
| create_time | 创建时间 |
| publisher_id | 发布者id |
| deleted | 是否删除 |
问题信息表(test_question_info)
| 字段名 | 字段说明 |
|---|---|
| id | 编号(主键) |
| question_txt | 题目内容 |
| chapter_id | 章节id |
| course_id | 课程id |
| question_type | 题目类型 |
| create_time | 创建时间 |
| update_time | 更新时间 |
| publisher_id | 发布者id |
| deleted | 是否删除 |
问题选项表(test_question_option)
| 字段名 | 字段说明 |
|---|---|
| id | 编号(主键) |
| option_txt | 选项内容 |
| question_id | 题目id |
| is_correct | 是否正确 |
| create_time | 创建时间 |
| update_time | 更新时间 |
| deleted | 是否删除 |
用户章节进度表(user_chapter_process)
| 字段名 | 字段说明 |
|---|---|
| id | 编号(主键) |
| course_id | 课程id |
| chapter_id | 章节id |
| user_id | 用户id |
| position_sec | 播放位置(秒) |
| create_time | 创建时间 |
| update_time | 更新时间 |
| deleted | 是否删除 |
用户表(user_info)
| 字段名 | 字段说明 |
|---|---|
| id | 编号(主键) |
| login_name | 用户名称 |
| nick_name | 用户昵称 |
| passwd | 用户密码 |
| real_name | 用户姓名 |
| phone_num | 手机号 |
| 邮箱 | |
| head_img | 头像URL |
| user_level | 用户级别 |
| birthday | 用户生日 |
| gender | 性别 M男,F女 |
| create_time | 创建时间 |
| operate_time | 修改时间 |
| status | 状态 |
视频表(video_info)
| 字段名 | 字段说明 |
|---|---|
| id | 编号(主键) |
| video_name | 视频名称 |
| during_sec | 时长 |
| video_status | 状态 未上传,上传中,上传完 |
| video_size | 大小 |
| video_url | 视频存储路径 |
| video_source_id | 云端资源编号 |
| version_id | 版本号 |
| chapter_id | 章节id |
| course_id | 课程id |
| publisher_id | 发布者id |
| create_time | 创建时间 |
| update_time | 更新时间 |
| deleted | 是否删除 |
VIP 变化表(vip_change_detail)
| 字段名 | 字段说明 |
|---|---|
| id | 编号(主键) |
| user_id | 用户id |
| from_vip | 原VIP等级 |
| to_vip | 新VIP等级 |
| create_time | 创建时间 |
三、业务数据采集模块
业务数据是数据仓库的重要数据来源。用户、课程、订单、支付、评价等数据最初都存储在业务数据库中,若要在数仓中进行统一建模和统计分析,就需要先将这些数据同步到数据仓库中。
在离线数仓中,数据计算通常以天为周期,因此业务数据同步一般也按天进行。也就是说,每天定时从业务数据库中抽取数据,写入数据仓库,供后续分层建模和指标统计使用。
业务数据同步时,常见的同步策略主要有两种:全量同步和增量同步。
1、数据同步策略
业务数据同步策略主要分为两类:
- 全量同步
- 增量同步
全量同步
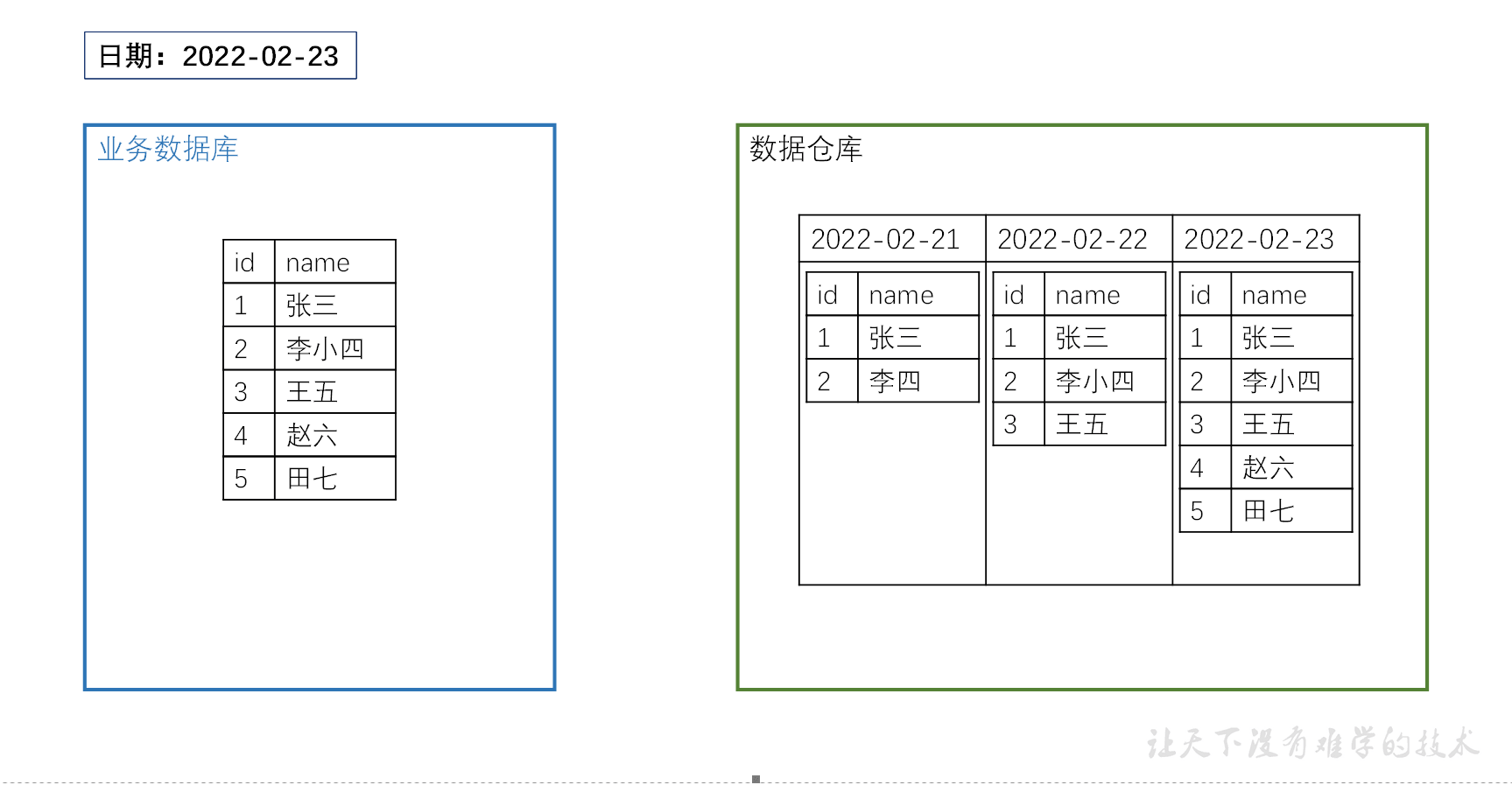
全量同步是指每天将业务数据库中某张表的全部数据完整同步到数据仓库中。
这种方式实现简单,不需要判断哪些数据发生了变化,只需要每天重新同步整张表即可。因此,全量同步是保证业务数据库和数据仓库数据一致性较为直接的方式。
不过,当表数据量较大、每日变化数据较少时,如果仍然每天同步整张表,就会产生较多重复传输和重复存储。
增量同步
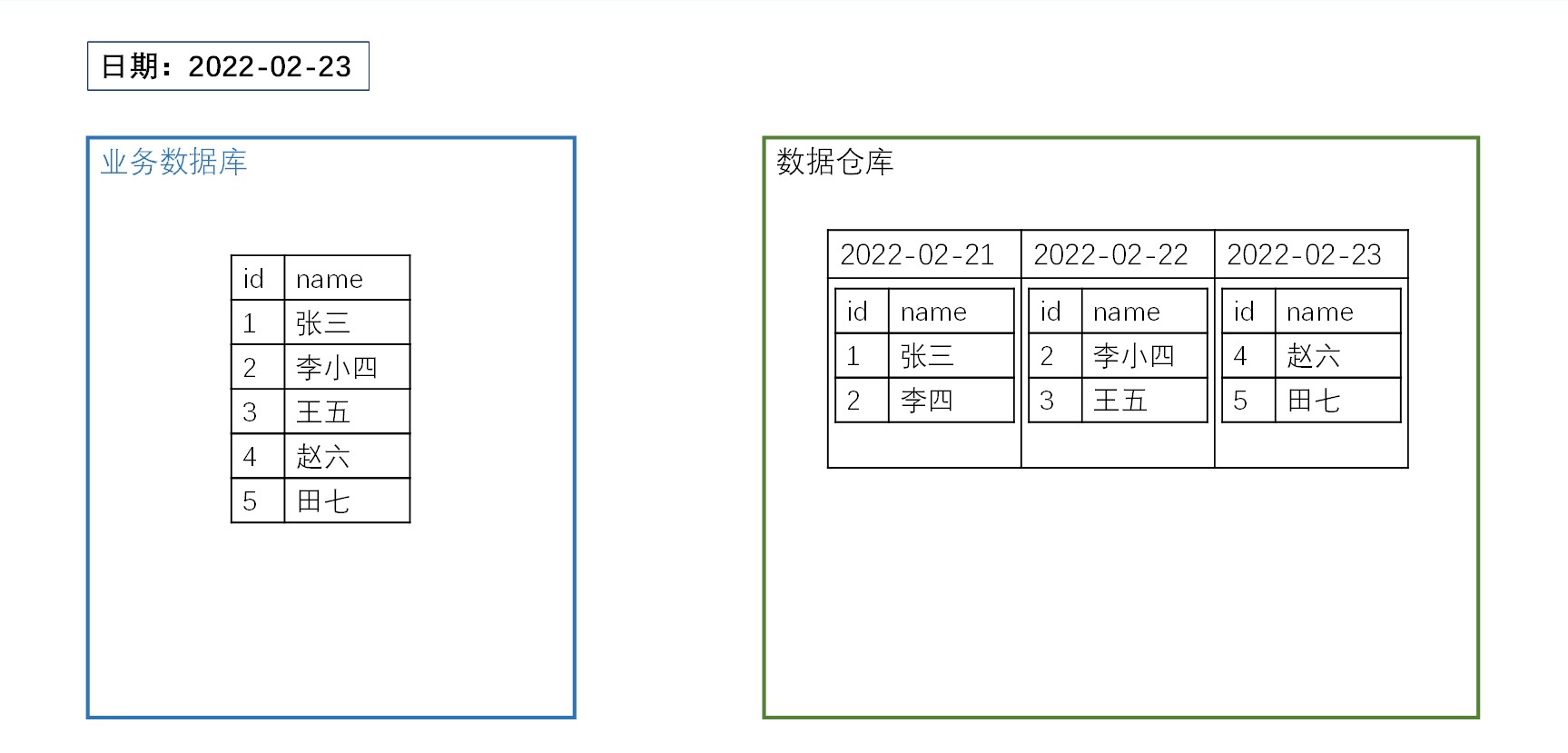
增量同步是指每天只同步业务数据库中新增或发生变化的数据。
相比全量同步,增量同步可以减少重复数据的传输和存储,更适合数据量较大、但每日变化比例较低的表。
需要注意的是,采用增量同步的表通常需要在首日先进行一次全量同步,用于初始化历史数据,之后再每天同步新增和变化数据。
2、数据同步策略选择
| 同步策略 | 优点 | 缺点 |
|---|---|---|
| 全量同步 | 逻辑简单,实现方便 | 当表数据量较大且每日变化较少时,会重复同步和存储大量相同数据,效率较低 |
| 增量同步 | 同步效率高,避免重复同步和存储未变化数据 | 实现逻辑相对复杂,需要将每日新增及变化数据与历史数据进行整合 |
- 如果表数据量较小,或者每日变化数据占比较高,可以采用全量同步。
- 如果表数据量较大,且每日变化数据占比较低,更适合采用增量同步。
- 如果后续数仓建模需要保留每日快照,也可以对部分表采用全量同步。
本项目中,各业务表的同步策略如下:
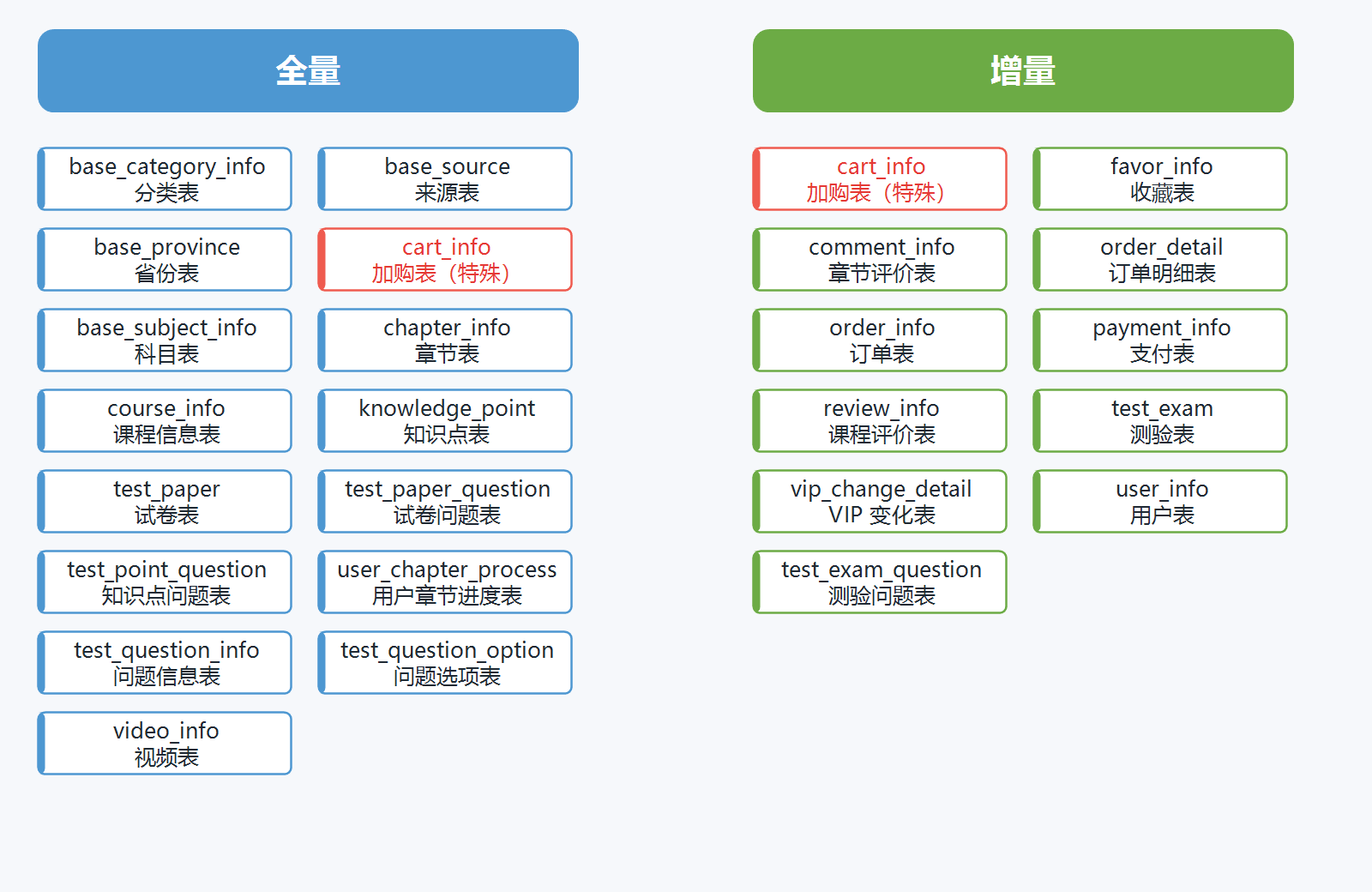
由于后续数仓建模需要,
cart_info表既需要进行全量同步,也需要进行增量同步。后续章节会结合具体建模过程进行说明。
3、数据同步工具选型
常见的数据同步工具较多,按照同步原理可以大致分为两类:
- 基于查询的离线批量同步工具
- 基于数据库变更日志的实时同步工具
基于查询的离线批量同步工具
这类工具的代表有:
- DataX
- Sqoop
它们通常通过 select 查询的方式从业务数据库中读取数据,再将数据写入目标存储系统。
全量同步通常使用这类工具实现,因为全量同步只需要每天查询整张表即可。
增量同步也可以使用这类工具实现,但通常要求业务表中存在类似下面的时间字段:
create_timeupdate_time
用于筛选出指定时间范围内新增或发生变化的数据。
基于变更日志的实时同步工具
这类工具的代表有:
- Maxwell
- Canal
它们通过监听数据库的变更日志来捕获数据变化。例如在 MySQL 中,可以通过监听 binlog 获取表中的 insert、update、delete 操作。
通常用于增量同步,因为它能够较完整地记录数据的变化过程。
增量同步方案对比
| 增量同步方案 | DataX / Sqoop | Maxwell / Canal |
|---|---|---|
| 同步原理 | 基于 select 查询获取数据 |
基于数据库变更日志获取数据 |
| 对数据库的要求 | 表中通常需要存在 create_time、update_time 等时间字段,用于筛选新增和变化数据 |
数据库需要开启变更日志,例如 MySQL 需要开启 binlog |
| 数据中间状态 | 离线批量同步,只能获取某个时间点的最终状态;如果一条数据一天内变化多次,中间状态无法获取 | 实时捕获所有变更操作,可以获取数据变化过程中的中间状态 |
| 适用场景 | 适合全量同步,或简单的离线增量同步 | 适合实时增量同步,尤其适合需要完整变更过程的场景 |
在本项目中,业务数据同步工具选择:
- 全量同步采用 DataX
- 增量同步采用 Maxwell
4、安装 DataX
这个项目怎么又不维护了,成天学过时的技术是吧😡。
DataX 是阿里开源的一款离线数据同步工具,主要用于在不同数据源之间进行批量数据传输。
它可以把数据从一个地方读取出来,再写入到另一个地方。例如:
- 从 MySQL 同步到 HDFS
- 从 MySQL 同步到 Hive
- 从 Oracle 同步到 MySQL
- 从文本文件同步到数据库
DataX 的核心思想是 Reader + Writer:
Reader:负责从源端读取数据Writer:负责把数据写入目标端
例如,从 MySQL 同步数据到 HDFS 时:
mysqlreader负责读取 MySQL 数据hdfswriter负责写入 HDFS
DataX 通常用于业务数据的全量同步,也可以配合时间字段实现简单的增量同步。
软件包下载
GitHub 官方仓库地址:https://github.com/alibaba/DataX
README.TXT 里面有下载地址。
百度网盘下载地址:https://pan.baidu.com/s/1BeGFoCIST1u5U7t3Dn303Q?pwd=vzke
下载好后将软件压缩包使用 MobeXterm 上传到 hadoop101 的 ~/ansible/files 目录下。
和前面安装软件的过程一样,复制文件名,将之前写好的 deploy_package.yml 中的变量进行替换,注意 hosts 改为 hadoop101,这个软件不需要所以集群都安装。
替换后的 deploy_package.yml:
- name: Deploy package
hosts: hadoop101
vars:
pkg_name: datax.tar.gz
dest_dir: datax-202309
tasks:
- name: Copy archive
copy:
src: "./files/{{ pkg_name }}"
dest: "/opt/{{ pkg_name }}"
- name: Get top directory name from archive
shell: tar -tf /opt/{{ pkg_name }} | head -1 | cut -d/ -f1
register: archive_dir
- name: Extract archive
command: tar -xzf /opt/{{ pkg_name }} -C /opt
- name: Rename directory
command: mv /opt/{{ archive_dir.stdout | trim }} /opt/{{ dest_dir }}
args:
creates: /opt/{{ dest_dir }}
- name: Change ownership
file:
path: "/opt/{{ dest_dir }}"
owner: vaultattic
group: vaultattic
recurse: yes
- name: Remove archive
file:
path: "/opt/{{ pkg_name }}"
state: absent
运行 deploy_package.yml:
ansible-playbook deploy_package.yml
执行完后可以在各节点的 /opt 目录下查看 Datax 目录是否只存在 hadoop101 上。
cluster-run.sh ls /opt
[vaultattic@hadoop101 ansible]$ cluster-run.sh ls /opt
--------- hadoop101 ----------
amazon-corretto-8
data_mocker
datax-202309
flume-1.11.0
hadoop-3.3.6
kafka-3.9.2
zookeeper-3.8.6
--------- hadoop102 ----------
amazon-corretto-8
flume-1.11.0
hadoop-3.3.6
kafka-3.9.2
zookeeper-3.8.6
--------- hadoop103 ----------
amazon-corretto-8
flume-1.11.0
hadoop-3.3.6
kafka-3.9.2
zookeeper-3.8.6
[vaultattic@hadoop101 ansible]$
使用 set_env.yml 配置 DATAX_HOME 环境变量。
复制要配置环境变量的目录路径,将 set_env.yml 中的变量进行替换:
---
- name: Configure environment variables
hosts: hadoop101
vars:
env_name: DATAX_HOME
env_path: /opt/datax-202309
tasks:
- name: Add environment variables to /home/vaultattic/.bashrc
lineinfile:
path: "/home/vaultattic/.bashrc"
line: "export {{ env_name }}={{ env_path }}"
create: yes
- name: Add PATH for {{ env_name }}
lineinfile:
path: "/home/vaultattic/.bashrc"
line: "export PATH=${{ env_name }}/bin:$PATH"
运行 set_env.yml:
ansible-playbook set_env.yml
执行 playbook 后刷新环境变量,并执行一个自检任务:
source ~/.bashrc
python $DATAX_HOME/bin/datax.py $DATAX_HOME/job/job.json
[vaultattic@hadoop101 ansible]$ source ~/.bashrc
[vaultattic@hadoop101 ansible]$ python $DATAX_HOME/bin/datax.py $DATAX_HOME/job/job.json
DataX (DATAX-OPENSOURCE-3.0), From Alibaba !
Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.
2026-06-08 17:23:19.099 [main] INFO MessageSource - JVM TimeZone: GMT+08:00, Locale: zh_CN
2026-06-08 17:23:19.103 [main] INFO MessageSource - use Locale: zh_CN timeZone: sun.util.calendar.ZoneInfo[id="GMT+08:00",offset=28800000,dstSavings=0,useDaylight=false,transitions=0,lastRule=null]
2026-06-08 17:23:19.169 [main] INFO VMInfo - VMInfo# operatingSystem class => sun.management.OperatingSystemImpl
2026-06-08 17:23:19.177 [main] INFO Engine - the machine info =>
osInfo: Linux amd64 6.12.0-124.8.1.el10_1.x86_64
jvmInfo: Amazon.com Inc. 1.8 25.482-b08
cpu num: 2
totalPhysicalMemory: -0.00G
freePhysicalMemory: -0.00G
maxFileDescriptorCount: -1
currentOpenFileDescriptorCount: -1
GC Names [PS MarkSweep, PS Scavenge]
MEMORY_NAME | allocation_size | init_size
PS Eden Space | 256.00MB | 256.00MB
Code Cache | 240.00MB | 2.44MB
Compressed Class Space | 1,024.00MB | 0.00MB
PS Survivor Space | 42.50MB | 42.50MB
PS Old Gen | 683.00MB | 683.00MB
Metaspace | -0.00MB | 0.00MB
2026-06-08 17:23:19.189 [main] INFO Engine -
{
"setting":{
"speed":{
"channel":1
},
"errorLimit":{
"record":0,
"percentage":0.02
}
},
"content":[
{
"reader":{
"name":"streamreader",
"parameter":{
"column":[
{
"value":"DataX",
"type":"string"
},
{
"value":20250101,
"type":"long"
},
{
"value":"2025-01-01 00:00:00",
"type":"date"
},
{
"value":true,
"type":"bool"
},
{
"value":"test",
"type":"bytes"
}
],
"sliceRecordCount":100000
}
},
"writer":{
"name":"streamwriter",
"parameter":{
"print":false,
"encoding":"UTF-8"
}
}
}
]
}
2026-06-08 17:23:19.221 [main] INFO PerfTrace - PerfTrace traceId=job_-1, isEnable=false
2026-06-08 17:23:19.221 [main] INFO JobContainer - DataX jobContainer starts job.
2026-06-08 17:23:19.222 [main] INFO JobContainer - Set jobId = 0
2026-06-08 17:23:19.237 [job-0] INFO JobContainer - jobContainer starts to do prepare ...
2026-06-08 17:23:19.237 [job-0] INFO JobContainer - DataX Reader.Job [streamreader] do prepare work .
2026-06-08 17:23:19.237 [job-0] INFO JobContainer - DataX Writer.Job [streamwriter] do prepare work .
2026-06-08 17:23:19.238 [job-0] INFO JobContainer - jobContainer starts to do split ...
2026-06-08 17:23:19.238 [job-0] INFO JobContainer - Job set Channel-Number to 1 channels.
2026-06-08 17:23:19.238 [job-0] INFO JobContainer - DataX Reader.Job [streamreader] splits to [1] tasks.
2026-06-08 17:23:19.239 [job-0] INFO JobContainer - DataX Writer.Job [streamwriter] splits to [1] tasks.
2026-06-08 17:23:19.260 [job-0] INFO JobContainer - jobContainer starts to do schedule ...
2026-06-08 17:23:19.269 [job-0] INFO JobContainer - Scheduler starts [1] taskGroups.
2026-06-08 17:23:19.272 [job-0] INFO JobContainer - Running by standalone Mode.
2026-06-08 17:23:19.285 [taskGroup-0] INFO TaskGroupContainer - taskGroupId=[0] start [1] channels for [1] tasks.
2026-06-08 17:23:19.292 [taskGroup-0] INFO Channel - Channel set byte_speed_limit to -1, No bps activated.
2026-06-08 17:23:19.293 [taskGroup-0] INFO Channel - Channel set record_speed_limit to -1, No tps activated.
2026-06-08 17:23:19.309 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[0] attemptCount[1] is started
2026-06-08 17:23:19.713 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[0] is successed, used[404]ms
2026-06-08 17:23:19.714 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] completed it's tasks.
2026-06-08 17:23:29.297 [job-0] INFO StandAloneJobContainerCommunicator - Total 100000 records, 2600000 bytes | Speed 253.91KB/s, 10000 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.069s | All Task WaitReaderTime 0.091s | Percentage 100.00%
2026-06-08 17:23:29.297 [job-0] INFO AbstractScheduler - Scheduler accomplished all tasks.
2026-06-08 17:23:29.298 [job-0] INFO JobContainer - DataX Writer.Job [streamwriter] do post work.
2026-06-08 17:23:29.298 [job-0] INFO JobContainer - DataX Reader.Job [streamreader] do post work.
2026-06-08 17:23:29.298 [job-0] INFO JobContainer - DataX jobId [0] completed successfully.
2026-06-08 17:23:29.299 [job-0] INFO HookInvoker - No hook invoked, because base dir not exists or is a file: /opt/datax-v202309/hook
2026-06-08 17:23:29.300 [job-0] INFO JobContainer -
[total cpu info] =>
averageCpu | maxDeltaCpu | minDeltaCpu
-1.00% | -1.00% | -1.00%
[total gc info] =>
NAME | totalGCCount | maxDeltaGCCount | minDeltaGCCount | totalGCTime | maxDeltaGCTime | minDeltaGCTime
PS MarkSweep | 0 | 0 | 0 | 0.000s | 0.000s | 0.000s
PS Scavenge | 0 | 0 | 0 | 0.000s | 0.000s | 0.000s
2026-06-08 17:23:29.300 [job-0] INFO JobContainer - PerfTrace not enable!
2026-06-08 17:23:29.301 [job-0] INFO StandAloneJobContainerCommunicator - Total 100000 records, 2600000 bytes | Speed 253.91KB/s, 10000 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.069s | All Task WaitReaderTime 0.091s | Percentage 100.00%
2026-06-08 17:23:29.302 [job-0] INFO JobContainer -
任务启动时刻 : 2026-06-08 17:23:19
任务结束时刻 : 2026-06-08 17:23:29
任务总计耗时 : 10s
任务平均流量 : 253.91KB/s
记录写入速度 : 10000rec/s
读出记录总数 : 100000
读写失败总数 : 0
[vaultattic@hadoop101 ansible]$
读写失败总数如果为 0 说明安装成功🥰。
DataX 的使用方式很简单:根据数据同步的源和目标选择对应的 Reader 和 Writer,然后将相关参数写入一个 JSON 配置文件,最后通过 DataX 命令提交任务即可。
例如,将 MySQL 数据同步到 HDFS 时,需要使用:
mysqlreader:负责读取 MySQL 数据hdfswriter:负责写入 HDFS 数据
如果是将 HDFS 数据同步到 MySQL,则需要使用:
hdfsreader:负责读取 HDFS 数据mysqlwriter:负责写入 MySQL 数据
DataX 任务提交命令
DataX 任务通过 datax.py 脚本提交,基本命令格式如下:
python $DATAX_HOME/bin/datax.py path/to/your/job.json
其中,path/to/your/job.json 是 DataX 任务配置文件路径。
例如,在 DataX 安装目录下执行某个任务:
任务提交后,DataX 会根据 JSON 配置文件中的 Reader 和 Writer 信息,完成数据读取、传输和写入。
DataX 配置文件格式
DataX 的同步任务通过 JSON 文件进行描述,本项目中,全量表同步使用的插件和 JSON 配置文档如下:
| 数据方向 | DataX 插件 | 插件文档 |
|---|---|---|
| MySQL -> DataX | mysqlreade |
https://github.com/alibaba/DataX/blob/master/mysqlreader/doc/mysqlreader.md |
| DataX -> HDFS | hdfswriter |
https://github.com/alibaba/DataX/blob/master/hdfswriter/doc/hdfswriter.md |
编写配置文件时,可以先通过命令查看指定 Reader 和 Writer 的配置模板。
例如,查看 mysqlreader 到 hdfswriter 的配置模板:
python $DATAX_HOME/bin/datax.py -r mysqlreader -w hdfswriter
[vaultattic@hadoop101 ~]$ python $DATAX_HOME/bin/datax.py -r mysqlreader -w hdfswriter
DataX (DATAX-OPENSOURCE-3.0), From Alibaba !
Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.
Please refer to the mysqlreader document:
https://github.com/alibaba/DataX/blob/master/mysqlreader/doc/mysqlreader.md
Please refer to the hdfswriter document:
https://github.com/alibaba/DataX/blob/master/hdfswriter/doc/hdfswriter.md
Please save the following configuration as a json file and use
python {DATAX_HOME}/bin/datax.py {JSON_FILE_NAME}.json
to run the job.
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [],
"connection": [
{
"jdbcUrl": [],
"table": []
}
],
"password": "",
"username": "",
"where": ""
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [],
"compress": "",
"defaultFS": "",
"fieldDelimiter": "",
"fileName": "",
"fileType": "",
"path": "",
"writeMode": ""
}
}
}
],
"setting": {
"speed": {
"channel": ""
}
}
}
}
[vaultattic@hadoop101 ~]$
从结构上看,DataX 配置文件最外层是 job,其中主要包含两部分:
| 配置项 | 说明 |
|---|---|
| setting | 用于配置整个同步任务的运行参数,例如并发数、限速等 |
| content | 用于配置数据源和目标端,也就是 Reader 和 Writer |
其中,content 中又包含:
| 配置项 | 说明 |
|---|---|
| reader | 数据读取端配置,指定从哪里读取数据 |
| writer | 数据写入端配置,指定将数据写到哪里 |
Reader 和 Writer 的具体参数会根据插件不同而有所差异。例如,mysqlreader 需要配置 MySQL 连接信息、表名、字段等;hdfswriter 需要配置 HDFS 地址、输出路径、文件格式等。
常见配置项含义如下:
| 配置项 | 说明 |
|---|---|
| name | 插件名称,例如 mysqlreader、hdfswriter |
| parameter | 插件参数配置,不同插件参数不同 |
| connection | 数据源或目标端连接信息 |
| column | 读取或写入的字段列表 |
| setting.speed.channel | 同步任务的并发通道数 |
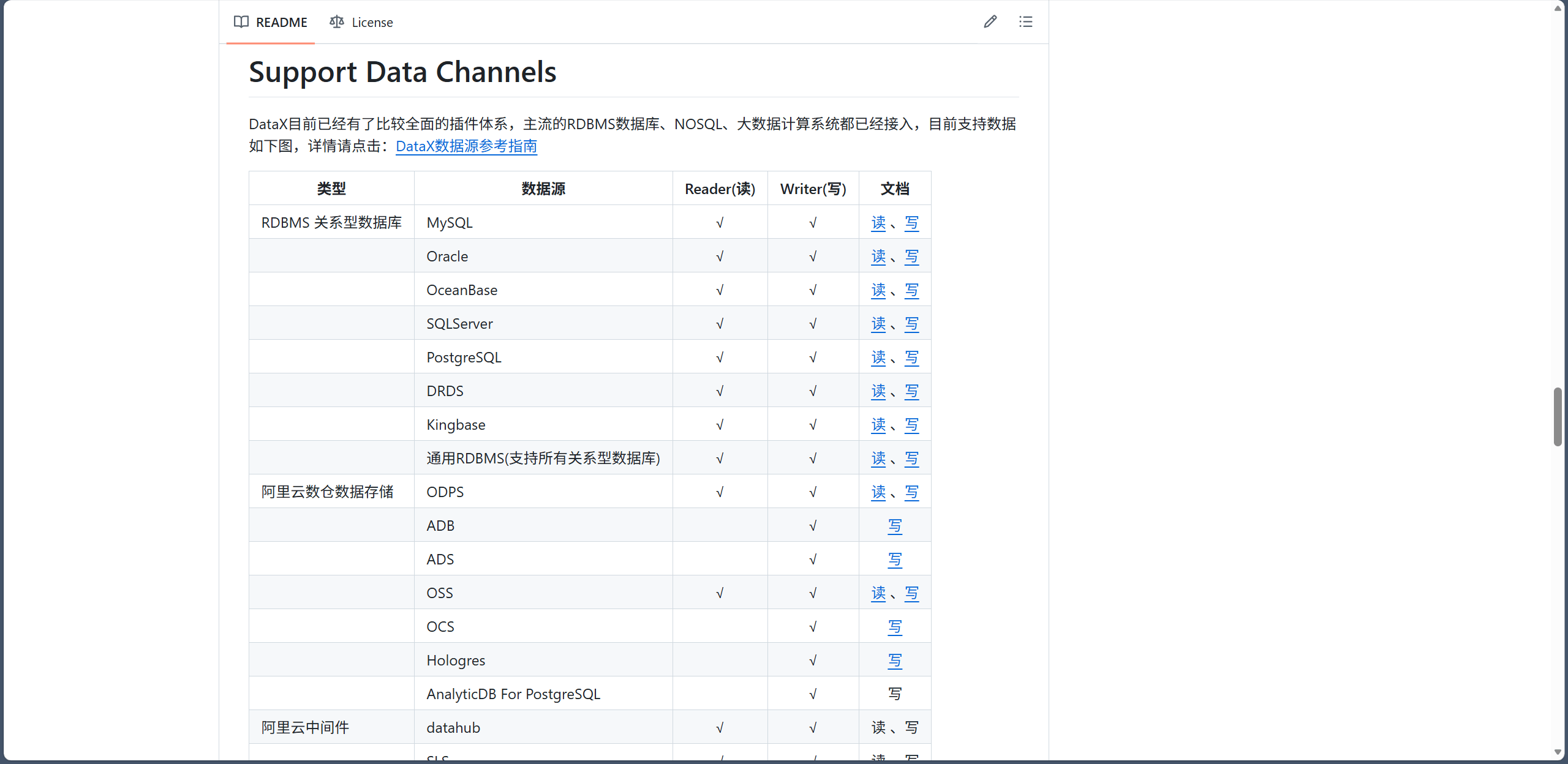
更多参数可以参考 DataX GitHub 官网仓库 README.TXT 中的一个支持表格:https://github.com/alibaba/DataX 。
5、安装 Maxwell
Maxwell 是一款基于 MySQL binlog 的实时数据采集工具,主要用于捕获 MySQL 中的数据变更,并将变更数据发送到 Kafka、Kinesis、RabbitMQ、Redis 等目标端。
它的工作方式可以简单理解为:Maxwell 伪装成 MySQL 的一个从库,实时监听 MySQL 的 binlog 日志。当业务表发生 insert、update、delete 操作时,Maxwell 会解析这些变更,并将变更内容封装成 JSON 格式输出。
例如:
MySQL 执行插入语句:
INSERT INTO school.student(id, name, age)
VALUES(1, 'tom', 18);
Maxwell 输出示例:
{
"database": "school",
"table": "student",
"type": "insert",
"ts": 1700000000,
"xid": 203401,
"commit": true,
"data": {
"id": 1,
"name": "tom",
"age": 18
}
}
MySQL 执行修改语句:
UPDATE school.student
SET age = 19
WHERE id = 1;
Maxwell 输出示例:
{
"database": "school",
"table": "student",
"type": "update",
"ts": 1700000060,
"xid": 203522,
"commit": true,
"data": {
"id": 1,
"name": "tom",
"age": 19
},
"old": {
"age": 18
}
}
MySQL 执行删除语句:
DELETE FROM school.student
WHERE id = 1;
Maxwell 输出示例:
{
"database": "school",
"table": "student",
"type": "delete",
"ts": 1700000120,
"xid": 203689,
"commit": true,
"data": {
"id": 1,
"name": "tom",
"age": 19
}
}
Maxwell 常用于业务数据的增量同步。相比每天通过 SQL 查询增量数据,Maxwell 可以更完整地捕获数据的变化过程,尤其是一条数据在一天内多次变化时,也可以记录每一次变更。
软件包下载
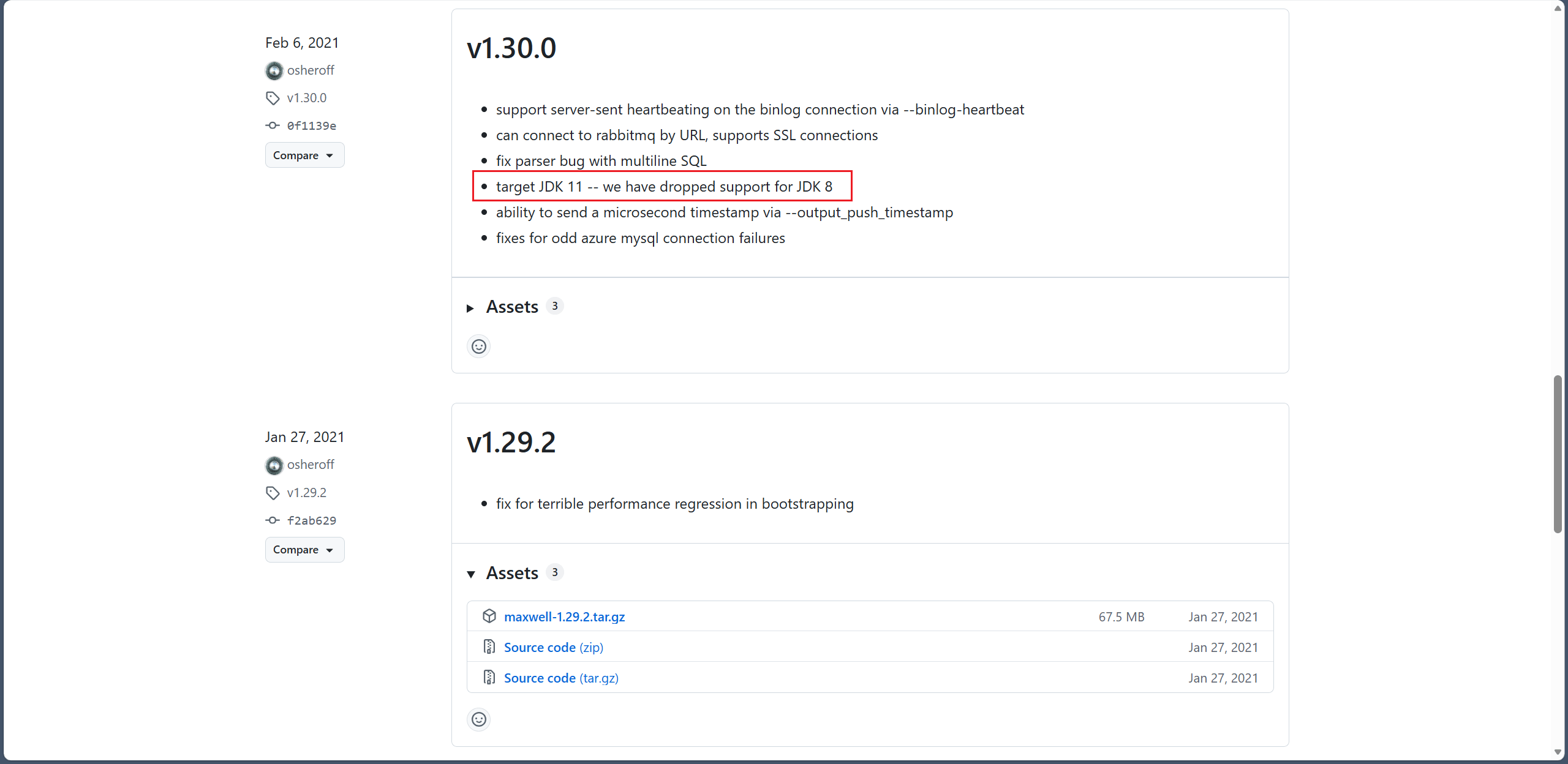
Maxwell 从 1.30.0 开始就不支持 JDK 8 了,使用这个项目要用的话得去他们的 GitHub 仓库下载历史版本,不能用最新版。
去官网下载最新版使用。
本来是按照原教程使用最后一个支持 JDK 8 的版本的,也就是 1.29.2。但这有出现了一个问题,我使用的 MySQL 数据库版本也没按教程的来,用的是新版 8.4.8,而 Maxwell 1.29.2 在运行时会使用
SHOW MASTER STATUS;命令,这个命令在 MySQL 8.4.8 已经被废弃了,所以启动时会报错:ERROR 1064 (42000): You have an error in your SQL syntax;
check the manual that corresponds to your MySQL server version for the right syntax to use near 'MASTER STATUS' at line 1现在只能被迫使用最新版的 Maxwell,单独将他的 JDK 改为更高的版本😵💫。
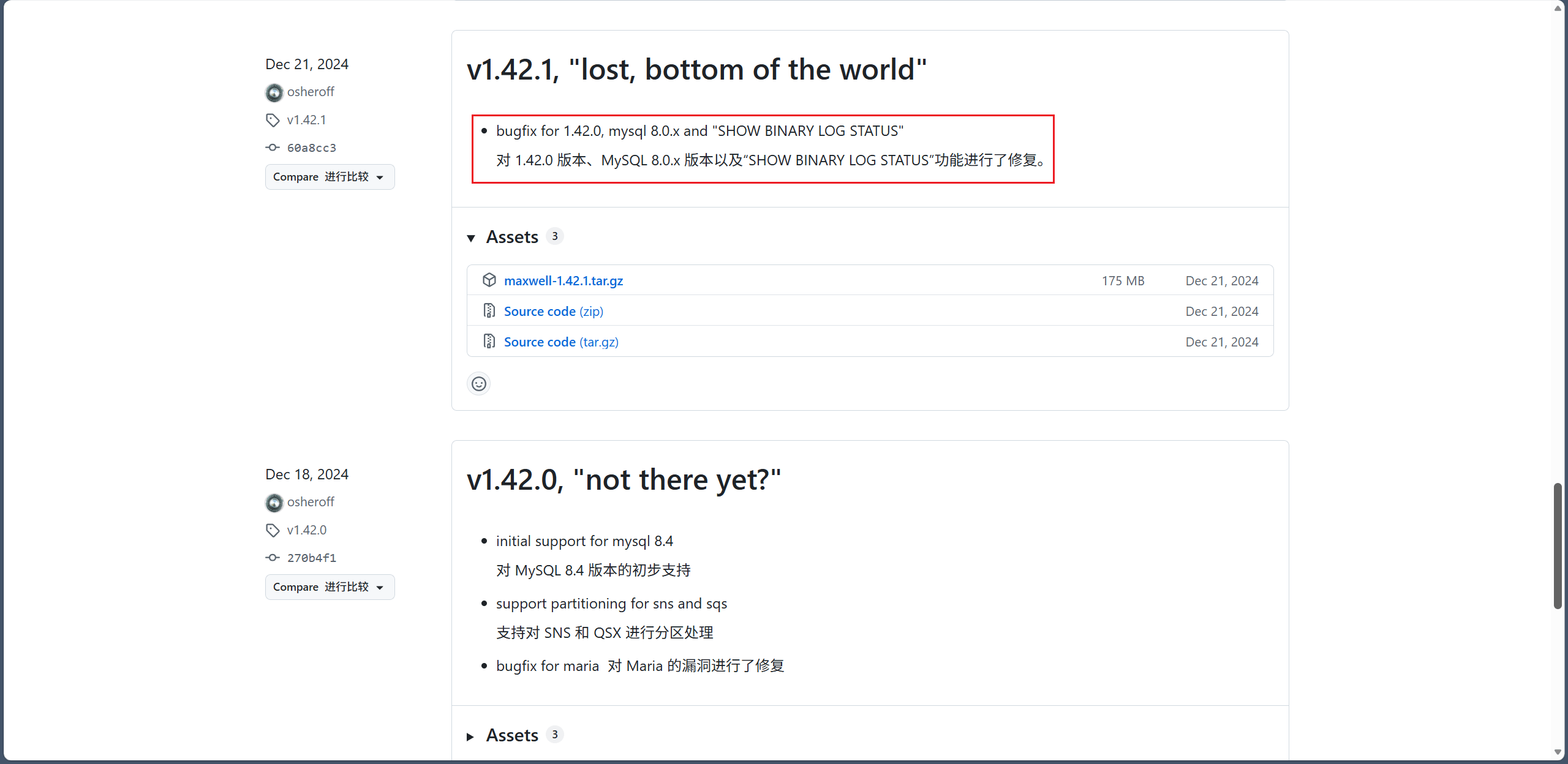
没找到还有后续,实测官网的那个最新版也不可以使用,我当时该用官网的最新版后就没测试了,后面整体测试时又出现了一样的问题,后面才官方的那个甚至也不是最新版(可能是忘记更新官网下载链接了),最新版得去他们的 GitHub Release 里面找,而且这个 BUG 到 1.42.1 才修复,还得用很高的版本🥲。
GitHub 官方仓库下载链接:https://github.com/zendesk/maxwell/releases/download/v1.44.1/maxwell-1.44.1.tar.gz
百度网盘下载链接:https://pan.baidu.com/s/1c9mHGQzVviUSrh6j_tCx9g?pwd=3a3n
下载好后将软件压缩包使用 MobeXterm 上传到 hadoop101 的 ~/ansible/files 目录下。
和前面安装软件的过程一样,复制文件名,将之前写好的 deploy_package.yml 中的变量进行替换,注意 hosts 改为 hadoop101,这个软件不需要所以集群都安装。
替换后的 deploy_package.yml:
- name: Deploy package
hosts: hadoop101
vars:
pkg_name: maxwell-1.44.1.tar.gz
dest_dir: maxwell-1.44.1
tasks:
- name: Copy archive
copy:
src: "./files/{{ pkg_name }}"
dest: "/opt/{{ pkg_name }}"
- name: Get top directory name from archive
shell: tar -tf /opt/{{ pkg_name }} | head -1 | cut -d/ -f1
register: archive_dir
- name: Extract archive
command: tar -xzf /opt/{{ pkg_name }} -C /opt
- name: Rename directory
command: mv /opt/{{ archive_dir.stdout | trim }} /opt/{{ dest_dir }}
args:
creates: /opt/{{ dest_dir }}
- name: Change ownership
file:
path: "/opt/{{ dest_dir }}"
owner: vaultattic
group: vaultattic
recurse: yes
- name: Remove archive
file:
path: "/opt/{{ pkg_name }}"
state: absent
运行 deploy_package.yml:
ansible-playbook deploy_package.yml
执行完后可以在各节点的 /opt 目录下查看 Maxwell 目录是否只存在 hadoop101 上。
cluster-run.sh ls /opt
[vaultattic@hadoop101 ansible]$ cluster-run.sh ls /opt
--------- hadoop101 ----------
amazon-corretto-8
data_mocker
datax-202309
flume-1.11.0
hadoop-3.3.6
kafka-3.9.2
maxwell-1.44.1
zookeeper-3.8.6
--------- hadoop102 ----------
amazon-corretto-8
flume-1.11.0
hadoop-3.3.6
kafka-3.9.2
zookeeper-3.8.6
--------- hadoop103 ----------
amazon-corretto-8
flume-1.11.0
hadoop-3.3.6
kafka-3.9.2
zookeeper-3.8.6
[vaultattic@hadoop101 ansible]$
安装 JDK 11
上面解释了新版本 Maxwell 不兼容 JDK 8,老版本 Maxwell 不兼容 MySQL 8.4.8,所以下面给新版 Maxwell 单独使用 JDK 11。
其实如果像我一样喜欢用新版的话一开始就应该全部换成 JDK 11 的,我会看了一下 JDK 11 可以全部兼容这个项目,JDK 8 还是太老了😥。
这里用 OpenJDK 的发行版 Corretto 8,下载地址:Downloads for Amazon Corretto 8 - Amazon Corretto 8
Corretto 8 百度网盘下载链接:https://pan.baidu.com/s/1RPezDnEcdqbc93pu6H_vWQ?pwd=ikqu
下载好后将软件压缩包使用 MobeXterm 上传到 hadoop101 的 ~/ansible/files 目录下。
和前面安装软件的过程一样,复制文件名,将之前写好的 deploy_package.yml 中的变量进行替换,注意 hosts 改为 hadoop101,这个软件不需要所以集群都安装。
替换后的 deploy_package.yml:
- name: Deploy package
hosts: hadoop101
vars:
pkg_name: amazon-corretto-11.0.31.11.1-linux-x64.tar.gz
dest_dir: amazon-corretto-11
tasks:
- name: Copy archive
copy:
src: "./files/{{ pkg_name }}"
dest: "/opt/{{ pkg_name }}"
- name: Get top directory name from archive
shell: tar -tf /opt/{{ pkg_name }} | head -1 | cut -d/ -f1
register: archive_dir
- name: Extract archive
command: tar -xzf /opt/{{ pkg_name }} -C /opt
- name: Rename directory
command: mv /opt/{{ archive_dir.stdout | trim }} /opt/{{ dest_dir }}
args:
creates: /opt/{{ dest_dir }}
- name: Change ownership
file:
path: "/opt/{{ dest_dir }}"
owner: vaultattic
group: vaultattic
recurse: yes
- name: Remove archive
file:
path: "/opt/{{ pkg_name }}"
state: absent
运行 deploy_package.yml:
ansible-playbook deploy_package.yml
执行完后可以在各节点的 /opt 目录下查看 amazon-corretto-11 目录是否只存在 hadoop101 上。
cluster-run.sh ls /opt
[vaultattic@hadoop101 ansible]$ cluster-run.sh ls /opt
--------- hadoop101 ----------
amazon-corretto-11
amazon-corretto-8
data_mocker
datax-202309
flume-1.11.0
hadoop-3.3.6
kafka-3.9.2
maxwell-1.44.1
zookeeper-3.8.6
--------- hadoop102 ----------
amazon-corretto-8
flume-1.11.0
hadoop-3.3.6
kafka-3.9.2
zookeeper-3.8.6
--------- hadoop103 ----------
amazon-corretto-8
flume-1.11.0
hadoop-3.3.6
kafka-3.9.2
zookeeper-3.8.6
[vaultattic@hadoop101 ansible]$
开启 MySQL binlog
Maxwell 通过监听 MySQL binlog 获取数据变更,因此需要先开启 MySQL binlog,并将 binlog 格式设置为 ROW。
官方文档:Quick Start - Maxwell's Daemon 。
编辑 MySQL 配置文件:
sudo vim /etc/my.cnf
在 [mysqld] 下添加或修改以下配置:
server_id=1
log-bin=mysql-bin
binlog_format=row
binlog-do-db=edu
| 参数 | 说明 |
|---|---|
| server_id | MySQL 服务编号,开启 binlog 时必须配置 |
| log-bin | 开启 binlog,并指定 binlog 文件名前缀 |
| binlog_format | binlog 日志格式,Maxwell 要求为 row |
| binlog-do-db | 指定记录 binlog 的数据库,这里表示只记录 edu 库 |
修改完成后,重启 MySQL:
sudo systemctl restart mysqld
创建 Maxwell 用户并授权
Maxwell 需要连接 MySQL,并读取 binlog 日志,因此建议创建一个专门的 MySQL 用户。
使用 MySQL 的 root 用户登录 MySQL 命令行(密码 123456):
mysql -u root -p
在 MySQL 命令行中执行:
SET GLOBAL validate_password.policy=LOW;
SET GLOBAL validate_password.length=6;
CREATE DATABASE IF NOT EXISTS maxwell;
CREATE USER 'maxwell'@'%' IDENTIFIED BY '123456';
CREATE USER 'maxwell'@'localhost' IDENTIFIED BY '123456';
GRANT ALL ON maxwell.* TO 'maxwell'@'%';
GRANT ALL ON maxwell.* TO 'maxwell'@'localhost';
GRANT SELECT, REPLICATION CLIENT, REPLICATION SLAVE ON *.* TO 'maxwell'@'%';
GRANT SELECT, REPLICATION CLIENT, REPLICATION SLAVE ON *.* TO 'maxwell'@'localhost';
FLUSH PRIVILEGES;
修改 Maxwell 配置文件
进入 Maxwell 安装目录:
cd /opt/maxwell-1.44.1
复制配置文件模板:
cp config.properties.example config.properties
编辑配置文件:
vim config.properties
更改或添加以下配置项(直接粘贴到配置文件或者取消注释后修改都行):
producer=kafka
kafka.bootstrap.servers=hadoop101:9092,hadoop102:9092,hadoop103:9092
host=hadoop101
port=3306
user=maxwell
password=123456
jdbc_options=useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
kafka_topic=topic_db
编写 Maxwell 集群管理脚本
前面说的单独使用 JDK 11 就写在启动脚本里面了。
创建启动脚本:
vim ~/bin/maxwell-start.sh
#!/bin/bash
host=$(hostname)
echo "========== 启动 ${host} Maxwell =========="
export JAVA_HOME=/opt/amazon-corretto-11
export PATH=$JAVA_HOME/bin:$PATH
MAXWELL_HOME=/opt/maxwell-1.44.1
PID=$(jps -l | grep 'com.zendesk.maxwell.Maxwell' | awk '{print $1}')
if [ -n "$PID" ]; then
echo "Maxwell 已运行,PID=$PID"
exit 0
fi
mkdir -p $MAXWELL_HOME/logs
nohup $MAXWELL_HOME/bin/maxwell \
--config $MAXWELL_HOME/config.properties \
> $MAXWELL_HOME/logs/maxwell.log 2>&1 &
sleep 3
PID=$(jps -l | grep 'com.zendesk.maxwell.Maxwell' | awk '{print $1}')
if [ -n "$PID" ]; then
echo "Maxwell 启动成功,PID=$PID"
else
echo "Maxwell 启动失败,请查看日志:$MAXWELL_HOME/logs/maxwell.log"
fi
创建停止脚本:
vim ~/bin/maxwell-stop.sh
#!/bin/bash
host=$(hostname)
echo "========== 停止 ${host} Maxwell =========="
export JAVA_HOME=/opt/amazon-corretto-11
export PATH=$JAVA_HOME/bin:$PATH
PID=$(jps -l | grep 'com.zendesk.maxwell.Maxwell' | awk '{print $1}')
if [ -z "$PID" ]; then
echo "Maxwell 未运行"
exit 0
fi
kill $PID
sleep 3
PID=$(jps -l | grep 'com.zendesk.maxwell.Maxwell' | awk '{print $1}')
if [ -z "$PID" ]; then
echo "Maxwell 停止成功"
else
kill -9 $PID
echo "Maxwell 已强制停止"
fi
创建状态检查脚本:
vim ~/bin/maxwell-status.sh
#!/bin/bash
host=$(hostname)
echo "========== 查看 ${host} Maxwell 状态 =========="
export JAVA_HOME=/opt/amazon-corretto-11
export PATH=$JAVA_HOME/bin:$PATH
PID=$(jps -l | grep 'com.zendesk.maxwell.Maxwell' | awk '{print $1}')
if [ -n "$PID" ]; then
echo "Maxwell 正在运行,PID=$PID"
else
echo "Maxwell 未运行"
fi
给脚本添加执行权限:
chmod +x ~/bin/maxwell-*.sh
6、全量表数据同步
同步目标
全量表指每天需要完整同步一份快照数据的业务表。
本项目中,全量表数据由 DataX 从 MySQL 业务库同步到 HDFS,后续由 Hive 外部表进行加载和分析。
全量同步的目标路径格式如下:/origin_data/edu/db/表名_full/日期。
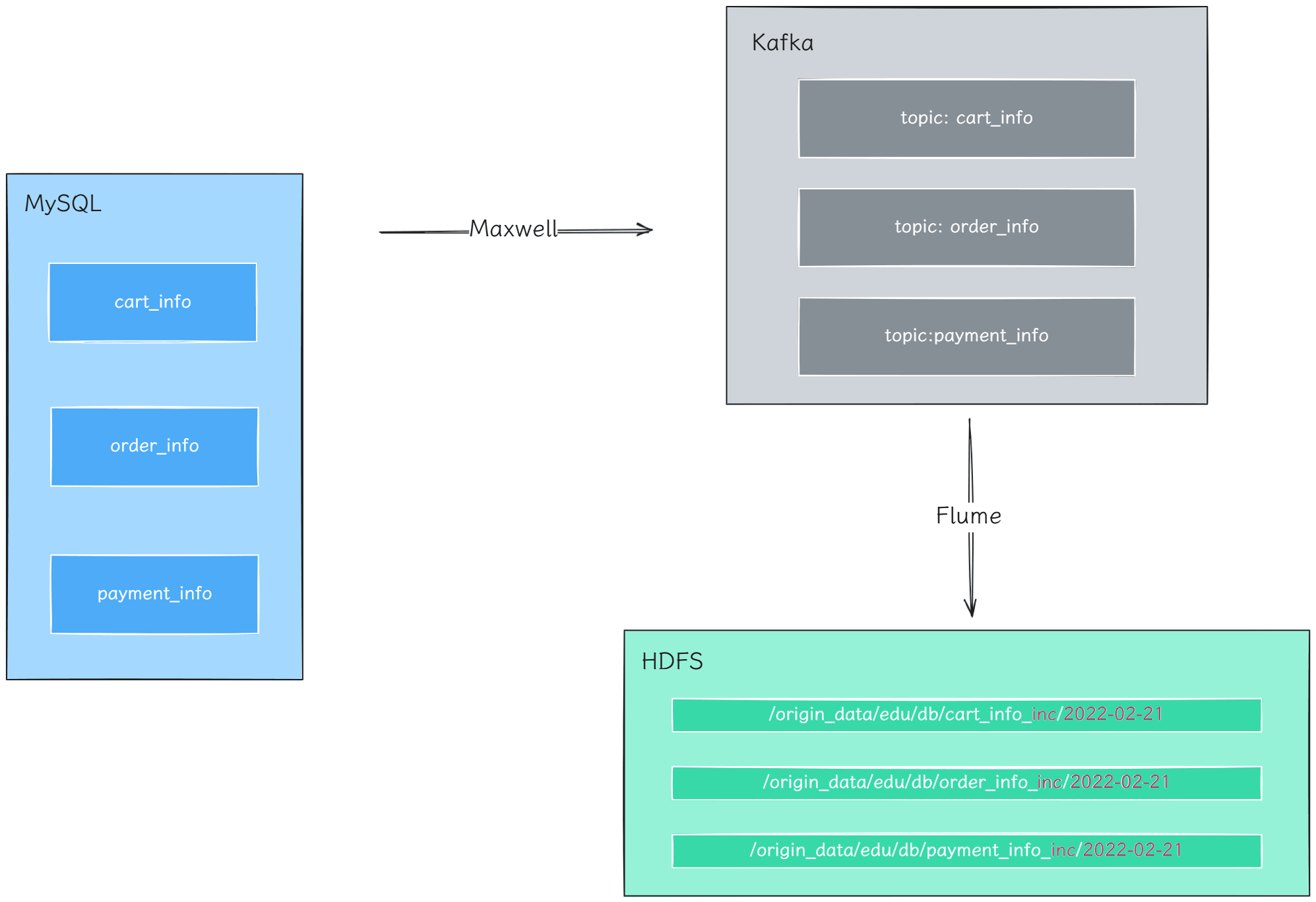
全量表数据同步链路如下:
- DataX 通过
mysqlreader读取 MySQL 表数据; - DataX 通过
hdfswriter将数据写入 HDFS; - HDFS 路径中包含日期分区,用于保存每日快照;
- 后续 Hive ODS 层基于该路径加载数据。
DataX 配置文件生成脚本
如果每张表都手写一个 DataX JSON 配置文件,工作量较大,而且容易出错。
因此这里编写一个 Python 脚本,根据 MySQL 的元数据信息自动生成 DataX 配置文件。
生成逻辑如下:
- 查询
information_schema.COLUMNS获取表字段; - 根据 MySQL 字段类型映射为 HDFSWriter 支持的字段类型;
- 自动拼接
mysqlreader和hdfswriter配置; - 将 JSON 配置文件写入指定目录
/opt/datax-202309/job/import。
安装 Python MySQL 驱动(原教程用的 Python 2 的驱动,我换成 Python 3 的了):
sudo yum install -y python3 python3-pip
python3 -m pip install PyMySQL
创建 gen_import_config.py 脚本:
vim ~/bin/gen_import_config.py
import json
import getopt
import os
import sys
import pymysql
# MySQL 相关配置
mysql_host = "hadoop101"
mysql_port = "3306"
mysql_user = "root"
mysql_passwd = "123456"
# HDFS NameNode 相关配置
hdfs_nn_host = "hadoop101"
hdfs_nn_port = "8020"
# DataX 配置文件输出目录
output_path = "/opt/datax-202309/job/import"
def get_connection():
return pymysql.connect(
host=mysql_host,
port=int(mysql_port),
user=mysql_user,
password=mysql_passwd,
charset="utf8"
)
def get_mysql_meta(database, table):
connection = get_connection()
cursor = connection.cursor()
sql = """
SELECT COLUMN_NAME, DATA_TYPE
FROM information_schema.COLUMNS
WHERE TABLE_SCHEMA = %s
AND TABLE_NAME = %s
ORDER BY ORDINAL_POSITION
"""
cursor.execute(sql, [database, table])
result = cursor.fetchall()
cursor.close()
connection.close()
return result
def get_mysql_columns(database, table):
return list(map(lambda x: x[0], get_mysql_meta(database, table)))
def get_hive_columns(database, table):
def type_mapping(mysql_type):
mappings = {
"bigint": "bigint",
"int": "bigint",
"integer": "bigint",
"smallint": "bigint",
"tinyint": "bigint",
"mediumint": "bigint",
"decimal": "string",
"numeric": "string",
"double": "double",
"float": "float",
"binary": "string",
"varbinary": "string",
"char": "string",
"varchar": "string",
"datetime": "string",
"time": "string",
"timestamp": "string",
"date": "string",
"text": "string",
"tinytext": "string",
"mediumtext": "string",
"longtext": "string",
"json": "string"
}
return mappings.get(mysql_type.lower(), "string")
meta = get_mysql_meta(database, table)
return list(
map(
lambda x: {
"name": x[0],
"type": type_mapping(x[1])
},
meta
)
)
def generate_json(source_database, source_table):
job = {
"job": {
"setting": {
"speed": {
"channel": 1
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": mysql_user,
"password": mysql_passwd,
"column": get_mysql_columns(source_database, source_table),
"splitPk": "",
"connection": [
{
"table": [
source_table
],
"jdbcUrl": [
"jdbc:mysql://{}:{}/{}?useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true".format(
mysql_host,
mysql_port,
source_database
)
]
}
]
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://{}:{}".format(
hdfs_nn_host,
hdfs_nn_port
),
"fileType": "text",
"path": "${targetdir}",
"fileName": source_table,
"column": get_hive_columns(source_database, source_table),
"writeMode": "append",
"fieldDelimiter": "\t",
"compress": "gzip"
}
}
}
]
}
}
if not os.path.exists(output_path):
os.makedirs(output_path)
file_name = "{}.{}.json".format(source_database, source_table)
file_path = os.path.join(output_path, file_name)
with open(file_path, "w", encoding="utf-8") as f:
json.dump(job, f, ensure_ascii=False, indent=4)
print("生成配置文件:{}".format(file_path))
def main(args):
source_database = ""
source_table = ""
options, arguments = getopt.getopt(
args,
"-d:-t:",
["sourcedb=", "sourcetbl="]
)
for opt_name, opt_value in options:
if opt_name in ("-d", "--sourcedb"):
source_database = opt_value
if opt_name in ("-t", "--sourcetbl"):
source_table = opt_value
if source_database == "" or source_table == "":
print("用法:python3 gen_import_config.py -d database -t table")
sys.exit(1)
generate_json(source_database, source_table)
if __name__ == "__main__":
main(sys.argv[1:])
脚本使用方式如下:
python3 ~/bin/gen_import_config.py -d 数据库名 -t 表名
例如生成 base_province 表的 DataX 配置文件:
python3 ~/bin/gen_import_config.py -d edu -t base_province
执行后会生成:/opt/datax-202309/job/import/edu.base_province.json。
批量生成全量表 DataX 配置文件
为了批量生成所有全量表的 DataX 配置文件,可以再封装一个 Shell 脚本。
创建脚本:
vim ~/bin/gen_import_config.sh
#!/bin/bash
python3 ~/bin/gen_import_config.py -d edu -t base_category_info
python3 ~/bin/gen_import_config.py -d edu -t base_source
python3 ~/bin/gen_import_config.py -d edu -t base_province
python3 ~/bin/gen_import_config.py -d edu -t base_subject_info
python3 ~/bin/gen_import_config.py -d edu -t cart_info
python3 ~/bin/gen_import_config.py -d edu -t chapter_info
python3 ~/bin/gen_import_config.py -d edu -t course_info
python3 ~/bin/gen_import_config.py -d edu -t knowledge_point
python3 ~/bin/gen_import_config.py -d edu -t test_paper
python3 ~/bin/gen_import_config.py -d edu -t test_paper_question
python3 ~/bin/gen_import_config.py -d edu -t test_point_question
python3 ~/bin/gen_import_config.py -d edu -t test_question_info
python3 ~/bin/gen_import_config.py -d edu -t user_chapter_process
python3 ~/bin/gen_import_config.py -d edu -t test_question_option
python3 ~/bin/gen_import_config.py -d edu -t video_info
添加执行权限:
chmod +x ~/bin/gen_import_config.sh
执行脚本:
gen_import_config.sh
[vaultattic@hadoop101 ~]$ gen_import_config.sh
生成配置文件:/opt/datax-202309/job/import/edu.base_category_info.json
生成配置文件:/opt/datax-202309/job/import/edu.base_source.json
生成配置文件:/opt/datax-202309/job/import/edu.base_province.json
生成配置文件:/opt/datax-202309/job/import/edu.base_subject_info.json
生成配置文件:/opt/datax-202309/job/import/edu.cart_info.json
生成配置文件:/opt/datax-202309/job/import/edu.chapter_info.json
生成配置文件:/opt/datax-202309/job/import/edu.course_info.json
生成配置文件:/opt/datax-202309/job/import/edu.knowledge_point.json
生成配置文件:/opt/datax-202309/job/import/edu.test_paper.json
生成配置文件:/opt/datax-202309/job/import/edu.test_paper_question.json
生成配置文件:/opt/datax-202309/job/import/edu.test_point_question.json
生成配置文件:/opt/datax-202309/job/import/edu.test_question_info.json
生成配置文件:/opt/datax-202309/job/import/edu.user_chapter_process.json
生成配置文件:/opt/datax-202309/job/import/edu.test_question_option.json
生成配置文件:/opt/datax-202309/job/import/edu.video_info.json
[vaultattic@hadoop101 ~]$
查看生成结果:
ll /opt/datax-202309/job/import/
[vaultattic@hadoop101 ~]$ ll /opt/datax-202309/job/import/
总计 60
-rw-r--r--. 1 vaultattic vaultattic 1618 6月10日 13:45 edu.base_category_info.json
-rw-r--r--. 1 vaultattic vaultattic 1608 6月10日 13:45 edu.base_province.json
-rw-r--r--. 1 vaultattic vaultattic 1604 6月10日 13:45 edu.base_source.json
-rw-r--r--. 1 vaultattic vaultattic 1616 6月10日 13:45 edu.base_subject_info.json
-rw-r--r--. 1 vaultattic vaultattic 1600 6月10日 13:45 edu.cart_info.json
-rw-r--r--. 1 vaultattic vaultattic 1606 6月10日 13:45 edu.chapter_info.json
-rw-r--r--. 1 vaultattic vaultattic 1604 6月10日 13:45 edu.course_info.json
-rw-r--r--. 1 vaultattic vaultattic 1612 6月10日 13:45 edu.knowledge_point.json
-rw-r--r--. 1 vaultattic vaultattic 1602 6月10日 13:45 edu.test_paper.json
-rw-r--r--. 1 vaultattic vaultattic 1620 6月10日 13:45 edu.test_paper_question.json
-rw-r--r--. 1 vaultattic vaultattic 1620 6月10日 13:45 edu.test_point_question.json
-rw-r--r--. 1 vaultattic vaultattic 1618 6月10日 13:45 edu.test_question_info.json
-rw-r--r--. 1 vaultattic vaultattic 1622 6月10日 13:45 edu.test_question_option.json
-rw-r--r--. 1 vaultattic vaultattic 1622 6月10日 13:45 edu.user_chapter_process.json
-rw-r--r--. 1 vaultattic vaultattic 1602 6月10日 13:45 edu.video_info.json
[vaultattic@hadoop101 ~]$
以 base_province 表为例,测试生成的 DataX 配置文件是否可用。
DataX 的 HDFSWriter 要求目标路径提前存在,因此需要先用以下命令创建目录:
hadoop fs -mkdir -p /origin_data/edu/db/base_province_full/2022-02-21
执行 DataX 同步任务:
python /opt/datax-202309/bin/datax.py \
-p"-Dtargetdir=/origin_data/edu/db/base_province_full/2022-02-21" \
/opt/datax-202309/job/import/edu.base_province.json
[vaultattic@hadoop101 ~]$ python /opt/datax-202309/bin/datax.py \
-p"-Dtargetdir=/origin_data/edu/db/base_province_full/2022-02-21" \
/opt/datax-202309/job/import/edu.base_province.json
......
2026-06-10 15:33:46.216 [job-0] INFO JobContainer -
任务启动时刻 : 2026-06-10 15:33:33
任务结束时刻 : 2026-06-10 15:33:46
任务总计耗时 : 13s
任务平均流量 : 70B/s
记录写入速度 : 3rec/s
读出记录总数 : 34
读写失败总数 : 0
[vaultattic@hadoop101 ~]$
查看同步结果:
hadoop fs -ls /origin_data/edu/db/base_province_full/2022-02-21
[vaultattic@hadoop101 ~]$ hadoop fs -ls /origin_data/edu/db/base_province_full/2022-02-21
Found 1 items
-rw-r--r-- 3 vaultattic supergroup 563 2026-06-10 15:33 /origin_data/edu/db/base_province_full/2022-02-21/base_province__57efe611_b1fa_4d08_9ade_df1b9f7734eb.gz
[vaultattic@hadoop101 ~]$
如果目录下出现 .gz 文件,说明同步成功。
全量表数据同步脚本
为了方便后续使用,可以封装一个全量表同步脚本。
创建 mysql_to_hdfs_full.sh 脚本:
vim ~/bin/mysql_to_hdfs_full.sh
#!/bin/bash
DATAX_HOME=/opt/datax-202309
DATAX_JOB=$DATAX_HOME/job
handle_targetdir() {
hadoop fs -rm -r -f "$1" >/dev/null 2>&1
hadoop fs -mkdir -p "$1"
}
import_data() {
local datax_config=$1
local target_dir=$2
handle_targetdir "$target_dir"
echo "========== 开始同步:$datax_config =========="
echo "目标路径:$target_dir"
python "$DATAX_HOME/bin/datax.py" \
-p"-Dtargetdir=$target_dir" \
"$datax_config" >/tmp/datax_run.log 2>&1
if [ $? -ne 0 ]; then
echo "同步失败,日志如下:"
cat /tmp/datax_run.log
rm -f /tmp/datax_run.log
exit 1
else
echo "同步成功:$target_dir"
fi
rm -f /tmp/datax_run.log
}
if [ $# -ne 2 ]; then
echo "用法:mysql_to_hdfs_full.sh {表名|all} 日期"
echo "示例:mysql_to_hdfs_full.sh base_province 2022-02-21"
echo "示例:mysql_to_hdfs_full.sh all 2022-02-21"
exit 1
fi
tab=$1
do_date=$2
case $tab in
base_category_info|base_source|base_province|base_subject_info|cart_info|chapter_info|course_info|knowledge_point|test_paper|test_paper_question|test_point_question|test_question_info|user_chapter_process|test_question_option|video_info)
import_data "$DATAX_JOB/import/edu.${tab}.json" "/origin_data/edu/db/${tab}_full/$do_date"
;;
all)
for tmp in base_category_info base_source base_province base_subject_info cart_info chapter_info course_info knowledge_point test_paper test_paper_question test_point_question test_question_info user_chapter_process test_question_option video_info
do
import_data "$DATAX_JOB/import/edu.${tmp}.json" "/origin_data/edu/db/${tmp}_full/$do_date"
done
;;
*)
echo "参数错误:$tab"
echo "用法:mysql_to_hdfs_full.sh {表名|all} 日期"
echo "示例:mysql_to_hdfs_full.sh base_province 2022-02-21"
echo "示例:mysql_to_hdfs_full.sh all 2022-02-21"
exit 1
;;
esac
添加执行权限:
chmod +x ~/bin/mysql_to_hdfs_full.sh
用法:
mysql_to_hdfs_full.sh {表名|all} 日期
同步所有表查看脚本是否可用:
mysql_to_hdfs_full.sh all 2022-02-21
[vaultattic@hadoop101 ~]$ mysql_to_hdfs_full.sh all 2022-02-21
========== 开始同步:/opt/datax-202309/job/import/edu.base_category_info.json ==========
目标路径:/origin_data/edu/db/base_category_info_full/2022-02-21
同步成功:/origin_data/edu/db/base_category_info_full/2022-02-21
========== 开始同步:/opt/datax-202309/job/import/edu.base_source.json ==========
目标路径:/origin_data/edu/db/base_source_full/2022-02-21
同步成功:/origin_data/edu/db/base_source_full/2022-02-21
========== 开始同步:/opt/datax-202309/job/import/edu.base_province.json ==========
目标路径:/origin_data/edu/db/base_province_full/2022-02-21
同步成功:/origin_data/edu/db/base_province_full/2022-02-21
========== 开始同步:/opt/datax-202309/job/import/edu.base_subject_info.json ==========
目标路径:/origin_data/edu/db/base_subject_info_full/2022-02-21
同步成功:/origin_data/edu/db/base_subject_info_full/2022-02-21
========== 开始同步:/opt/datax-202309/job/import/edu.cart_info.json ==========
目标路径:/origin_data/edu/db/cart_info_full/2022-02-21
同步成功:/origin_data/edu/db/cart_info_full/2022-02-21
========== 开始同步:/opt/datax-202309/job/import/edu.chapter_info.json ==========
目标路径:/origin_data/edu/db/chapter_info_full/2022-02-21
同步成功:/origin_data/edu/db/chapter_info_full/2022-02-21
========== 开始同步:/opt/datax-202309/job/import/edu.course_info.json ==========
目标路径:/origin_data/edu/db/course_info_full/2022-02-21
同步成功:/origin_data/edu/db/course_info_full/2022-02-21
========== 开始同步:/opt/datax-202309/job/import/edu.knowledge_point.json ==========
目标路径:/origin_data/edu/db/knowledge_point_full/2022-02-21
同步成功:/origin_data/edu/db/knowledge_point_full/2022-02-21
========== 开始同步:/opt/datax-202309/job/import/edu.test_paper.json ==========
目标路径:/origin_data/edu/db/test_paper_full/2022-02-21
同步成功:/origin_data/edu/db/test_paper_full/2022-02-21
========== 开始同步:/opt/datax-202309/job/import/edu.test_paper_question.json ==========
目标路径:/origin_data/edu/db/test_paper_question_full/2022-02-21
同步成功:/origin_data/edu/db/test_paper_question_full/2022-02-21
========== 开始同步:/opt/datax-202309/job/import/edu.test_point_question.json ==========
目标路径:/origin_data/edu/db/test_point_question_full/2022-02-21
同步成功:/origin_data/edu/db/test_point_question_full/2022-02-21
========== 开始同步:/opt/datax-202309/job/import/edu.test_question_info.json ==========
目标路径:/origin_data/edu/db/test_question_info_full/2022-02-21
同步成功:/origin_data/edu/db/test_question_info_full/2022-02-21
========== 开始同步:/opt/datax-202309/job/import/edu.user_chapter_process.json ==========
目标路径:/origin_data/edu/db/user_chapter_process_full/2022-02-21
同步成功:/origin_data/edu/db/user_chapter_process_full/2022-02-21
========== 开始同步:/opt/datax-202309/job/import/edu.test_question_option.json ==========
目标路径:/origin_data/edu/db/test_question_option_full/2022-02-21
同步成功:/origin_data/edu/db/test_question_option_full/2022-02-21
========== 开始同步:/opt/datax-202309/job/import/edu.video_info.json ==========
目标路径:/origin_data/edu/db/video_info_full/2022-02-21
同步成功:/origin_data/edu/db/video_info_full/2022-02-21
[vaultattic@hadoop101 ~]$
检查全量表同步结果:
hadoop fs -ls /origin_data/edu/db
[vaultattic@hadoop101 ~]$ hadoop fs -ls /origin_data/edu/db
Found 15 items
drwxr-xr-x - vaultattic supergroup 0 2026-06-10 15:50 /origin_data/edu/db/base_category_info_full
drwxr-xr-x - vaultattic supergroup 0 2026-06-10 15:50 /origin_data/edu/db/base_province_full
drwxr-xr-x - vaultattic supergroup 0 2026-06-10 15:50 /origin_data/edu/db/base_source_full
drwxr-xr-x - vaultattic supergroup 0 2026-06-10 15:50 /origin_data/edu/db/base_subject_info_full
drwxr-xr-x - vaultattic supergroup 0 2026-06-10 15:51 /origin_data/edu/db/cart_info_full
drwxr-xr-x - vaultattic supergroup 0 2026-06-10 15:51 /origin_data/edu/db/chapter_info_full
drwxr-xr-x - vaultattic supergroup 0 2026-06-10 15:51 /origin_data/edu/db/course_info_full
drwxr-xr-x - vaultattic supergroup 0 2026-06-10 15:51 /origin_data/edu/db/knowledge_point_full
drwxr-xr-x - vaultattic supergroup 0 2026-06-10 15:52 /origin_data/edu/db/test_paper_full
drwxr-xr-x - vaultattic supergroup 0 2026-06-10 15:52 /origin_data/edu/db/test_paper_question_full
drwxr-xr-x - vaultattic supergroup 0 2026-06-10 15:52 /origin_data/edu/db/test_point_question_full
drwxr-xr-x - vaultattic supergroup 0 2026-06-10 15:52 /origin_data/edu/db/test_question_info_full
drwxr-xr-x - vaultattic supergroup 0 2026-06-10 15:53 /origin_data/edu/db/test_question_option_full
drwxr-xr-x - vaultattic supergroup 0 2026-06-10 15:53 /origin_data/edu/db/user_chapter_process_full
drwxr-xr-x - vaultattic supergroup 0 2026-06-10 15:53 /origin_data/edu/db/video_info_full
[vaultattic@hadoop101 ~]$
7、增量表数据同步
同步目标
增量表是指业务系统中会持续发生新增、修改、删除的数据表。
这里使用 Maxwell 监听 MySQL 的 binlog,将业务表的变更数据实时写入 Kafka,再由 Flume 消费 Kafka 数据并写入 HDFS。
增量同步的目标路径格式如下:/origin_data/edu/db/表名_inc/日期。
本项目中,增量表同步链路如下:
- MySQL 开启 binlog;
- Maxwell 监听 MySQL binlog;
- Maxwell 将数据变更写入 Kafka 的
topic_db; - Flume 从 Kafka 读取数据;
- Flume 自定义拦截器提取
table和ts; - Flume 写入 HDFS 的对应增量目录。
创建 Kafka 业务数据 Topic
创建一个名为 topic_db 的 Topic:
kafka-topics.sh \
--bootstrap-server hadoop101:9092,hadoop102:9092,hadoop103:9092 \
--create \
--topic topic_db \
--partitions 3 \
--replication-factor 3
查看 Topic 信息:
kafka-topics.sh \
--bootstrap-server hadoop101:9092,hadoop102:9092,hadoop103:9092 \
--describe \
--topic topic_db
[vaultattic@hadoop101 ~]$ kafka-topics.sh \
--bootstrap-server hadoop101:9092,hadoop102:9092,hadoop103:9092 \
--describe \
--topic topic_db
Topic: topic_db TopicId: 74LB_CQnS_G8t9ngr1ZWlQ PartitionCount: 3 ReplicationFactor: 3 Configs:
Topic: topic_db Partition: 0 Leader: 1 Replicas: 1,2,3 Isr: 1,2,3 Elr: N/A LastKnownElr: N/A
Topic: topic_db Partition: 1 Leader: 2 Replicas: 2,3,1 Isr: 2,3,1 Elr: N/A LastKnownElr: N/A
Topic: topic_db Partition: 2 Leader: 3 Replicas: 3,1,2 Isr: 3,1,2 Elr: N/A LastKnownElr: N/A
[vaultattic@hadoop101 ~]$
Maxwell 通道测试
Maxwell 配置文件就用之前安装时候就改好了,现在使用 Maxwell 启动脚本启动测试一下。
[vaultattic@hadoop101 ~]$ maxwell-start.sh
========== 启动 hadoop101 Maxwell ==========
Maxwell 启动成功,PID=88153
[vaultattic@hadoop101 ~]$
再新建一个终端,启动一个 Kafka 消费者消费 kafka_db 用来查看输出。
kafka-console-consumer.sh \
--bootstrap-server hadoop101:9092,hadoop102:9092,hadoop103:9092 \
--topic topic_db
再新建一个终端,使用 mock.sh 生成一天的模拟数据:
mock.sh 2022-02-21
这里我卡了好久不知道是什么问题,Maxwell 一直捕获不到 MySQL 的更新,重启后将教程里面的
/etc/my.cnf文件配置中的server-id=1字段改为了server_id=1就跑通了,不确定是环境出了一点问题还是字段写错了的问题,没有精力复现了😥。
如果刚刚运行的 Kafka 消费者终端输出 JSON 内容就说明跑通了。
Flume 配置
业务数据 Flume 运行在 hadoop103,负责从 Kafka 消费 topic_db 数据并写入 HDFS。
业务增量数据链路如下:
Flume 需要从 Maxwell JSON 中获取:
table字段:用于生成表名目录ts字段:用于生成日期目录
HDFS 路径格式为:
/origin_data/edu/db/%{tableName}_inc/%Y-%m-%d
%{tableName}来自 Flume Header 中的tableName%Y-%m-%d来自 Flume Header 中的timestamp
原教程中使用的是魔改版的 Maxwell,而原版 Maxwell 输出 JSON 中的
ts字段表示数据实际发生变更的时间。因此,Flume 写入 HDFS 时生成的日期目录,不是模拟数据中的业务日期,而是当前数据写入 MySQL 的日期。例如执行mock.sh 2022-02-21后,HDFS 目录不是2022-02-21,而是实际执行当天的日期比如2026-6-12。
新增业务数据拦截器:
打开之前的 Maven 项目,在 cn.vaultattic.flume.interceptor 包中新建一个 TimestampAndTableNameInterceptor 类,代码如下:
package cn.vaultattic.flume.interceptor;
import com.alibaba.fastjson.JSONObject;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.nio.charset.StandardCharsets;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
public class TimestampAndTableNameInterceptor implements Interceptor {
@Override
public void initialize() {
// 当前没有需要初始化的资源
}
@Override
public Event intercept(Event event) {
// 获取 Event Header
Map<String, String> headers = event.getHeaders();
// 获取 Event Body
String body = new String(event.getBody(), StandardCharsets.UTF_8);
try {
// 解析 Maxwell 输出的 JSON 字符串
JSONObject jsonObject = JSONObject.parseObject(body);
// 获取 Maxwell 输出的 ts 字段
Long ts = jsonObject.getLong("ts");
// 获取 Maxwell 输出的 table 字段
String tableName = jsonObject.getString("table");
// ts 或 table 为空时,丢弃该条数据
if (ts == null || tableName == null || tableName.length() == 0) {
return null;
}
// Maxwell 的 ts 是秒级时间戳,Flume HDFS Sink 需要毫秒级时间戳
headers.put("timestamp", String.valueOf(ts * 1000));
// 写入表名,用于 HDFS 路径中的 %{tableName}
headers.put("tableName", tableName);
return event;
} catch (Exception e) {
// JSON 解析失败时,丢弃该条数据
return null;
}
}
@Override
public List<Event> intercept(List<Event> events) {
// 使用迭代器删除无效 Event
Iterator<Event> iterator = events.iterator();
while (iterator.hasNext()) {
Event event = iterator.next();
if (intercept(event) == null) {
iterator.remove();
}
}
return events;
}
@Override
public void close() {
// 当前没有需要释放的资源
}
public static class Builder implements Interceptor.Builder {
@Override
public Interceptor build() {
// 返回当前拦截器实例
return new TimestampAndTableNameInterceptor();
}
@Override
public void configure(Context context) {
// 当前没有额外配置项
}
}
}
重新打包为 .jar 文件。
将 .jar 包上传到 hadoop101 的 ~/ansible/files。
使用之前的 distribute_file.yml,将 Jar 包分发到各节点的依赖目录中。
运行 deploy_package.yml:
ansible-playbook distribute_file.yml
业务增量 Flume 使用单独的 File Channel 目录,避免和前文用户行为日志消费链路冲突。
在 hadoop103 创建目录:
mkdir -p /opt/flume-1.11.0/file_channel_db/checkpoint /opt/flume-1.11.0/file_channel_db/data
在 hadoop103 创建 Flume 配置文件:
vim /opt/flume-1.11.0/job/kafka-to-hdfs-db.conf
# agent 中包含一个 source、一个 channel 和一个 sink
a1.sources = r1
a1.channels = c1
a1.sinks = k1
# 使用 Kafka Source 消费 topic_db
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
# Kafka Broker 地址
a1.sources.r1.kafka.bootstrap.servers = hadoop101:9092,hadoop102:9092,hadoop103:9092
# 订阅业务数据 Topic
a1.sources.r1.kafka.topics = topic_db
# 消费者组 ID
a1.sources.r1.kafka.consumer.group.id = flume_db_group
# 每批拉取的最大事件数
a1.sources.r1.batchSize = 5000
# 每批最大等待时间
a1.sources.r1.batchDurationMillis = 2000
# 没有历史 offset 时,从最新位置开始消费
a1.sources.r1.kafka.consumer.auto.offset.reset = latest
# 使用业务数据拦截器提取 ts 和 table 字段
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = cn.vaultattic.flume.interceptor.TimestampAndTableNameInterceptor$Builder
# 使用 File Channel,提高可靠性
a1.channels.c1.type = file
# File Channel checkpoint 目录
a1.channels.c1.checkpointDir = /opt/flume-1.11.0/file_channel_db/checkpoint
# File Channel 数据目录
a1.channels.c1.dataDirs = /opt/flume-1.11.0/file_channel_db/data
# Channel 容量
a1.channels.c1.capacity = 1000000
# 单次事务处理数量
a1.channels.c1.transactionCapacity = 10000
# keep-alive 时间
a1.channels.c1.keep-alive = 6
# 使用 HDFS Sink 写入 HDFS
a1.sinks.k1.type = hdfs
# HDFS 输出路径,按表名和日期分区
a1.sinks.k1.hdfs.path = /origin_data/edu/db/%{tableName}_inc/%Y-%m-%d
# HDFS 文件名前缀
a1.sinks.k1.hdfs.filePrefix = db
# HDFS 文件后缀
a1.sinks.k1.hdfs.fileSuffix = .gz
# 使用 Event Header 中的 timestamp 作为分区时间
a1.sinks.k1.hdfs.useLocalTimeStamp = false
# 不开启时间取整
a1.sinks.k1.hdfs.round = false
# 文件滚动时间,单位秒
a1.sinks.k1.hdfs.rollInterval = 10
# 文件滚动大小,单位字节
a1.sinks.k1.hdfs.rollSize = 134217728
# 文件滚动条数,0 表示不按条数滚动
a1.sinks.k1.hdfs.rollCount = 0
# 每批写入 HDFS 的事件数
a1.sinks.k1.hdfs.batchSize = 5000
# 使用压缩流写入
a1.sinks.k1.hdfs.fileType = CompressedStream
# 使用 gzip 压缩
a1.sinks.k1.hdfs.codeC = gzip
# 写入文本格式
a1.sinks.k1.hdfs.writeFormat = Text
# 空闲文件关闭时间
a1.sinks.k1.hdfs.idleTimeout = 120
# 正在写入文件的临时前缀
a1.sinks.k1.hdfs.inUsePrefix = .
# 正在写入文件的临时后缀
a1.sinks.k1.hdfs.inUseSuffix = .tmp
# 绑定 source、channel、sink
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
业务增量 Flume 单独使用一个脚本管理,避免和前面的用户行为日志采集 Flume 混在一起。
在 hadoop101 创建:
vim ~/bin/flume-db.sh
#!/usr/bin/env bash
set -euo pipefail
FLUME_HOME="/opt/flume-1.11.0"
FLUME_CONF="${FLUME_HOME}/job/kafka-to-hdfs-db.conf"
AGENT_NAME="a1"
LOG_FILE="${FLUME_HOME}/logs/flume-db.out"
PID_FILE="${FLUME_HOME}/logs/flume-db.pid"
HOSTS=(
"hadoop103"
)
start() {
for host in "${HOSTS[@]}"; do
echo "========== 启动 ${host} 业务数据 Flume =========="
ssh "$host" "
if [ -f '${PID_FILE}' ]; then
pid=\$(cat '${PID_FILE}' 2>/dev/null || true)
if [ -n \"\$pid\" ] && kill -0 \"\$pid\" 2>/dev/null; then
echo '${host} 业务数据 Flume 已在运行'
exit 0
fi
fi
mkdir -p '${FLUME_HOME}/logs'
nohup '${FLUME_HOME}/bin/flume-ng' agent \
--conf '${FLUME_HOME}/conf' \
--conf-file '${FLUME_CONF}' \
--name '${AGENT_NAME}' \
-Dflume.root.logger=INFO,console \
> '${LOG_FILE}' 2>&1 < /dev/null &
echo \$! > '${PID_FILE}'
"
sleep 3
if ssh "$host" "
pid=\$(cat '${PID_FILE}' 2>/dev/null || true)
[ -n \"\$pid\" ] && kill -0 \"\$pid\" 2>/dev/null
"; then
echo "${host} 业务数据 Flume 启动成功"
else
echo "${host} 业务数据 Flume 启动失败,请查看日志:${LOG_FILE}"
fi
done
}
stop() {
for host in "${HOSTS[@]}"; do
echo "========== 停止 ${host} 业务数据 Flume =========="
ssh "$host" "
if [ -f '${PID_FILE}' ]; then
pid=\$(cat '${PID_FILE}' 2>/dev/null || true)
if [ -n \"\$pid\" ] && kill -0 \"\$pid\" 2>/dev/null; then
kill \"\$pid\"
sleep 2
fi
if [ -n \"\$pid\" ] && kill -0 \"\$pid\" 2>/dev/null; then
kill -9 \"\$pid\" 2>/dev/null || true
fi
rm -f '${PID_FILE}'
echo '${host} 业务数据 Flume 停止完成'
else
echo '${host} 业务数据 Flume 未运行'
fi
"
done
}
status() {
for host in "${HOSTS[@]}"; do
echo "========== 查看 ${host} 业务数据 Flume =========="
ssh "$host" "
if [ -f '${PID_FILE}' ]; then
pid=\$(cat '${PID_FILE}' 2>/dev/null || true)
if [ -n \"\$pid\" ] && kill -0 \"\$pid\" 2>/dev/null; then
echo '${host} 业务数据 Flume 运行中'
else
echo '${host} 业务数据 Flume 未运行'
fi
else
echo '${host} 业务数据 Flume 未运行'
fi
"
done
}
case "${1:-}" in
start)
start
;;
stop)
stop
;;
restart)
stop
sleep 3
start
;;
status)
status
;;
*)
echo "用法: $0 {start|stop|restart|status}"
exit 1
;;
esac
增加权限:
chmod +x ~/bin/flume-db.sh
启动:
flume-db.sh start
查看状态:
flume-db.sh status
停止:
flume-db.sh stop
重启:
flume-db.sh restart
Flume 通道测试
生成模拟业务数据:
mock.sh 2022-02-21
查看 HDFS 是否写入 Maxwell 生成的 JSON 数据:
hadoop fs -text /origin_data/edu/db/order_info_inc/*/db*.gz | head
[vaultattic@hadoop101 ansible]$ hadoop fs -text /origin_data/edu/db/order_info_inc/*/db*.gz | head
{"database":"edu","table":"order_info","type":"insert","ts":1781269716,"xid":59384,"commit":true,"data":{"id":21786,"user_id":235,"origin_amount":200.00,"coupon_reduce":0.00,"final_amount":200.00,"order_status":"1001","out_trade_no":"437716997615379","trade_body":"MyBatis等1件商品","session_id":"976ff4ab-c6e7-4064-bf6f-f62b13d739f8","province_id":7,"create_time":"2022-02-21 20:02:38","expire_time":"2022-02-21 20:17:38","update_time":null}}
{"database":"edu","table":"order_info","type":"insert","ts":1781269716,"xid":59412,"commit":true,"data":{"id":21787,"user_id":139,"origin_amount":200.00,"coupon_reduce":0.00,"final_amount":200.00,"order_status":"1001","out_trade_no":"844262756327171","trade_body":"RabbitMQ消息中间件等1件商品","session_id":"0d332629-d848-4712-86ac-115011fb18cf","province_id":32,"create_time":"2022-02-21 21:21:26","expire_time":"2022-02-21 21:36:26","update_time":null}}
{"database":"edu","table":"order_info","type":"insert","ts":1781269716,"xid":59436,"commit":true,"data":{"id":21788,"user_id":340,"origin_amount":200.00,"coupon_reduce":0.00,"final_amount":200.00,"order_status":"1001","out_trade_no":"125574159976478","trade_body":"尚硅谷_Linux系统管理教程(Linux运维+云计算学科发布)等1件商品","session_id":"692f56ef-01c7-4ff7-8656-fd93b58d0654","province_id":18,"create_time":"2022-02-21 13:52:35","expire_time":"2022-02-21 14:07:35","update_time":null}}
{"database":"edu","table":"order_info","type":"insert","ts":1781269716,"xid":59492,"commit":true,"data":{"id":21789,"user_id":212,"origin_amount":200.00,"coupon_reduce":0.00,"final_amount":200.00,"order_status":"1001","out_trade_no":"635887645543553","trade_body":"RabbitMQ消息中间件等1件商品","session_id":"8cc553ae-8092-4e8c-9c5f-03c6015e1a8b","province_id":33,"create_time":"2022-02-21 17:17:55","expire_time":"2022-02-21 17:32:55","update_time":null}}
{"database":"edu","table":"order_info","type":"update","ts":1781269716,"xid":59526,"commit":true,"data":{"id":21789,"user_id":212,"origin_amount":200.00,"coupon_reduce":0.00,"final_amount":200.00,"order_status":"1003","out_trade_no":"635887645543553","trade_body":"RabbitMQ消息中间件等1件商品","session_id":"8cc553ae-8092-4e8c-9c5f-03c6015e1a8b","province_id":33,"create_time":"2022-02-21 17:17:55","expire_time":"2022-02-21 17:32:55","update_time":"2022-02-21 17:32:55"},"old":{"order_status":"1001","update_time":null}}
{"database":"edu","table":"order_info","type":"insert","ts":1781269716,"xid":59650,"commit":true,"data":{"id":21791,"user_id":150,"origin_amount":200.00,"coupon_reduce":0.00,"final_amount":200.00,"order_status":"1001","out_trade_no":"314556962332941","trade_body":"SpringMVC等1件商品","session_id":"255146a9-03dd-4e92-afe4-5a5d5f68b5ea","province_id":21,"create_time":"2022-02-21 18:43:43","expire_time":"2022-02-21 18:58:43","update_time":null}}
{"database":"edu","table":"order_info","type":"insert","ts":1781269716,"xid":59647,"commit":true,"data":{"id":21790,"user_id":478,"origin_amount":200.00,"coupon_reduce":0.00,"final_amount":200.00,"order_status":"1001","out_trade_no":"656755863954573","trade_body":"Android与H5互调等1件商品","session_id":"227d7721-8243-4a5a-877f-62f2e0f88cf5","province_id":23,"create_time":"2022-02-21 16:12:31","expire_time":"2022-02-21 16:27:31","update_time":null}}
{"database":"edu","table":"order_info","type":"insert","ts":1781269716,"xid":59695,"commit":true,"data":{"id":21792,"user_id":477,"origin_amount":200.00,"coupon_reduce":0.00,"final_amount":200.00,"order_status":"1001","out_trade_no":"658767236614391","trade_body":"尚硅谷大数据技术之HBase等1件商品","session_id":"962dc5db-f30f-4c6d-8373-98c3f3acc811","province_id":19,"create_time":"2022-02-21 14:23:19","expire_time":"2022-02-21 14:38:19","update_time":null}}
{"database":"edu","table":"order_info","type":"update","ts":1781269716,"xid":59671,"commit":true,"data":{"id":21786,"user_id":235,"origin_amount":200.00,"coupon_reduce":0.00,"final_amount":200.00,"order_status":"1002","out_trade_no":"437716997615379","trade_body":"MyBatis等1件商品","session_id":"976ff4ab-c6e7-4064-bf6f-f62b13d739f8","province_id":7,"create_time":"2022-02-21 20:02:38","expire_time":"2022-02-21 20:17:38","update_time":"2022-02-21 20:02:54"},"old":{"order_status":"1001","update_time":null}}
{"database":"edu","table":"order_info","type":"insert","ts":1781269716,"xid":59712,"commit":true,"data":{"id":21793,"user_id":1,"origin_amount":200.00,"coupon_reduce":0.00,"final_amount":200.00,"order_status":"1001","out_trade_no":"913737331653931","trade_body":"ES6教程-涵盖ES6-ES11等1件商品","session_id":"f54047d0-9522-484c-915b-a7ae8074e6c2","province_id":15,"create_time":"2022-02-21 22:57:00","expire_time":"2022-02-21 23:12:00","update_time":null}}
text: Unable to write to output stream.
text: Unable to write to output stream.
[vaultattic@hadoop101 ansible]$
如果输出的是 JSON 数据就说明跑通了。
增量表首日全量同步
Maxwell 是通过监听 MySQL binlog 来采集增量数据的。
因此,Maxwell 启动之后发生的 insert、update、delete 操作可以被采集到,但如果某些数据在 Maxwell 启动之前就已经存在,这部分历史数据不会自动进入 Kafka。
所以对于增量表,一般需要在首日先进行一次初始化同步,将当前表中的历史数据同步到 Kafka。后续再由 Maxwell 实时监听 binlog,持续采集新增和变更数据。
这个首日初始化过程可以使用 Maxwell 提供的 maxwell-bootstrap 工具完成。
编写首日初始化脚本:
vim ~/bin/mysql_to_kafka_inc_init.sh
#!/bin/bash
export JAVA_HOME=/opt/amazon-corretto-11
export PATH=$JAVA_HOME/bin:$PATH
MAXWELL_HOME=/opt/maxwell-1.44.1
import_data() {
$MAXWELL_HOME/bin/maxwell-bootstrap \
--database edu \
--table "$1" \
--config $MAXWELL_HOME/config.properties
}
for table in cart_info comment_info favor_info order_detail order_info payment_info review_info test_exam test_exam_question user_info vip_change_detail
do
echo "========== 初始化增量表:${table} =========="
import_data "$table"
done
添加执行权限:
chmod +x ~/bin/mysql_to_kafka_inc_init.sh
如果之前测试过增量同步,为了方便观察结果,可以先删除 HDFS 上已有的增量表目录。
删除所有 _inc 目录:
hadoop fs -rm -r -f /origin_data/edu/db/*_inc
[vaultattic@hadoop101 ansible]$ hadoop fs -rm -r -f /origin_data/edu/db/*_inc
Deleted /origin_data/edu/db/cart_info_inc
Deleted /origin_data/edu/db/comment_info_inc
Deleted /origin_data/edu/db/favor_info_inc
Deleted /origin_data/edu/db/order_detail_inc
Deleted /origin_data/edu/db/order_info_inc
Deleted /origin_data/edu/db/payment_info_inc
Deleted /origin_data/edu/db/review_info_inc
Deleted /origin_data/edu/db/test_exam_inc
Deleted /origin_data/edu/db/test_exam_question_inc
Deleted /origin_data/edu/db/user_chapter_process_inc
Deleted /origin_data/edu/db/user_info_inc
Deleted /origin_data/edu/db/vip_change_detail_inc
[vaultattic@hadoop101 ansible]$
再运行全量同步脚本:
mysql_to_kafka_inc_init.sh
[vaultattic@hadoop101 ansible]$ mysql_to_kafka_inc_init.sh
========== 初始化增量表:cart_info ==========
connecting to jdbc:mysql://hadoop101:3306/maxwell?allowPublicKeyRetrieval=true&connectTimeout=5000&serverTimezone=Asia%2FShanghai&zeroDateTimeBehavior=convertToNull&useSSL=false
========== 初始化增量表:comment_info ==========
connecting to jdbc:mysql://hadoop101:3306/maxwell?allowPublicKeyRetrieval=true&connectTimeout=5000&serverTimezone=Asia%2FShanghai&zeroDateTimeBehavior=convertToNull&useSSL=false
========== 初始化增量表:favor_info ==========
connecting to jdbc:mysql://hadoop101:3306/maxwell?allowPublicKeyRetrieval=true&connectTimeout=5000&serverTimezone=Asia%2FShanghai&zeroDateTimeBehavior=convertToNull&useSSL=false
========== 初始化增量表:order_detail ==========
connecting to jdbc:mysql://hadoop101:3306/maxwell?allowPublicKeyRetrieval=true&connectTimeout=5000&serverTimezone=Asia%2FShanghai&zeroDateTimeBehavior=convertToNull&useSSL=false
========== 初始化增量表:order_info ==========
connecting to jdbc:mysql://hadoop101:3306/maxwell?allowPublicKeyRetrieval=true&connectTimeout=5000&serverTimezone=Asia%2FShanghai&zeroDateTimeBehavior=convertToNull&useSSL=false
========== 初始化增量表:payment_info ==========
connecting to jdbc:mysql://hadoop101:3306/maxwell?allowPublicKeyRetrieval=true&connectTimeout=5000&serverTimezone=Asia%2FShanghai&zeroDateTimeBehavior=convertToNull&useSSL=false
========== 初始化增量表:review_info ==========
connecting to jdbc:mysql://hadoop101:3306/maxwell?allowPublicKeyRetrieval=true&connectTimeout=5000&serverTimezone=Asia%2FShanghai&zeroDateTimeBehavior=convertToNull&useSSL=false
========== 初始化增量表:test_exam ==========
connecting to jdbc:mysql://hadoop101:3306/maxwell?allowPublicKeyRetrieval=true&connectTimeout=5000&serverTimezone=Asia%2FShanghai&zeroDateTimeBehavior=convertToNull&useSSL=false
========== 初始化增量表:test_exam_question ==========
connecting to jdbc:mysql://hadoop101:3306/maxwell?allowPublicKeyRetrieval=true&connectTimeout=5000&serverTimezone=Asia%2FShanghai&zeroDateTimeBehavior=convertToNull&useSSL=false
========== 初始化增量表:user_info ==========
connecting to jdbc:mysql://hadoop101:3306/maxwell?allowPublicKeyRetrieval=true&connectTimeout=5000&serverTimezone=Asia%2FShanghai&zeroDateTimeBehavior=convertToNull&useSSL=false
========== 初始化增量表:vip_change_detail ==========
connecting to jdbc:mysql://hadoop101:3306/maxwell?allowPublicKeyRetrieval=true&connectTimeout=5000&serverTimezone=Asia%2FShanghai&zeroDateTimeBehavior=convertToNull&useSSL=false
[vaultattic@hadoop101 ansible]$
检查同步结果:
hadoop fs -ls /origin_data/edu/db
[vaultattic@hadoop101 ansible]$ hadoop fs -ls /origin_data/edu/db | grep _inc
drwxr-xr-x - vaultattic supergroup 0 2026-06-12 21:34 /origin_data/edu/db/cart_info_inc
drwxr-xr-x - vaultattic supergroup 0 2026-06-12 21:34 /origin_data/edu/db/comment_info_inc
drwxr-xr-x - vaultattic supergroup 0 2026-06-12 21:34 /origin_data/edu/db/favor_info_inc
drwxr-xr-x - vaultattic supergroup 0 2026-06-12 21:34 /origin_data/edu/db/order_detail_inc
drwxr-xr-x - vaultattic supergroup 0 2026-06-12 21:34 /origin_data/edu/db/order_info_inc
drwxr-xr-x - vaultattic supergroup 0 2026-06-12 21:34 /origin_data/edu/db/payment_info_inc
drwxr-xr-x - vaultattic supergroup 0 2026-06-12 21:34 /origin_data/edu/db/review_info_inc
drwxr-xr-x - vaultattic supergroup 0 2026-06-12 21:34 /origin_data/edu/db/test_exam_inc
drwxr-xr-x - vaultattic supergroup 0 2026-06-12 21:34 /origin_data/edu/db/test_exam_question_inc
drwxr-xr-x - vaultattic supergroup 0 2026-06-12 21:34 /origin_data/edu/db/user_info_inc
drwxr-xr-x - vaultattic supergroup 0 2026-06-12 21:34 /origin_data/edu/db/vip_change_detail_inc
[vaultattic@hadoop101 ansible]$
三、数仓环境准备
1、安装 Hive
Hive 是基于 Hadoop 的数据仓库工具,可以将 HDFS 上的结构化数据映射成表,并使用类 SQL 的方式进行查询和分析。
在离线数仓中,Hive 主要用于:
- 管理 HDFS 上的数据文件;
- 建立 ODS、DIM、DWD、DWS、ADS 等数仓分层表;
- 使用 SQL 完成离线数据清洗、转换和统计分析。
Hive 本身不负责存储数据,真实数据仍然存储在 HDFS 中。Hive 主要维护的是表结构、字段、分区、文件位置等元数据信息。
我以前有写过一个详细的安装步骤,感兴趣可以看看:Hive 环境搭建(基于 Hadoop + MySQL) - 滕王阁,所以一些配置的来源就不写了。
软件包下载
这里选择 Hive 3.1.3 版本。虽然当前 Hive 最新版为 4.0+,但还在更新中,所以选择较为稳定的 3.0+ 的最后这个版本。
Hive 官方下载链接:https://archive.apache.org/dist/hive/hive-3.1.3/
百度网盘链接:https://pan.baidu.com/s/1O3Skv-6OwtMnBt3Gm_5vqQ?pwd=kapr
下载好后将软件压缩包使用 MobeXterm 上传到 hadoop101 的 ~/ansible/files 目录下。
和前面安装软件的过程一样,复制文件名,将之前写好的 deploy_package.yml 中的变量进行替换,注意 hosts 改为 hadoop101,这个软件不需要所以集群都安装。
替换后的 deploy_package.yml:
- name: Deploy package
hosts: hadoop101
vars:
pkg_name: apache-hive-3.1.3-bin.tar.gz
dest_dir: hive-3.1.3
tasks:
- name: Copy archive
copy:
src: "./files/{{ pkg_name }}"
dest: "/opt/{{ pkg_name }}"
- name: Get top directory name from archive
shell: tar -tf /opt/{{ pkg_name }} | head -1 | cut -d/ -f1
register: archive_dir
- name: Extract archive
command: tar -xzf /opt/{{ pkg_name }} -C /opt
- name: Rename directory
command: mv /opt/{{ archive_dir.stdout | trim }} /opt/{{ dest_dir }}
args:
creates: /opt/{{ dest_dir }}
- name: Change ownership
file:
path: "/opt/{{ dest_dir }}"
owner: vaultattic
group: vaultattic
recurse: yes
- name: Remove archive
file:
path: "/opt/{{ pkg_name }}"
state: absent
运行 deploy_package.yml:
ansible-playbook deploy_package.yml
执行完后可以在各节点的 /opt 目录下查看 Hive 目录是否存在。
cluster-run.sh ls /opt
[vaultattic@hadoop101 ansible]$ cluster-run.sh ls /opt
--------- hadoop101 ----------
amazon-corretto-11
amazon-corretto-8
data_mocker
datax-202309
flume-1.11.0
hadoop-3.3.6
hive-3.1.3
kafka-3.9.2
maxwell-1.44.1
zookeeper-3.8.6
--------- hadoop102 ----------
amazon-corretto-8
flume-1.11.0
hadoop-3.3.6
kafka-3.9.2
zookeeper-3.8.6
--------- hadoop103 ----------
amazon-corretto-8
flume-1.11.0
hadoop-3.3.6
kafka-3.9.2
zookeeper-3.8.6
[vaultattic@hadoop101 ansible]$
使用 set_env.yml 配置 HIVE_HOME 环境变量。
复制要配置环境变量的目录路径,将 set_env.yml 中的变量进行替换:
---
- name: Configure environment variables
hosts: hadoop101
vars:
env_name: HIVE_HOME
env_path: /opt/hive-3.1.3
tasks:
- name: Add environment variables to /home/vaultattic/.bashrc
lineinfile:
path: "/home/vaultattic/.bashrc"
line: "export {{ env_name }}={{ env_path }}"
create: yes
- name: Add PATH for {{ env_name }}
lineinfile:
path: "/home/vaultattic/.bashrc"
line: "export PATH=${{ env_name }}/bin:$PATH"
运行 set_env.yml:
ansible-playbook set_env.yml
执行 playbook 后使用:
source ~/.bashrc
hive --version
[vaultattic@hadoop101 ansible]$ source ~/.bashrc
[vaultattic@hadoop101 ansible]$ hive --version
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/hive-3.1.3/lib/log4j-slf4j-impl-2.17.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/hadoop-3.3.6/share/hadoop/common/lib/slf4j-reload4j-1.7.36.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Hive 3.1.3
Git git://MacBook-Pro.fios-router.home/Users/ngangam/commit/hive -r 4df4d75bf1e16fe0af75aad0b4179c34c07fc975
Compiled by ngangam on Sun Apr 3 16:58:16 EDT 2022
From source with checksum 5da234766db5dfbe3e92926c9bbab2af
[vaultattic@hadoop101 ansible]$
解决依赖冲突
Hive 3.1.2 和 Hadoop 3.3.6 搭配时,可能会遇到部分 jar 包版本冲突问题,需要提前处理。
Hive 自带的 guava 版本较老,而 Hadoop 3.3.6 使用的 guava 版本较新。为了避免运行时报 NoSuchMethodError 等问题,可以将 Hive 中的 guava 替换成 Hadoop 中的版本。
进入 Hive lib 目录:
cd $HIVE_HOME/lib
备份 Hive 自带 guava:
mv guava-19.0.jar guava-19.0.jar.bak
Hive 和 Hadoop 中都可能包含 SLF4J / Log4j 相关 jar 包,启动时可能出现日志绑定冲突。
进入 Hive lib 目录:
cd $HIVE_HOME/lib
备份 Hive 中的 log4j-slf4j-impl:
mv log4j-slf4j-impl-2.17.1.jar log4j-slf4j-impl-2.17.1.jar.bak
2、Hive 元数据配置到 MySQL
Hive 的元数据默认可以存储在内置 Derby 数据库中,但 Derby 只适合本地测试,不适合多客户端同时访问。
在实际项目中,通常将 Hive 元数据存储到 MySQL 中。这样 Hive 客户端、HiveServer2、调度任务等都可以共享同一套元数据。
安装 MySQL JDBC 驱动
Hive 需要通过 JDBC 连接 MySQL,因此需要将 MySQL Connector/J 驱动放到 Hive 的 lib 目录下。
MySQL Connector/J 官网下载地址:https://downloads.mysql.com/archives/c-j/,直接选最新版下载😡。
下载后解压,把里面的 JAR 文件上传到 /opt/hive-3.1.3/lib 目录中(或者我把这个 JAR 文件直接上传百度网盘了:https://pan.baidu.com/s/1aUpV1L4LlGpovVRQ8jSD1A?pwd=lj0f)。
创建 Hive 元数据库
修改 Hive 配置文件
vim $HIVE_HOME/conf/hive-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<!-- Hive 元数据库连接地址 -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop101:3306/metastore?useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true</value>
</property>
<!-- MySQL 8 使用的 JDBC 驱动类 -->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
</property>
<!-- MySQL 用户名 -->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!-- MySQL 密码 -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<!-- Hive 默认仓库目录 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<!-- 关闭元数据库版本校验 -->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<!-- HiveServer2 端口 -->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<!-- HiveServer2 绑定地址 -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>0.0.0.0</value>
</property>
<!-- 关闭 metastore 事件通知权限校验 -->
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<!-- Hive CLI 显示查询结果表头 -->
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<!-- Hive CLI 显示当前数据库名 -->
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
<!-- 缩短 HiveServer2 启动等待时间 -->
<property>
<name>hive.server2.active.passive.ha.enable</name>
<value>true</value>
</property>
<!-- 让部分客户端可以正确读取 JsonSerDe 表结构 -->
<property>
<name>metastore.storage.schema.reader.impl</name>
<value>org.apache.hadoop.hive.metastore.SerDeStorageSchemaReader</value>
</property>
</configuration>
创建 Hive 元数据库
登录 MySQL:
mysql -uroot -p123456
创建 Hive 元数据库:
CREATE DATABASE IF NOT EXISTS metastore
DEFAULT CHARACTER SET utf8mb4
COLLATE utf8mb4_general_ci;
[vaultattic@hadoop101 ~]$ mysql -uroot -p123456
mysql: [Warning] Using a password on the command line interface can be insecure.
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 405
Server version: 8.4.8 MySQL Community Server - GPL
Copyright (c) 2000, 2026, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> CREATE DATABASE IF NOT EXISTS metastore
-> DEFAULT CHARACTER SET utf8mb4
-> COLLATE utf8mb4_general_ci;
Query OK, 1 row affected (0.01 sec)
mysql>
3、初始化 Hive 元数据库
初始化 metastore
执行初始化命令:
schematool -initSchema -dbType mysql -verbose
出现 schemaTool completed 说明初始化成功。
创建 HDFS 仓库目录
创建 Hive 仓库目录:
hadoop fs -mkdir -p /user/hive/warehouse
设置权限:
hadoop fs -chmod -R 777 /user/hive/warehouse
4、启动 Hive
Hive 可以通过 CLI 直接使用,也可以启动 HiveServer2,供 DataGrip、DBeaver、Beeline 等客户端连接。
启动 Hive CLI
直接执行:
hive
进入 Hive 后查看数据库:
show databases;
正常情况下可以看到:
default
退出 Hive:
quit;
启动 HiveServer2
如果需要通过 JDBC 客户端连接 Hive,可以启动 HiveServer2。
启动 HiveServer2:
nohup hiveserver2 > $HIVE_HOME/logs/hiveserver2.log 2>&1 &
如果 logs 目录不存在,先创建:
mkdir -p $HIVE_HOME/logs
查看进程:
jps
如果看到 RunJar 说明 HiveServer2 已经启动。
查看日志:
tail -f $HIVE_HOME/logs/hiveserver2.log
使用 Beeline 连接 HiveServer2
连接 HiveServer2:
beeline -u jdbc:hive2://hadoop101:10000 -n vaultattic
连接成功后执行:
show databases;
如果能正常返回数据库列表,说明 HiveServer2 可用。
四、后记
后面还有两章,没时间写了,每次都这样😓。
上课只上了第三章的一小半,主要是现在星期六了,星期一就检查成果了,我现在才刚刚把这个第二章搞完。
网络安全还有 3 篇实验报告要写,而且要考试,虽然是开卷但还没开始预习🥲。
早知道,当初就不该下载杀戮尖塔 2😵💫,谁能告诉我时间都去哪了😶🌫️。
中转站的 Codex 也被奥特曼制裁了,没有 AI 我现在感觉什么也做不了😭。