
一、前言
这个学期大数据项目是实训要求搭建一个电商数仓,我看老师发的资料好像是直接把尚硅谷的教程直接拿来用了🤔。
记录一下搭建过程吧🐔。
简介
数据仓库( Data Warehouse ),是为企业制定决策,提供数据支持的。可以帮助企业改进业务流程、提高产品质量等。
数据仓库的输入数据通常包括:业务数据、用户行为数据和爬虫数据等。
- 业务数据:就是各行业在处理事务过程中产生的数据。比如用户在网站中登录、下单、支付等过程中,需要和网站后台数据库进行增删改查交互,产生的数据就是业务数据。业务数据通常存储在MySQL、Oracle等数据库中。
- 用户行为数据:用户在使用产品过程中,通过埋点收集与客户端产品交互过程中产生的数据,并发往日志服务器进行保存。比如页面浏览、点击、停留、评论、点赞、收藏等。用户行为数据通常存储在日志文件中。
- 爬虫数据:通常是通过技术手段获取其他公司网站的数据。不建议这样去做。
二、虚拟机环境准备
虽然老师给了一个现成的虚拟机,其他环境只需要在这个虚拟机的克隆环境上配置,但我还是想自己从头配一次😗。
1、创建虚拟机
我这里选择的 Linux 发行版是 Rocky Linux,相当于 CentOS(现以停止支持)的后续版本吧(都是 RedHat 系的)。
下载 DVD 镜像(完整版),Boot 镜像只包含启动程序,安装时需要联网下载软件,Minimal 最小系统镜像只安装最基础的系统,没有图形和额外软件。
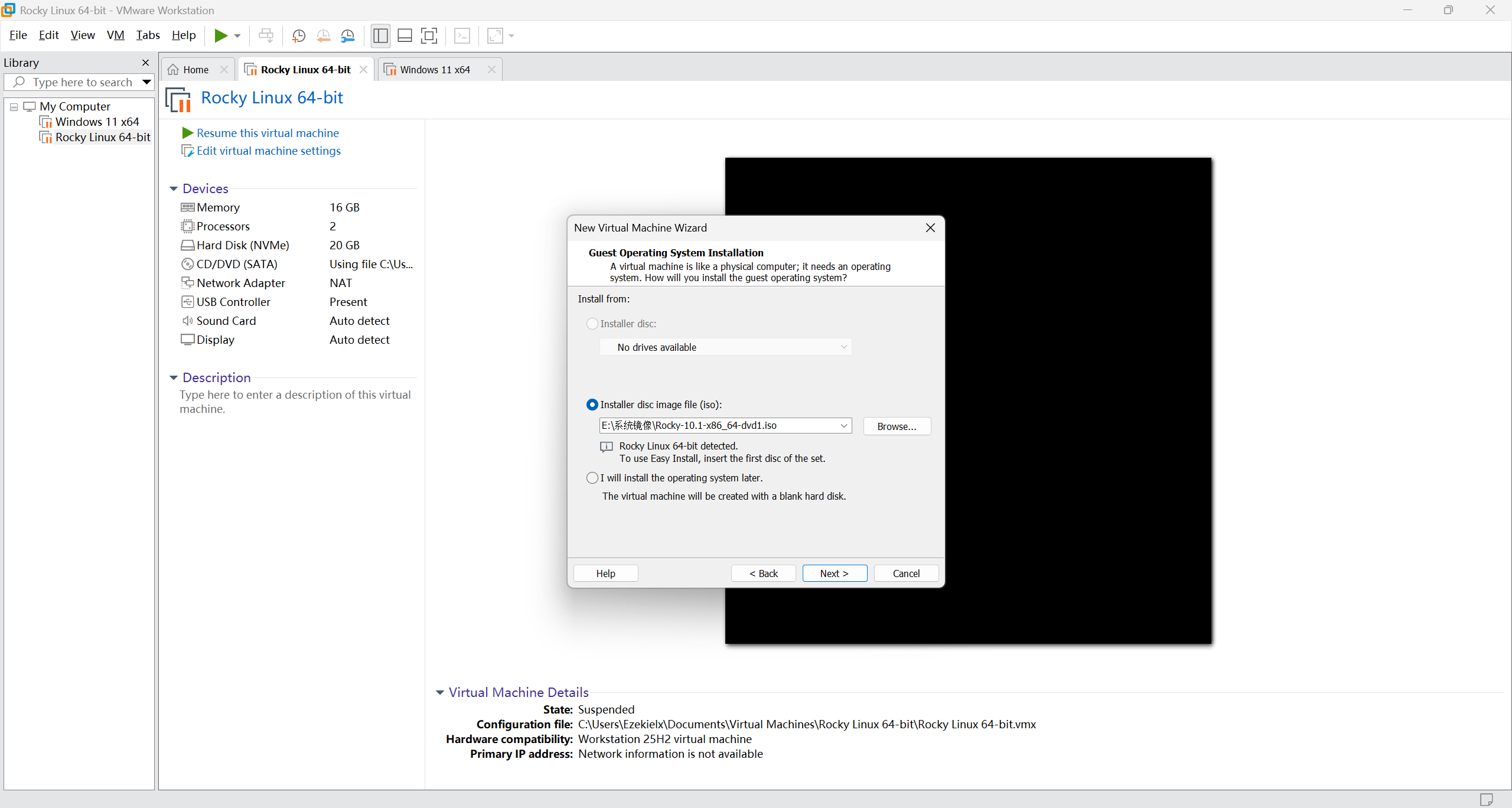
在 VMware Workstation 中创建一个新虚拟机,选择刚刚下载的镜像,磁盘空间默认就行,名字就叫 hadoop100。后面的系统安装步骤直接按照指引一直下一步就行了(左下角选创建 root 用户,普通用户可以进系统以后创建)。
进入系统后按照提示创建一个用户(运行 hadoop 的用户名一般就叫 hadoop,但学习的话就一个用户,随便起名了)。

如果是想把系统语言改成中文可以 [右键 - Setting - System - Region & Language] 里面自行修改。
2、修改主机名和网络配置
打开终端。
输入 nmtui,使用图形化界面修改主机配置(和直接改网络配置文件是一样的,nmtui 带图形界面方便一点)。
编辑连接,选择 ens 开头的配置,IPv4 改为手动。
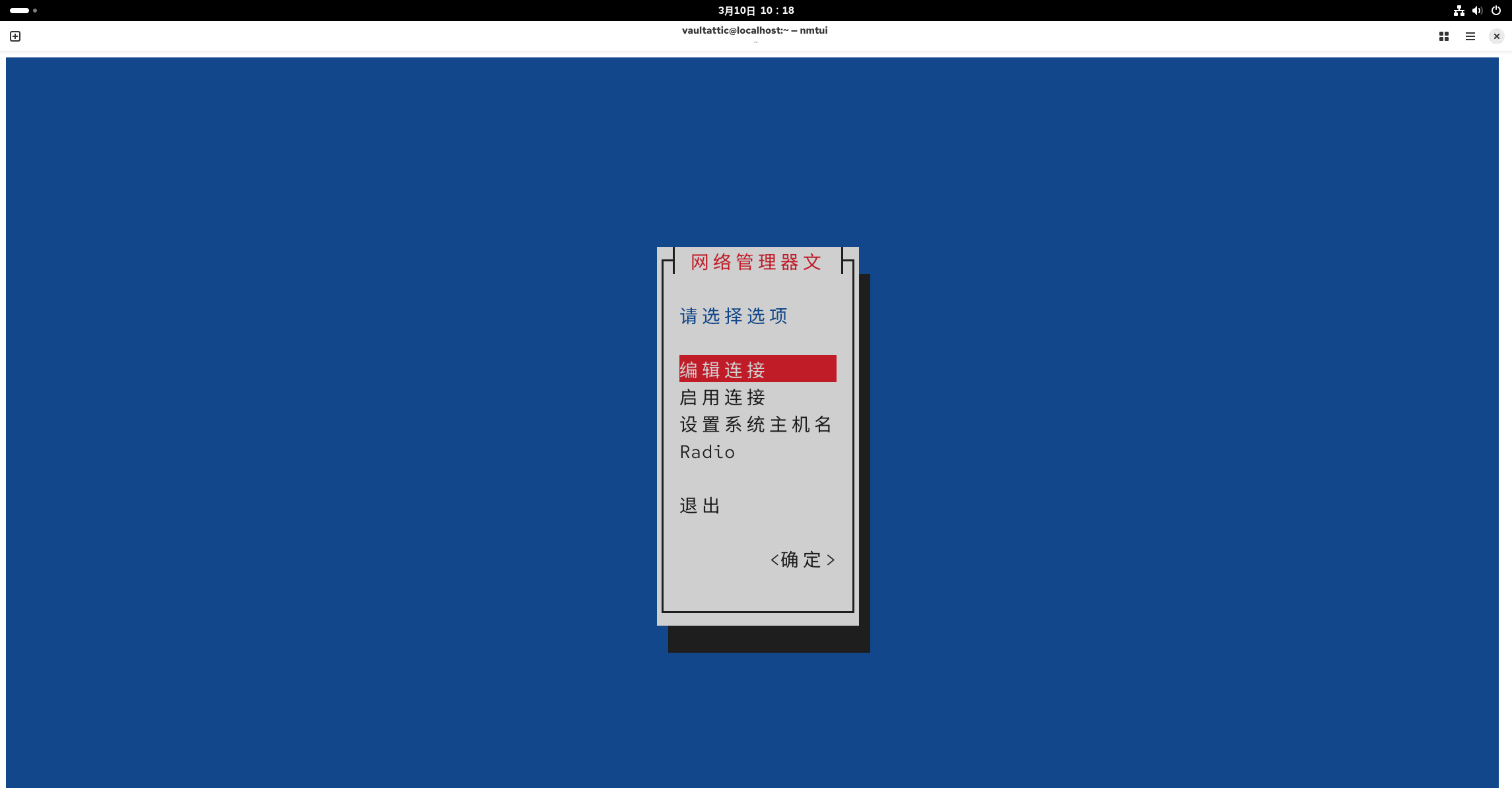
接下来打开 VMware Workstation,在 [Edit - Virtual Network Editor] 中查看 NAT 模式下的虚拟网卡 VMnet8 的网段(我的是 192.168.144.0)。
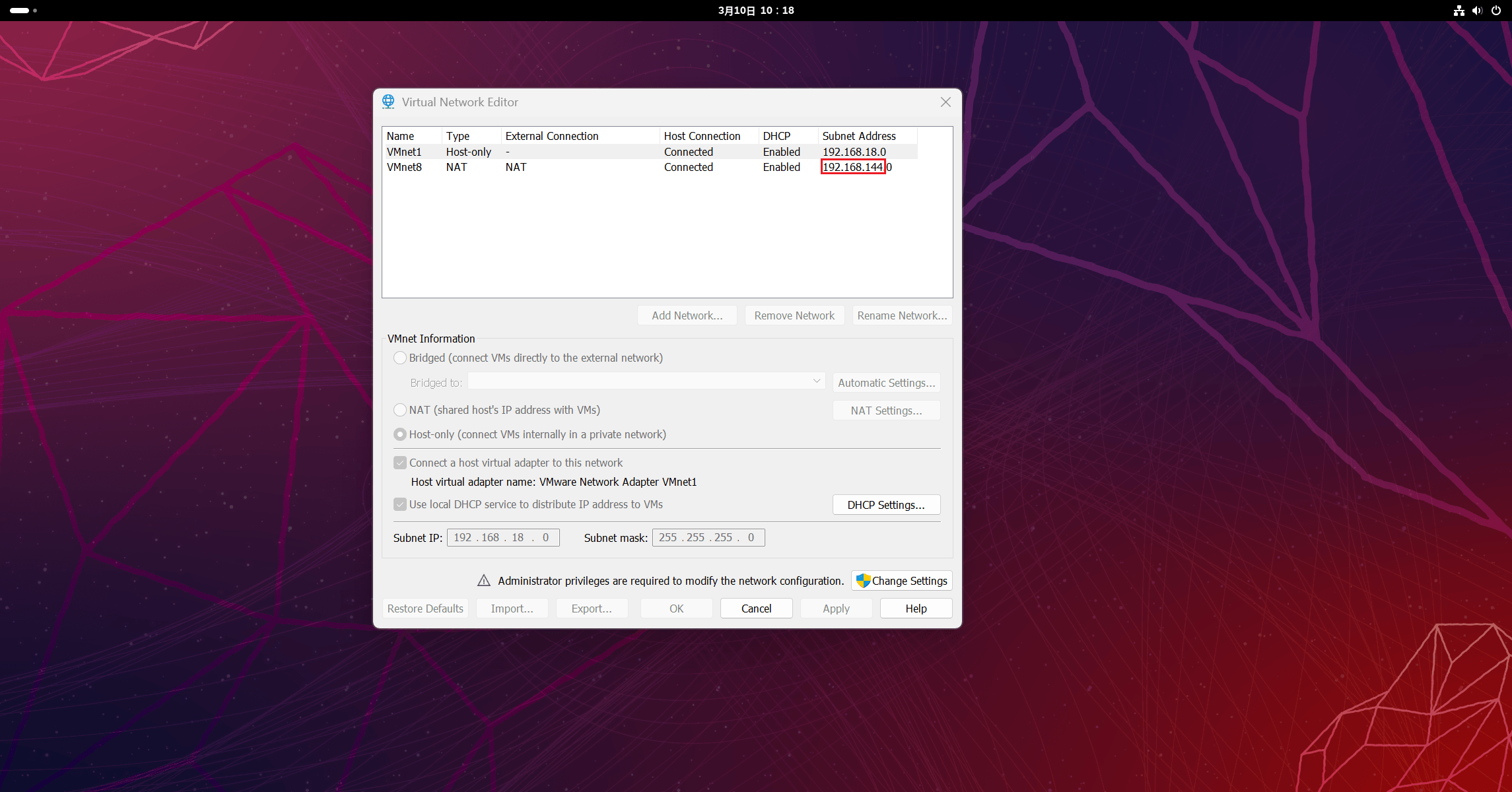
回到虚拟机中,将红框部分替换为刚刚查看的网段,地址那一栏红框外的那个三位数可以从 3 ~ 254 随便选一个填,我这里就填 100 和主机名对应。
回到 nmtui 的主页,在启用连接中关闭后再打开一次 ens 开头的配置(就是刷新一下)。
再回到主页,选择设置主机名,改为 hadoop100。
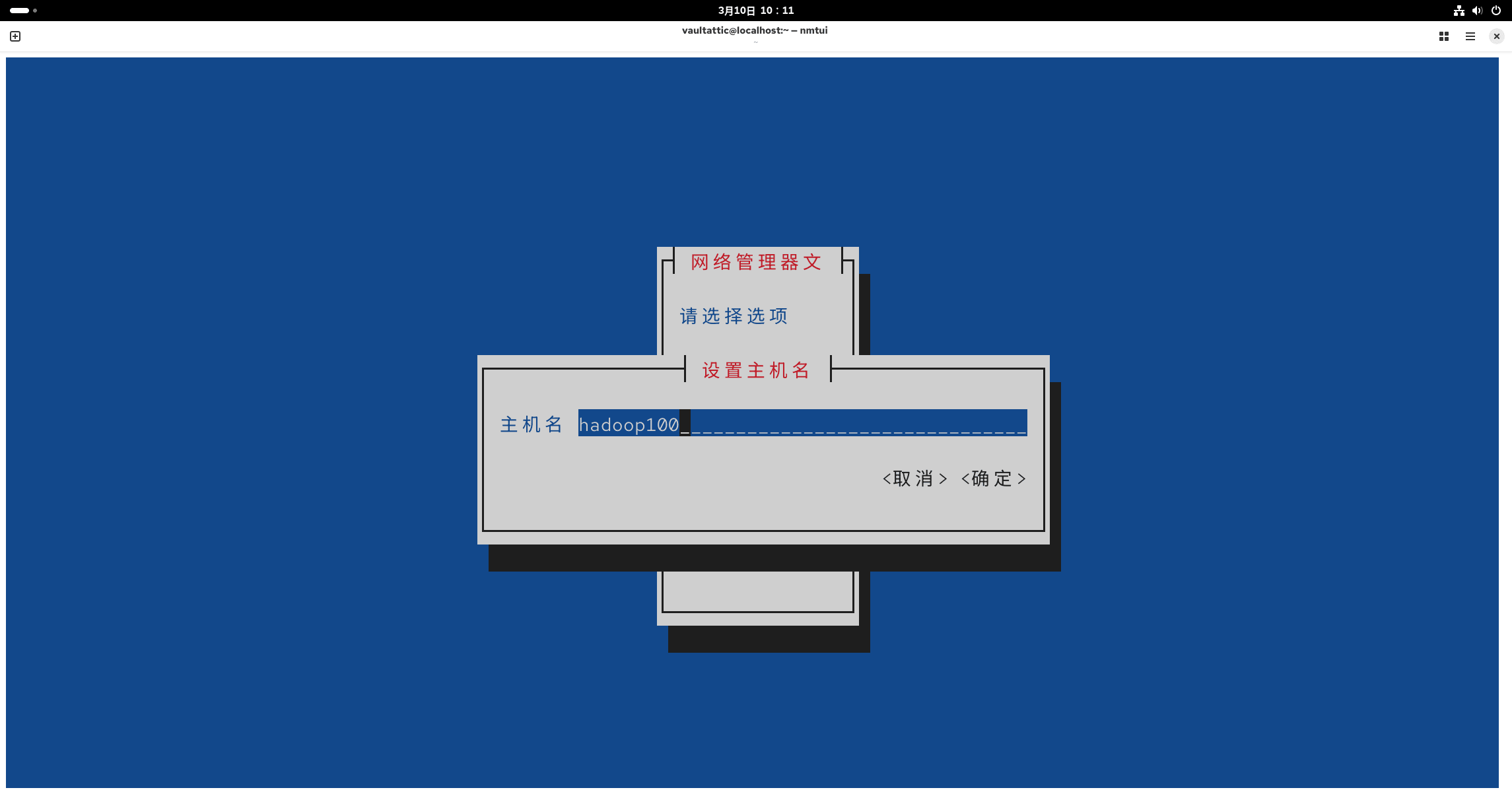
3、sudo 免密配置
一般来说是不直接使用 root 用户的,但一些操作普通用户权限不够,所以就需要 sudo 命令对普通用户进行提权。
wheel 组是 Linux 里一个特殊的管理员用户组,常用来控制谁可以获取 root 权限。
在一开始安装 Linux 时创建的那个用户是自动被添加在 wheel组中的,所以不用设置也可以使用 sudo 命令。
将 vaultattic 用户添加到 wheel 组中:
sudo usermod -aG wheel vaultattic
如果不想在后续使用 sudo 命令时输入密码,也可以修改配置文件设置 sudo 免密😎。
终端运行:
sudo visudo /etc/sudoers
到这一行:
%wheel ALL=(ALL) ALL
改成:
%wheel ALL=(ALL) NOPASSWD:ALL

/etc/sudoers.d/vaultattic 是为用户单独创建了一个 sudo 配置文件,实际上和修改 sudo 主文件 /etc/sudoers 的效果是一样的。
4、修改 hosts 文件
接下来将所有虚拟机(当前只有 hadoop100,其他虚拟机后面添加)的主机名和 IP 地址的对应加入 hosts 文件,之后连接不同主机只需要输入主机名而不是冗长的 IP 地址。
在虚拟机终端中输入:
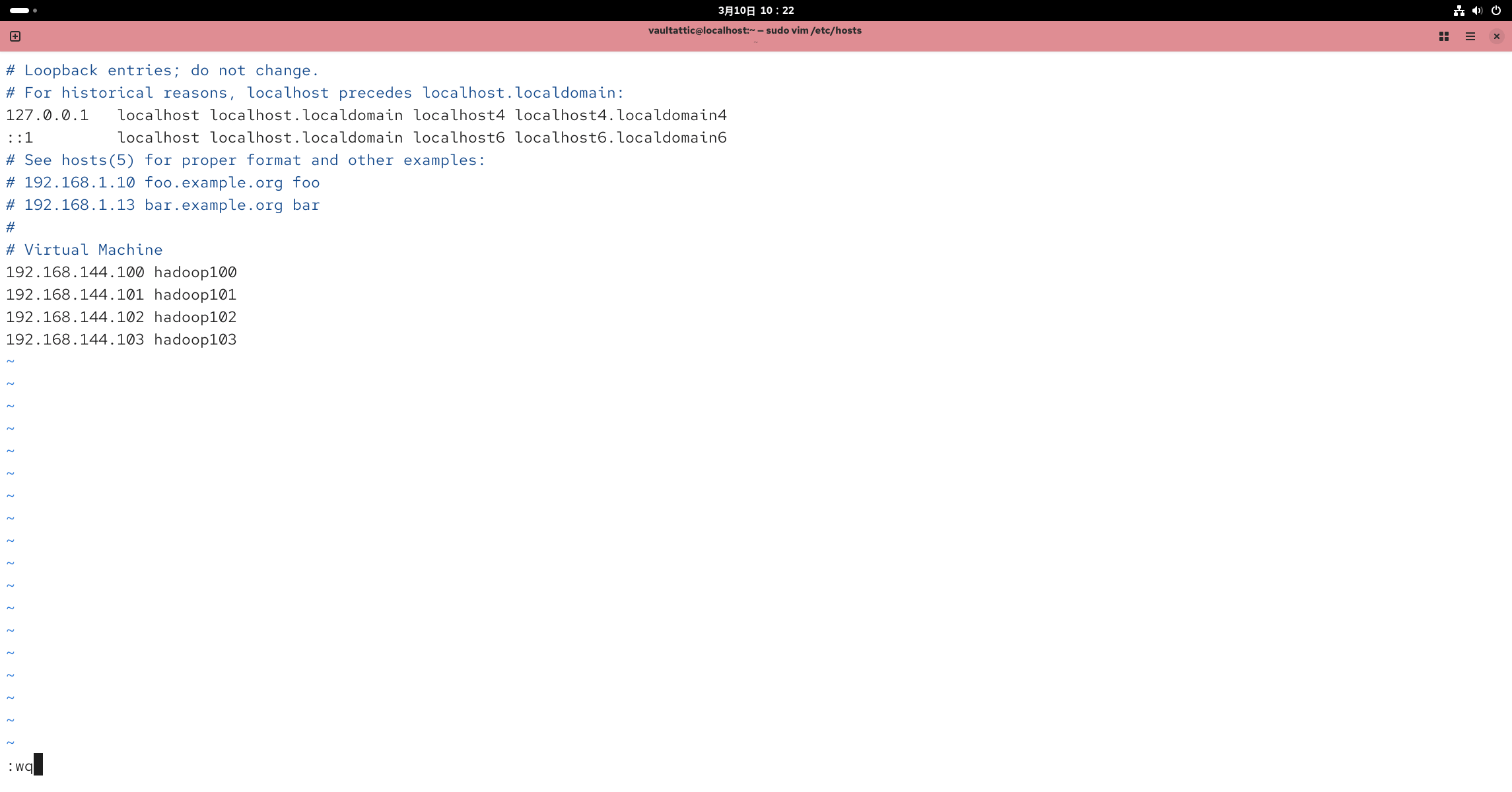
sudo vim /etc/hosts
按 i 进入编辑模式,在末尾添加如下字段:
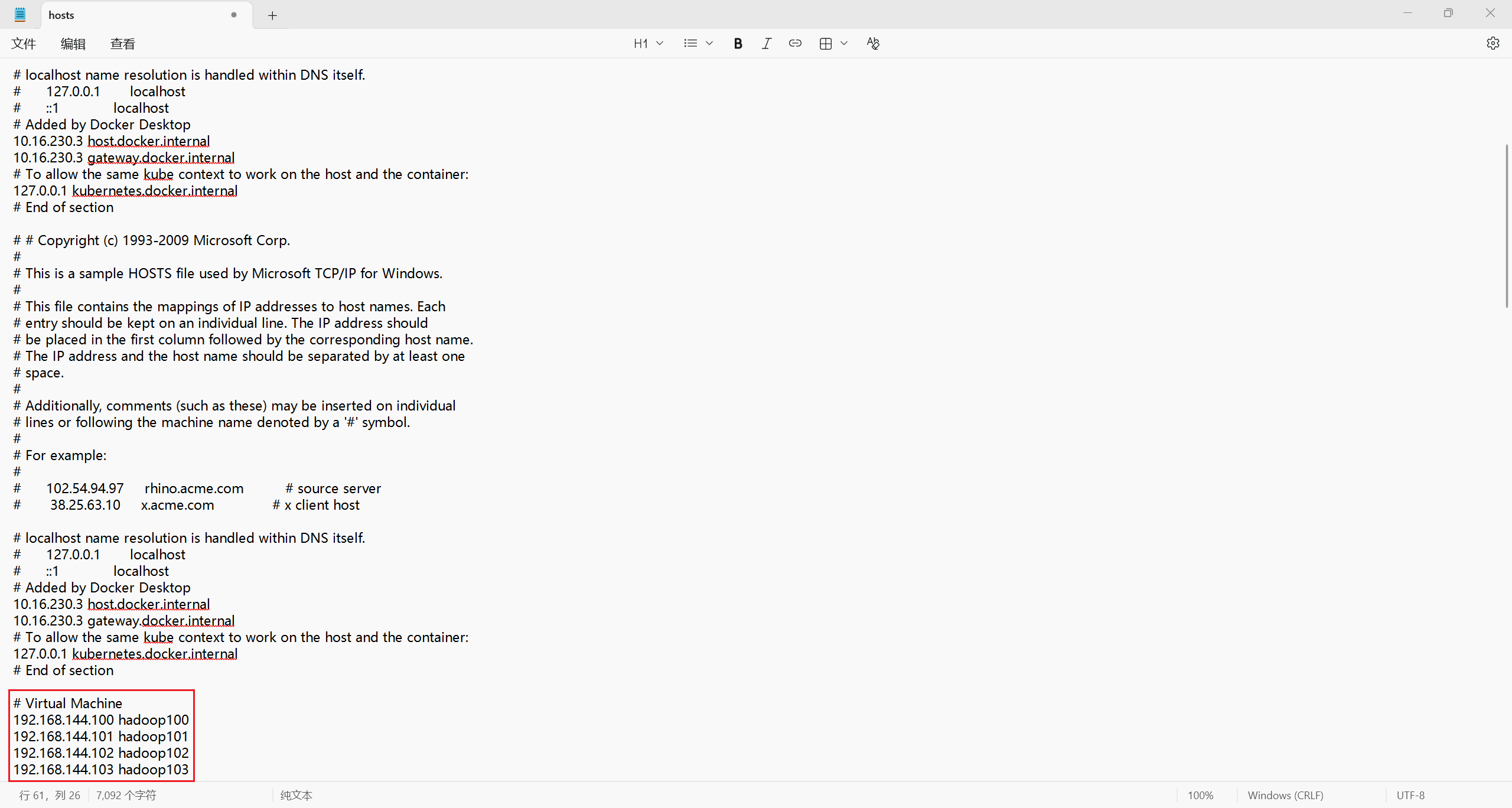
# Virtual Machine
192.168.144.100 hadoop100
192.168.144.101 hadoop101
192.168.144.102 hadoop102
192.168.144.103 hadoop103
按 Esc,输入 :wq 回车保存并退出。
在你自己的 Windows 中的以管理员身份运行记事本,左上角 [文件 - 打开],打开 C:\Windows\System32\drivers\etc\hosts 路径下的文件,在末尾添加相同的字段。
5、关闭防火墙
终端输入已下命令:
sudo systemctl disable firewalld
sudo systemctl stop firewalld
用于关闭防火墙,否则后续防火墙会阻止物理机访问 WebUI。‘
6、修改 /opt 目录权限
/opt 一般是 Linux 系统用来存放第三方软件或手动安装的软件的目录,我们的 Hadoop 生态相关软件就安装在里面。但这个目录的所有者是 root,而运行 Hadoop 的用户是我们一开始创建的普通用户 vaultattic,vaultattic 用户没有修改 /opt 目录的权限,所以需要将 /opt 的所有者修改为 vaultattic(正常来说应该是在 /opt 目录下再创建一个子目录用于存放 hadoop 相关的软件,但这只是一个学习环境,我为了方便直接修改 /opt 目录了😶🌫️)。
将 /opt 目录的所有者改为 vaultattic:
sudo chown vaultattic:vaultattic /opt
7、克隆虚拟机
将 hadoop100 克隆三份,分别为 hadoop101、hadoop102、hadoop103。
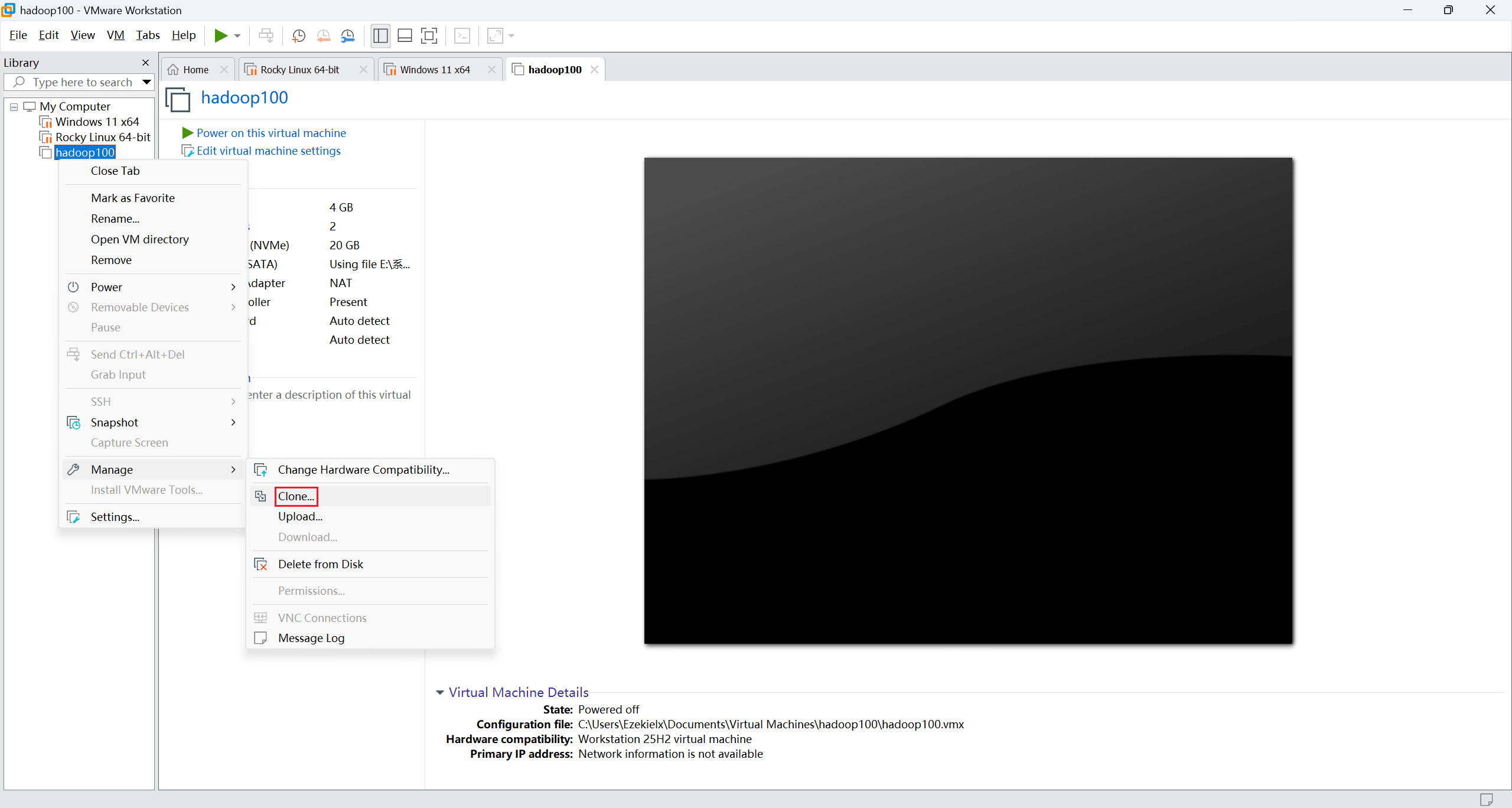
克隆选项这里第一个是克隆的机器依赖于原机器,占用的存储空间小一点,但原机器不能删,第二个则是完整克隆,看自己选择。
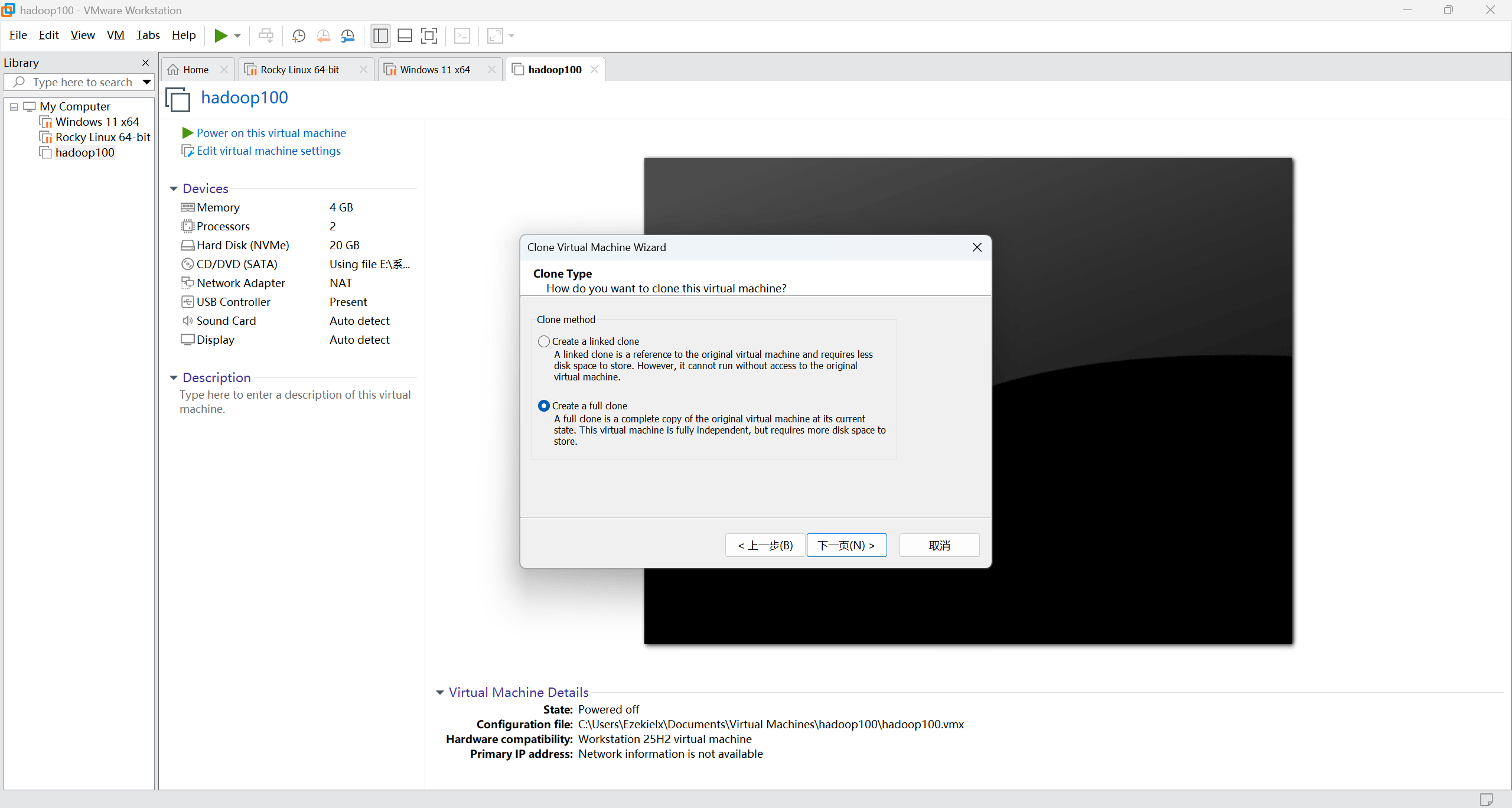
克隆完成后查看之前的修改主机名和网络配置的步骤,把 IP 地址(192.168.144.101、192.168.144.102、192.168.144.103)和主机名(hadoop101、hadoop102、hadoop103)改过来。
8、使用 SSH 远程连接虚拟机
直接在 VMware 中操作虚拟机非常的不方便😑,来回切换虚拟机加载时间长,终端卡顿,而且这个 GUI 界面在后面就基本用不到了,而且大部分 SSH 软件都支持文件管理🤔,上传文件也会方便一点。
我用的 MobaXterm 连接的,具体使用方法我以前的文章写过,可以参考:MobaXterm:强大的远程网络工具,SSH 远程连接功能的使用 - 滕王阁 。
将刚刚创建的所以虚拟机使用普通用户连接上 MobaXterm。
9、设置各节点 SSH 免密登录
Hadoop 在各个节点执行命令是通过 SSH 的,使用如果不配置 SSH 免密,Hadoop 每次操作节点时都要提示你输入密码,所以 SSH 免密是必要的👻。
在每个节点上生成 SSH 公私钥(输入命令后一直回车就可以了,不用管那些提示):
ssh-keygen -t rsa
[vaultattic@hadoop101 ~]$ ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/home/vaultattic/.ssh/id_rsa):
Created directory '/home/vaultattic/.ssh'.
Enter passphrase for "/home/vaultattic/.ssh/id_rsa" (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/vaultattic/.ssh/id_rsa
Your public key has been saved in /home/vaultattic/.ssh/id_rsa.pub
The key fingerprint is:
SHA256:+lwxB1YlrwsxZjXzXbl2ym05roaS9dG6aR4xuTp4PG4 vaultattic@hadoop101
The key's randomart image is:
+---[RSA 3072]----+
| *.. o|
| o * o.|
| B o o|
| + + ..o.|
| S + o=ooo|
| . * o*+o|
| . * +o+..|
| o = E.=o. |
| o =o*=o |
+----[SHA256]-----+
[vaultattic@hadoop101 ~]$
之后复制公钥到授权文件:
ssh-copy-id vaultattic@hadoop101
ssh-copy-id vaultattic@hadoop102
ssh-copy-id vaultattic@hadoop103
[vaultattic@hadoop101 ~]$ ssh-copy-id vaultattic@hadoop101
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/home/vaultattic/.ssh/id_rsa.pub"
The authenticity of host 'hadoop101 (192.168.144.101)' can't be established.
ED25519 key fingerprint is SHA256:qs8ZZoNgMbB+BfLcvc4ia/rGtHbm7xqPfVHy4Pgzq1k.
This key is not known by any other names.
Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
vaultattic@hadoop101's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'vaultattic@hadoop101'"
and check to make sure that only the key(s) you wanted were added.
[vaultattic@hadoop101 ~]$ ssh-copy-id vaultattic@hadoop102
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/home/vaultattic/.ssh/id_rsa.pub"
The authenticity of host 'hadoop102 (192.168.144.102)' can't be established.
ED25519 key fingerprint is SHA256:qs8ZZoNgMbB+BfLcvc4ia/rGtHbm7xqPfVHy4Pgzq1k.
This host key is known by the following other names/addresses:
~/.ssh/known_hosts:1: hadoop101
Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
vaultattic@hadoop102's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'vaultattic@hadoop102'"
and check to make sure that only the key(s) you wanted were added.
[vaultattic@hadoop101 ~]$ ssh-copy-id vaultattic@hadoop103
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/home/vaultattic/.ssh/id_rsa.pub"
The authenticity of host 'hadoop103 (192.168.144.103)' can't be established.
ED25519 key fingerprint is SHA256:qs8ZZoNgMbB+BfLcvc4ia/rGtHbm7xqPfVHy4Pgzq1k.
This host key is known by the following other names/addresses:
~/.ssh/known_hosts:1: hadoop101
~/.ssh/known_hosts:4: hadoop102
Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
vaultattic@hadoop103's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'vaultattic@hadoop103'"
and check to make sure that only the key(s) you wanted were added.
[vaultattic@hadoop101 ~]$
执行命令后第一次询问输入 yes,第二次输入你创建的用户密码,像上面这样。这里只演示了 hadoop101 一台机器,其他 hadoop102、hadoop103 都要执行上面相同的命令😘。
10、使用 Ansible 进行自动化管理
由于是设置集群,很多东西是需要统一设置的。比如分发文件、修改系统设置等。
老师教的好像是用 xsync 写一个文件分发的脚本,很多系统设置要自己单独去设置,有点麻烦😥。
之前考 RHCE 的时候学了 Ansible(一个自动化管理平台 Linux-红帽认证 RHCE-01-介绍 Ansible - 滕王阁),感觉这个用着挺方便的,所以就不按老师的搞了,随便学以致用试试看😋。
在 hadoop101 上安装 Ansible:
sudo dnf install ansible-core
创建 ansible 工作目录:
mkdir ansible
进入目录编辑 inventory 清单文件:
vim inventory
[hadoop]
hadoop101
hadoop102
hadoop103
编辑 ansible 配置文件:
[defaults]
inventory = ./inventory
remote_user = vaultattic
ask_pass = false
[privilege_escalation]
become = true
become_user = root
become_method = sudo
become_ask_pass = false
上面是运行 Ansible 的一些基础设置,下面编写文件分发 playbook。后面给所有节点安装软件时,只需要上传软件压缩包到 hadoop101 就能使用写好的 playbook 直接分发给其他节点。
编写部署软件 playbook:
vim deploy_package.yml
---
- name: Deploy package
hosts: hadoop
vars:
pkg_name: amazon-corretto-8.482.08.1-linux-x64.tar.gz
dest_dir: amazon-corretto-8
tasks:
- name: Copy archive
copy:
src: "./files/{{ pkg_name }}"
dest: "/opt/{{ pkg_name }}"
- name: Get top directory name from archive
shell: tar -tf /opt/{{ pkg_name }} | head -1 | cut -d/ -f1
register: archive_dir
- name: Extract archive
command: tar -xzf /opt/{{ pkg_name }} -C /opt
- name: Rename directory
command: mv /opt/{{ archive_dir.stdout | trim }} /opt/{{ dest_dir }}
args:
creates: /opt/{{ dest_dir }}
- name: Set ownership to vaultattic
file:
path: "/opt/{{ dest_dir }}"
owner: vaultattic
group: vaultattic
recurse: yes
- name: Remove archive
file:
path: "/opt/{{ pkg_name }}"
state: absent
pkg_name:软件压缩包名称dest_dir:解压后的目录名称
创建 files 目录用于存放要分发的软件压缩包:
mkdir files
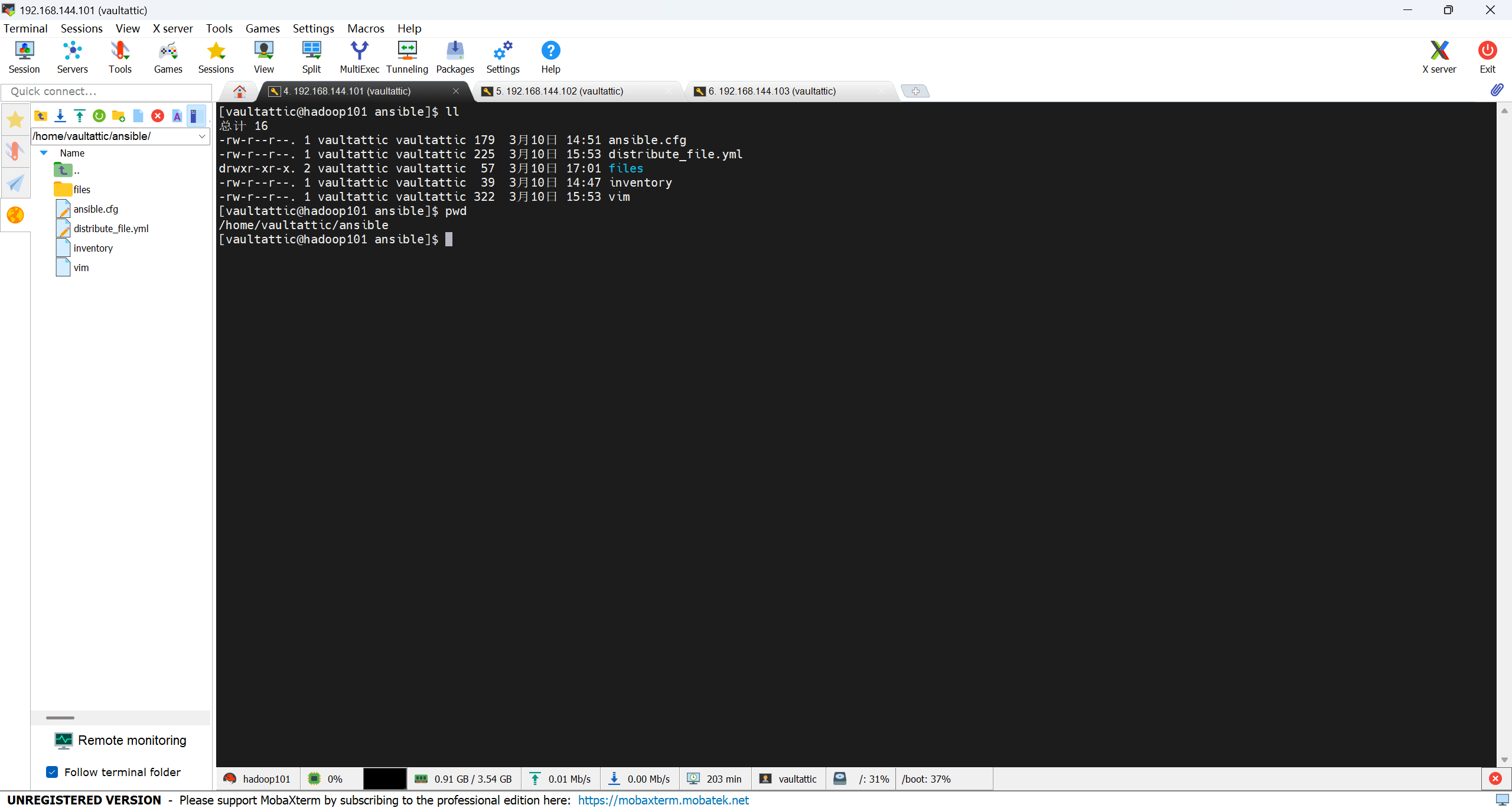
编写配置环境变量 playbook:
vim set_env.yml
---
- name: Configure environment variables
hosts: hadoop
vars:
env_name: JAVA_HOME
env_path: /opt/amazon-corretto-8
tasks:
- name: Add environment variables to ~/.bashrc
lineinfile:
path: "~/.bashrc"
line: "export {{ env_name }}={{ env_path }}"
create: yes
- name: Add PATH for {{ env_name }}
lineinfile:
path: "~/.bashrc"
line: "export PATH=${{ env_name }}/bin:$PATH"
env_name:环境变量名env_path:环境变量路径
11、安装 JDK
Hadoop 3.3.6 只支持 Java 8 和 Java 11(Hadoop Java Versions - Hadoop - Apache Software Foundation),我这里用 Java 8 的 JDK。
这里用 OpenJDK 的发行版 Corretto 8,下载地址:Downloads for Amazon Corretto 8 - Amazon Corretto 8
Corretto 8 百度网盘下载链接:https://pan.baidu.com/s/1rluJoZhO2aQOXQebesJ9Rw?pwd=lny9
下载好后在 MobeXterm 左边侧栏的文件浏览器中进入 /home/vaultattic/ansible/files 目录(也可以放别的目录),把下载好的压缩包拖进去上传虚拟机。
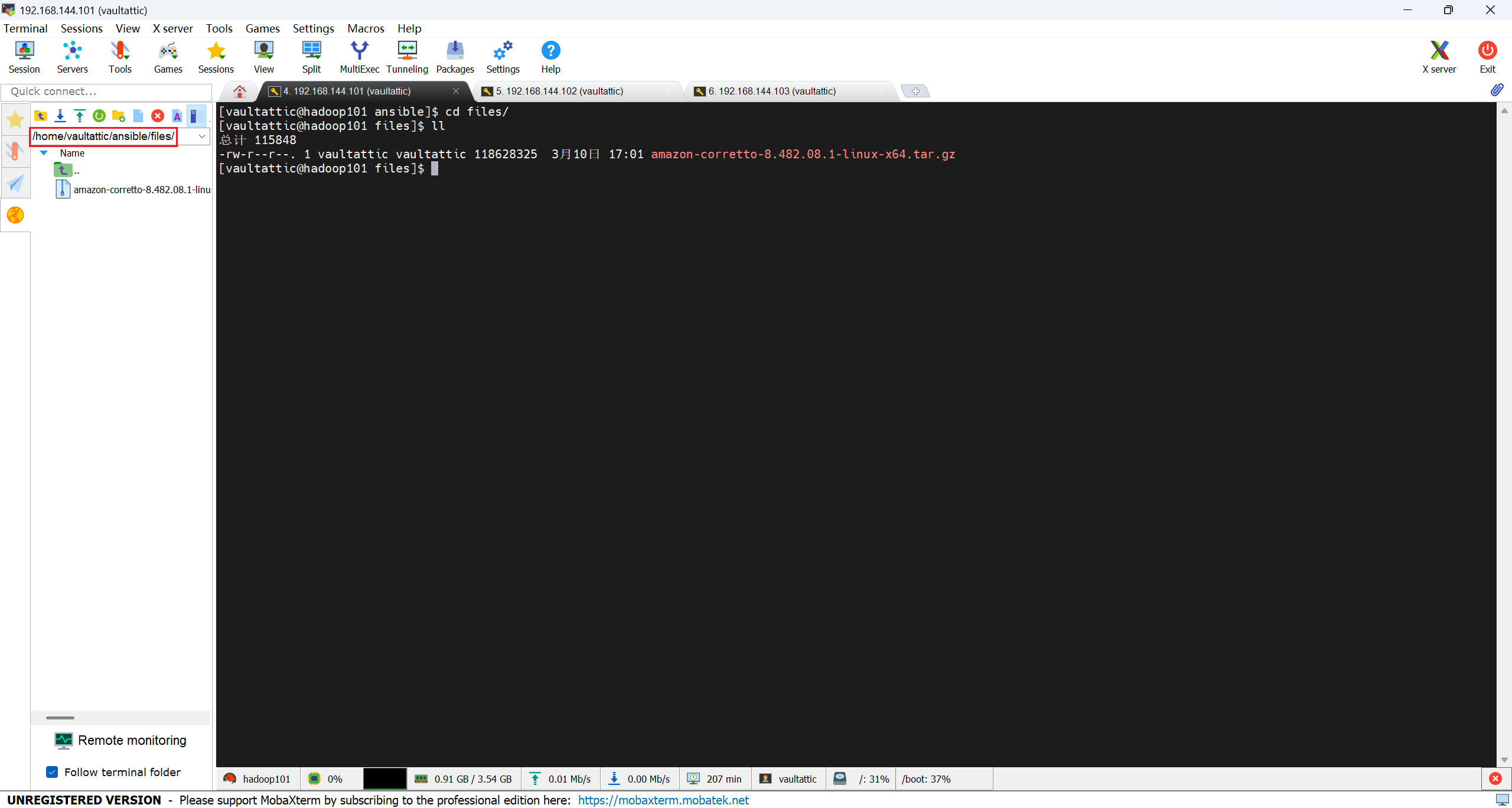
复制文件名,将之前写好的 deploy_package.yml 中的变量进行替换。
替换后的 deploy_package.yml:
- name: Deploy package
hosts: hadoop
vars:
pkg_name: amazon-corretto-8.482.08.1-linux-x64.tar.gz
dest_dir: amazon-corretto-8
tasks:
- name: Copy archive
copy:
src: "./files/{{ pkg_name }}"
dest: "/opt/{{ pkg_name }}"
- name: Get top directory name from archive
shell: tar -tf /opt/{{ pkg_name }} | head -1 | cut -d/ -f1
register: archive_dir
- name: Extract archive
command: tar -xzf /opt/{{ pkg_name }} -C /opt
- name: Rename directory
command: mv /opt/{{ archive_dir.stdout | trim }} /opt/{{ dest_dir }}
args:
creates: /opt/{{ dest_dir }}
- name: Change ownership
file:
path: "/opt/{{ dest_dir }}"
owner: vaultattic
group: vaultattic
recurse: yes
- name: Remove archive
file:
path: "/opt/{{ pkg_name }}"
state: absent
运行 deploy_package.yml:
ansible-playbook deploy_package.yml
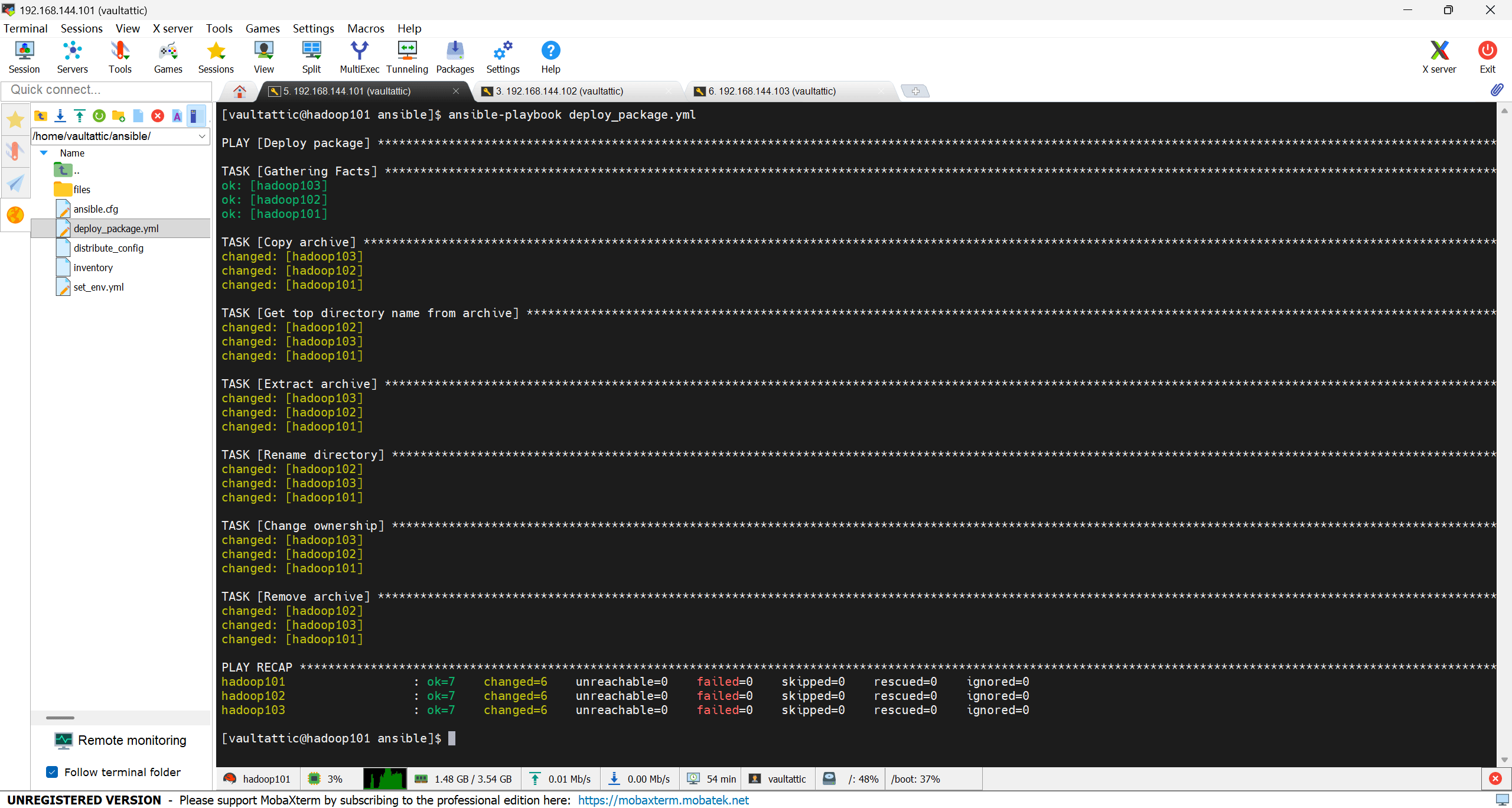
执行完后可以在各节点的 /opt 目录下查看 JDK 目录是否存在。
使用 set_env.yml 配置 JAVA_HOME 环境变量。
复制要配置环境变量的目录路径,将 set_env.yml 中的变量进行替换:
---
- name: Configure environment variables
hosts: hadoop
vars:
env_name: JAVA_HOME
env_path: /opt/amazon-corretto-8
tasks:
- name: Add environment variables to /home/vaultattic/.bashrc
lineinfile:
path: "/home/vaultattic/.bashrc"
line: "export {{ env_name }}={{ env_path }}"
create: yes
- name: Add PATH for {{ env_name }}
lineinfile:
path: "/home/vaultattic/.bashrc"
line: "export PATH=${{ env_name }}/bin:$PATH"
运行 set_env.yml:
ansible-playbook set_env.yml
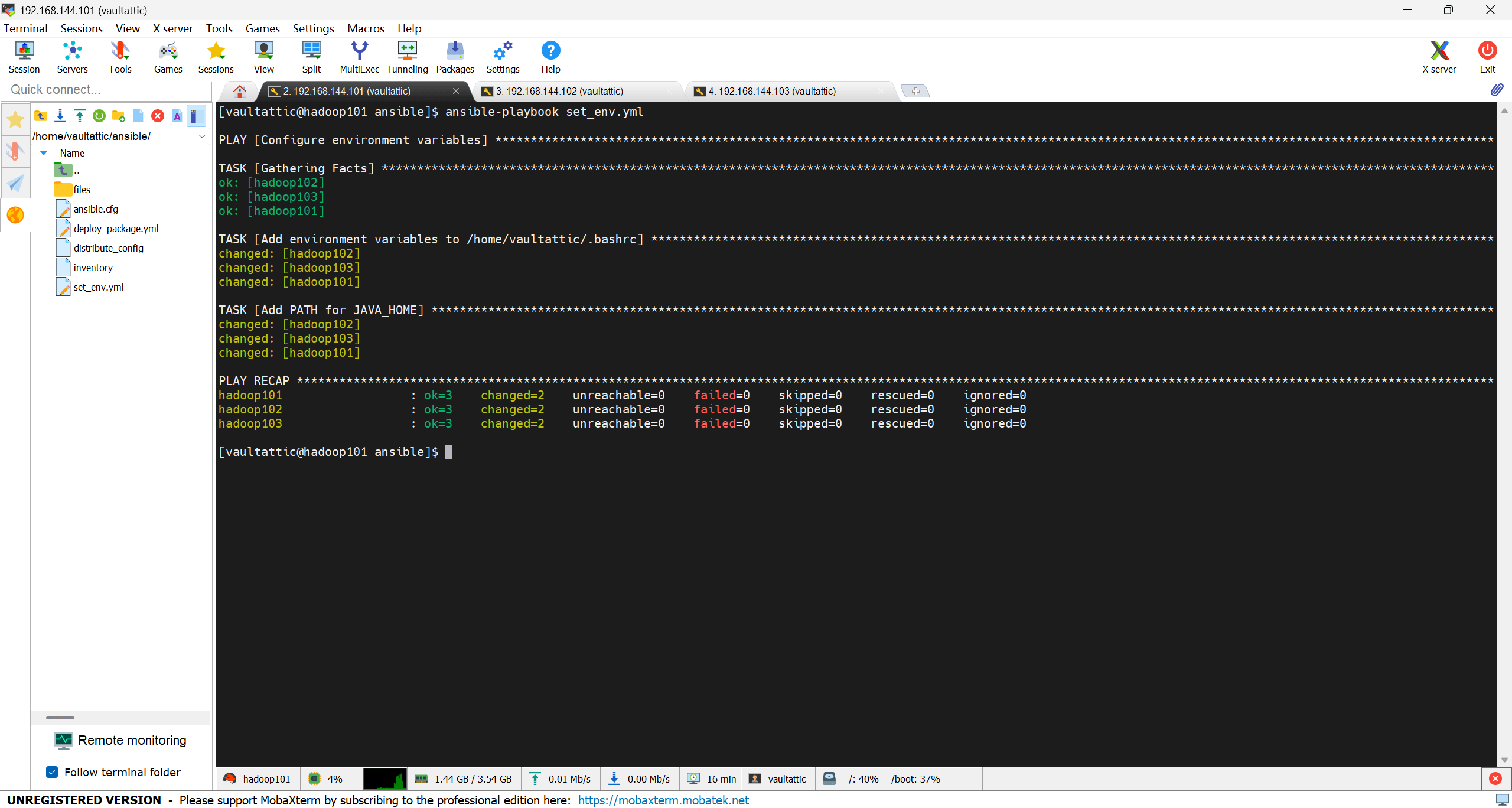
执行 playbook 后使用:
source ~/.bashrc
java -version
[vaultattic@hadoop101 ansible]$ source ~/.bashrc
java -version
openjdk version "1.8.0_482"
OpenJDK Runtime Environment Corretto-8.482.08.1 (build 1.8.0_482-b08)
OpenJDK 64-Bit Server VM Corretto-8.482.08.1 (build 25.482-b08, mixed mode)
[vaultattic@hadoop101 ansible]$
验证环境变量是否添加成功。
12、安装 MySQL 数据库
Linux-CentOS Stream 安装 MySQL - 滕王阁 这是我之前写的,Rocky Linux 和 CentOS Stream 都是 RedHat 系的 Linux 发行版,所以都是通用的。
这里再简单赘述一遍。
在线安装 MySQL 数据库,命令行输入:
sudo yum localinstall https://dev.mysql.com/get/mysql84-community-release-el10-2.noarch.rpm
sudo yum install mysql-community-server
启动 MySQL 数据库:
sudo systemctl start mysqld
修改数据库密码
由于 MySQL 8.0+ 版本的设置,在安装时会自动分配一个复杂密码并且修改的密码也必须是复杂密码,改变密码策略为 "LOW" 还必须先设置一次复杂的初始密码😥。
查看 MySQL 第一次运行时生成的临时密码:
sudo grep "A temporary password" /var/log/mysqld.log
[vaultattic@hadoop101 ~]$ sudo grep "A temporary password" /var/log/mysqld.log
2026-03-11T12:27:20.354476Z 6 [Note] [MY-010454] [Server] A temporary password is generated for root@localhost: su#eU4_ti.iB
比如这里我的临时密码就是:su#eU4_ti.iB
现在将这个密码改为一个简单的密码。
使用 MySQL 的 root 用户登录 MySQL 命令行:
mysql -u root -p
设置一个复杂的初始密码:
ALTER USER 'root'@'localhost' IDENTIFIED BY 'Root123!';
查看密码验证相关变量名:
SHOW VARIABLES LIKE 'validate_password%';
查看变量名是 validate_password_policy / validate_password_length 还是 validate_password.policy=0 / validate_password.length。早期 8.0 版本是前面那个下划线版本的,后面的新 8.0 版本变成小数点了,我下的这个最新的是小数点版本😑。
在 MySQL 命令行中分别设置密码策略为 "LOW" 和最短密码长度为 6:
SET GLOBAL validate_password.policy=0;
set GLOBAL validate_password.length=6;
设置一个简单密码:
ALTER USER 'root'@'localhost' IDENTIFIED BY '123456';
设置数据库 root 用户远程登录
把 MySQL 的 root 用户改成允许远程连接(这里我看老师用的 5.0 版本和我的又不一样🧐):
CREATE USER 'root'@'%' IDENTIFIED BY '123456';
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' WITH GRANT OPTION;
FLUSH PRIVILEGES;
实际上是创建了一个新的用于远程登录的 root 用户。
退出 MySQL 命令行:
quit
15、编辑模拟数据生成配置文件
下面生成用于后续数据处理的模拟数据,不用关心数据怎么来的,只要先把它生成出来。
hadoop101 上执行:
sudo mkdir /opt/data_mocker
sudo chown vaultattic:vaultattic /opt/data_mocker
将模拟数据生成相关的文件拖进去。
相关文件百度网盘下载(我也不知道能不能发,这好像是尚硅谷的教程,但我们老师都能该都不改直接发给我们我觉得也没关系😗):https://pan.baidu.com/s/19cj6_kKnWwYWottLuTsszg?pwd=au9u
修改 application.yml,根据需求生成对应日期的用户行为日志:
vim /opt/data_mocker/application.yml
# 外部配置打开
logging.config: "/opt/data_mocker/logback.xml"
#业务日期
mock.date: "2022-02-22"
#模拟数据发送模式
mock.type: "log"
#mock.type: "http"
#mock.type: "kafka"
#http模式下,发送的地址
mock.url: "http://localhost:8090/applog"
spring:
datasource:
type: com.alibaba.druid.pool.DruidDataSource
druid:
url: jdbc:mysql://hadoop101:3306/edu?characterEncoding=utf-8&useSSL=false&serverTimezone=GMT%2B8
username: root
password: "123456"
driver-class-name: com.mysql.jdbc.Driver
max-active: 200
test-on-borrow: true
mybatis-plus.global-config.db-config.field-strategy: not_null
mybatis-plus:
mapper-locations: classpath:mapper/*.xml
mybatis:
mapper-locations: classpath:mapper/*.xml
mock:
kafka-server: "hdp1:9092,hdp2:9092,hdp3:9092"
kafka-topic: "ODS_BASE_LOG"
# 清空业务数据
mock.clear.busi: 0
# 清空用户
mock.clear.user: 0
#是否初始化试卷
mock.if-init-paper: 0
# 生成新用户
mock.new.user: 50
#启动次数
mock.user-session.count: 1000
#设备最大值
mock.max.mid: 1000
mock.if-realtime: 0
#访问时间分布权重
mock.start-time-weight: "10:5:0:0:0:0:5:5:5:10:10:15:20:10:10:10:10:10:20:25:30:35:30:20"
#支付类型占比 支付宝 :微信 :银联
mock.payment_type_weight: "40:50:10"
#课程最大值
mock.max.course-id: 10
#页面平均访问时间
mock.page.during-time-ms: 20000
#错误概率 百分比
mock.error.rate: 3
#每条日志发送延迟 ms
mock.log.sleep: 100
#课程详情来源 用户查询,商品推广,智能推荐, 促销活动
mock.detail.source-type-rate: "40:25:15:20"
#领取购物券概率
mock.if_get_coupon_rate: 75
#优惠券最大id
mock.max.coupon-id: 3
#搜索关键词
mock.search.keyword: "java,python,多线程,前端,数据库,大数据,hadoop,flink"
#男性比例
mock.user.male-rate: 20
#用户数据变化概率
mock.user.update-rate: 20
# 男女浏览商品比重(35sku)
mock.course-weight.male: "10:10:10:10:10:10:10:5:5:5:5:5:10:10:10:10:12:12:12:12:12:5:5:5:5:3:3:3:3:3:3:3:3:10:10"
mock.course-weight.female: "1:1:1:1:1:1:1:5:5:5:5:5:1:1:1:1:2:2:2:2:2:8:8:8:8:15:15:15:15:15:15:15:15:1:1"
记得把 password 栏改为自己数据库(不是 Linux 的 root 用户)的 root 密码。
修改 path.json,该文件用来配置访问路径:
vim /opt/data_mocker/path.json
{ "visit_path" : [
{"path":["start_app","home","course_list","course_detail" ,"order","payment" ,"end" ],"rate":20},
{"path":["start_app","home","course_list","course_detail" ,"order" ,"end" ],"rate":20},
{"path":["start_app","home","course_list","course_detail" ,"course_list","course_detail" ,"order" ,"end" ],"rate":20},
{"path":["start_app","home","course_list","course_detail","cart" ,"order" ,"payment" ,"end" ],"rate":20}
],
"study_path": [
{"path":["start_app","mine","course_detail","chapter_video","end" ],"rate":10},
{"path":["start_app","mine","course_detail","exam","end" ],"rate":10}
]
}
没啥可改的,我也看不懂......😗
修改 logback.xml 配置文件:
vim /opt/data_mocker/logback.xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<property name="LOG_HOME" value="/opt/data_mocker/log" />
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%msg%n</pattern>
</encoder>
</appender>
<appender name="rollingFile" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG_HOME}/app.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_HOME}/app.%d{yyyy-MM-dd}.log</fileNamePattern>
</rollingPolicy>
<encoder>
<pattern>%msg%n</pattern>
</encoder>
</appender>
<!-- 将某一个包下日志单独打印日志 -->
<logger name="com.atguigu.mock.util.LogUtil"
level="INFO" additivity="false">
<appender-ref ref="rollingFile" />
<appender-ref ref="console" />
</logger>
<root level="error" >
<appender-ref ref="console" />
<!-- <appender-ref ref="async-rollingFile" /> -->
</root>
</configuration>
16、将数据导入数据库
在终端运行两条命令:
mysql -u root -p -e "create database edu charset utf8 default collate utf8_general_ci;"
mysql -u root -p -D edu < /opt/data_mocker/edu0222.sql
17、创建业务生成脚本
将脚本放在用户 home 目录的 bin 目录下,以便随时访问:
mkdir ~/bin
vim ~/bin/mock.sh
#!/bin/bash
DATA_HOME=/opt/data_mocker
MAXWELL_HOME=/opt/maxwell
function mock_data() {
if [ $1 ]
then
sed -i "/mock.date/s/.*/mock.date: \"$1\"/" $DATA_HOME/application.yml
echo "正在生成 $1 当日的数据"
fi
cd $DATA_HOME
nohup java -jar "edu2021-mock-2022-06-18.jar" >/dev/null 2>&1
}
case $1 in
"init")
[ $2 ] && do_date=$2 || do_date='2022-02-21'
sed -i "/mock.clear.busi/s/.*/mock.clear.busi: 1/" $DATA_HOME/application.yml
sed -i "/mock.clear.user/s/.*/mock.clear.user: 1/" $DATA_HOME/application.yml
mock_data $(date -d "$do_date -5 days" +%F)
sed -i "/mock.clear.busi/s/.*/mock.clear.busi: 0/" $DATA_HOME/application.yml
sed -i "/mock.clear.user/s/.*/mock.clear.user: 0/" $DATA_HOME/application.yml
for ((i=4;i>=0;i--));
do
mock_data $(date -d "$do_date -$i days" +%F)
done
;;
[0-9][0-9][0-9][0-9]-[0-1][0-9]-[0-3][0-9])
# sed -i "/mock_date/s/.*/mock_date=$1/" $MAXWELL_HOME/config.properties
# mxw.sh restart
sleep 1
mock_data $1
;;
esac
修改脚本执行权限:
chmod +x ~/bin/mock.sh
测试脚本:
mock.sh init 2022-02-21
[vaultattic@hadoop101 ~]$ mock.sh init 2022-02-21
正在生成 2022-02-16 当日的数据
正在生成 2022-02-17 当日的数据
正在生成 2022-02-18 当日的数据
正在生成 2022-02-19 当日的数据
正在生成 2022-02-20 当日的数据
正在生成 2022-02-21 当日的数据
[vaultattic@hadoop101 ~]$
查看生成的数据:
ls /opt/data_mocker/log
[vaultattic@hadoop101 ~]$ ls /opt/data_mocker/log
app.log
[vaultattic@hadoop101 ~]$
如果看到 app.log 就成功了😘。
三、数据采集模块环境配置
1、编写集群进程查看脚本
同样将其放在用户 home 目录的 bin 目录下:
vim ~/bin/cluster-run.sh
#! /bin/bash
for i in hadoop101 hadoop102 hadoop103
do
echo --------- $i ----------
ssh $i "$*"
done
修改脚本执行权限:
chmod +x ~/bin/cluster-run.sh
测试脚本:
cluster-run.sh jps
[vaultattic@hadoop101 ~]$ cluster-run.sh jps
--------- hadoop101 ----------
30510 Jps
--------- hadoop102 ----------
25290 Jps
--------- hadoop103 ----------
13314 Jps
[vaultattic@hadoop101 ~]$
这个脚本就是用来在集群所有的机器上执行相同命令的。
2、安装 Hadoop
Hadoop 是一个开源的分布式计算框架,专为处理海量数据而设计。
由两大核心组件构成:HDFS(分布式文件系统),负责将大文件分块存储到成百上千台服务器上,并提供高吞吐量的数据访问;YARN(资源调度器),负责管理集群的计算资源(CPU、内存),为各类应用分配运行环境。
在此基础上,Hadoop 还提供了 MapReduce 等计算模型,让开发者能轻松编写分布式数据处理程序。经过多年发展,Hadoop 已演变成一个庞大的生态圈,围绕它诞生了 Hive(数据仓库)、HBase(NoSQL 数据库)、Spark(内存计算)等一系列工具,是大数据技术的基石。
Hadoop 各节点配置如下:
| hadoop101 | hadoop102 | hadoop103 | |
|---|---|---|---|
| HDFS | NameNodeDataNode | DataNode | SecondaryNameNodeDataNode |
| YARN | NodeManager | ResourceManagerNodeManager | NodeManager |
软件包下载
Hadoop 官网下载地址:https://hadoop.apache.org/releases.html
选个稳定一点的 3.3.6 下载(选那个 Binary download)😶🌫️。
这里再给一个百度网盘下载链接:https://pan.baidu.com/s/1rK381HG_gMvR2p5P-QFx5A?pwd=nndf
下载好后将软件压缩包使用 MobeXterm 上传到 hadoop101 的 ~/ansible/files 目录下。

和安装 JDK 的过程一样,复制文件名,将之前写好的 deploy_package.yml 中的变量进行替换。
替换后的 deploy_package.yml:
- name: Deploy package
hosts: hadoop
vars:
pkg_name: hadoop-3.3.6.tar.gz
dest_dir: hadoop-3.3.6
tasks:
- name: Copy archive
copy:
src: "./files/{{ pkg_name }}"
dest: "/opt/{{ pkg_name }}"
- name: Get top directory name from archive
shell: tar -tf /opt/{{ pkg_name }} | head -1 | cut -d/ -f1
register: archive_dir
- name: Extract archive
command: tar -xzf /opt/{{ pkg_name }} -C /opt
- name: Rename directory
command: mv /opt/{{ archive_dir.stdout | trim }} /opt/{{ dest_dir }}
args:
creates: /opt/{{ dest_dir }}
- name: Change ownership
file:
path: "/opt/{{ dest_dir }}"
owner: vaultattic
group: vaultattic
recurse: yes
- name: Remove archive
file:
path: "/opt/{{ pkg_name }}"
state: absent
运行 deploy_package.yml:
ansible-playbook deploy_package.yml
执行完后可以在各节点的 /opt 目录下查看 JDK 目录是否存在。
使用 set_env.yml 配置 HADOOP_HOME 环境变量。
复制要配置环境变量的目录路径,将 set_env.yml 中的变量进行替换(content 字段值还添加了一个 sbin 目录):
---
- name: Configure environment variables
hosts: hadoop
vars:
env_name: HADOOP_HOME
env_path: /opt/hadoop-3.3.6
tasks:
- name: Add environment variables to /home/vaultattic/.bashrc
lineinfile:
path: "/home/vaultattic/.bashrc"
line: "export {{ env_name }}={{ env_path }}"
create: yes
- name: Add PATH for {{ env_name }}
lineinfile:
path: "/home/vaultattic/.bashrc"
line: "export PATH=${{ env_name }}/bin:${{ env_name }}/sbin:$PATH"
运行 set_env.yml:
ansible-playbook set_env.yml
执行 playbook 后使用:
source ~/.bashrc
hadoop version
[vaultattic@hadoop101 ansible]$ source ~/.bashrc
[vaultattic@hadoop101 ansible]$ hadoop version
Hadoop 3.3.6
Source code repository https://github.com/apache/hadoop.git -r 1be78238728da9266a4f88195058f08fd012bf9c
Compiled by ubuntu on 2023-06-18T08:22Z
Compiled on platform linux-x86_64
Compiled with protoc 3.7.1
From source with checksum 5652179ad55f76cb287d9c633bb53bbd
This command was run using /opt/hadoop-3.3.6/share/hadoop/common/hadoop-common-3.3.6.jar
[vaultattic@hadoop101 ansible]$
验证环境变量是否添加成功。
集群环境配置
配置 core-site.xml
编辑配置文件:
cd $HADOOP_HOME/etc/hadoop
vim core-site.xml
在 <configuration> 中添加:
<!-- 指定 NameNode 的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop101:8020</value>
</property>
<!-- 指定 Hadoop 数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-3.3.6/data</value>
</property>
<!-- 配置 HDFS Web 登录使用的静态用户 -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>vaultattic</value>
</property>
<!-- 配置 superUser(vaultattic) 允许通过代理访问的主机 -->
<property>
<name>hadoop.proxyuser.vaultattic.hosts</name>
<value>*</value>
</property>
<!-- 配置 superUser(vaultattic) 允许代理的用户组 -->
<property>
<name>hadoop.proxyuser.vaultattic.groups</name>
<value>*</value>
</property>
<!-- 配置 superUser(vaultattic) 允许代理的用户 -->
<property>
<name>hadoop.proxyuser.vaultattic.users</name>
<value>*</value>
</property>
配置 hdfs-site.xml
编辑配置文件:
cd $HADOOP_HOME/etc/hadoop
vim hdfs-site.xml
在 <configuration> 中添加:
<!-- NameNode Web UI 访问地址 -->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop101:9870</value>
</property>
<!-- SecondaryNameNode Web UI 访问地址 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop103:9868</value>
</property>
<!-- HDFS 副本数量 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 关闭 HDFS 文件权限检查 -->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
配置 yarn-site.xml
编辑配置文件:
cd $HADOOP_HOME/etc/hadoop
vim yarn-site.xml
在 <configuration> 中添加:
<!-- 指定 MR 使用 shuffle 服务 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定 ResourceManager 的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop102</value>
</property>
<!-- 环境变量继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>
JAVA_HOME,
HADOOP_COMMON_HOME,
HADOOP_HDFS_HOME,
HADOOP_CONF_DIR,
CLASSPATH_PREPEND_DISTCACHE,
HADOOP_YARN_HOME,
HADOOP_MAPRED_HOME
</value>
</property>
<!-- YARN 容器允许分配的最小和最大内存 -->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4096</value>
</property>
<!-- NodeManager 可管理的物理内存 -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value>
</property>
<!-- 关闭 YARN 对物理内存和虚拟内存的检查 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
配置 mapred-site.xml
编辑配置文件:
cd $HADOOP_HOME/etc/hadoop
vim mapred-site.xml
在 <configuration> 中添加:
<!-- 指定 MapReduce 程序运行在 YARN 上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
配置 workers
编辑配置文件:
cd $HADOOP_HOME/etc/hadoop
vim workers
将内容修改为(去掉自带的 localhost):
hadoop101
hadoop102
hadoop103
历史服务器配置
历史服务器是 Hadoop MapReduce 里的一个服务,用来查看已经完成的 MapReduce 任务信息。
MapReduce 任务运行结束后,任务的信息不会保存在 Yarn 里,而是由历史服务器负责保存和展示。
如果没有历史服务器,作业完成后,在 Yarn 的 Web UI 里就看不到详细信息了。
编辑 mapred-site.xml 配置文件:
cd $HADOOP_HOME/etc/hadoop
vim mapred-site.xml
在 <configuration> 中添加:
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop101:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop101:19888</value>
</property>
日志聚集配置
**日志聚集(Log Aggregation)**是 YARN 提供的一种机制,用于将各个节点上分散的应用日志统一收集并上传到 HDFS,方便用户集中查看和排查问题。
在 YARN 中,任务运行在不同节点上,其日志默认存储在各节点本地。
日志聚集功能可以在任务完成后,将这些分散的日志统一收集并上传到 HDFS,实现集中管理,避免日志丢失,并方便用户通过命令行或 Web UI 查看日志。
编辑 yarn-site.xml 配置文件:
cd $HADOOP_HOME/etc/hadoop
vim yarn-site.xml
在 <configuration> 中添加:
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop101:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
分发配置文件
刚刚我配置需要同步到所以节点的 Hadoop 配置中。
在 Ansible 工作目录创建一个用于分发配置的 playbook:
cd ~/ansible
vim distribute_config.yml
---
- name: Distribute Hadoop config files
hosts: hadoop
vars:
files:
- core-site.xml
- hdfs-site.xml
- yarn-site.xml
- mapred-site.xml
- workers
tasks:
- name: Copy Hadoop config files
copy:
src: "/opt/hadoop-3.3.6/etc/hadoop/{{ item }}"
dest: "/opt/hadoop-3.3.6/etc/hadoop/{{ item }}"
owner: vaultattic
group: vaultattic
mode: '0644'
loop: "{{ files }}"
运行 playbook:
ansible-playbook distribute_config.yml
可以用之前写的 cluster-run.sh 脚本查看是否替换成功:
cluster-run.sh "
cat $HADOOP_HOME/etc/hadoop/core-site.xml
echo
cat $HADOOP_HOME/etc/hadoop/hdfs-site.xml
echo
cat $HADOOP_HOME/etc/hadoop/yarn-site.xml
echo
cat $HADOOP_HOME/etc/hadoop/mapred-site.xml
echo
cat $HADOOP_HOME/etc/hadoop/workers
echo
"
启动集群
集群第一次启动,需要在 hadoop101 节点格式化 NameNode。
hdfs namenode -format
启动 HDFS:
start-dfs.sh
启动 YARN:
start-yarn.sh
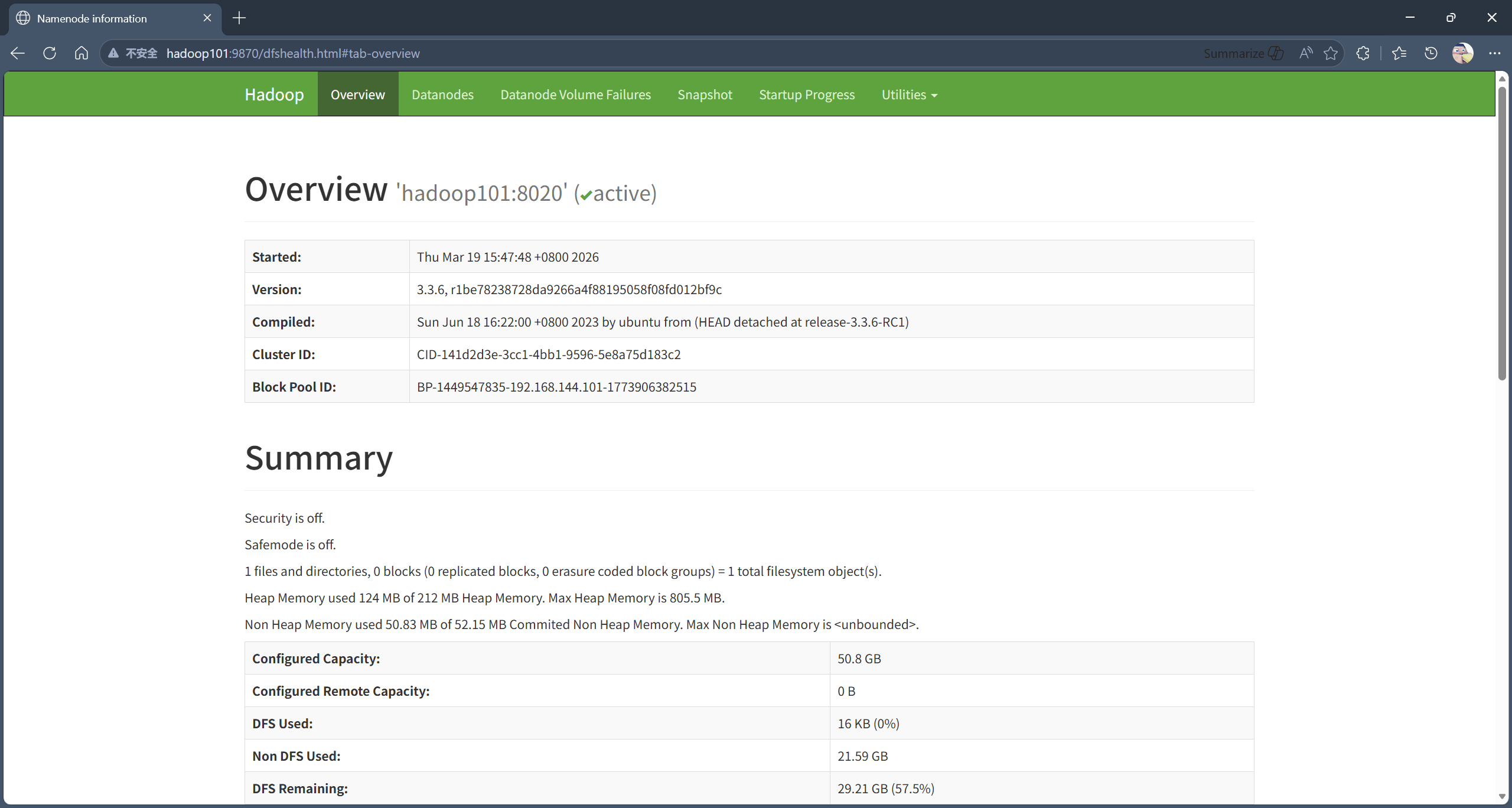
在浏览器中,查看 HDFS 的 Web 页面。
浏览器地址栏中输入:http://hadoop101:9870/
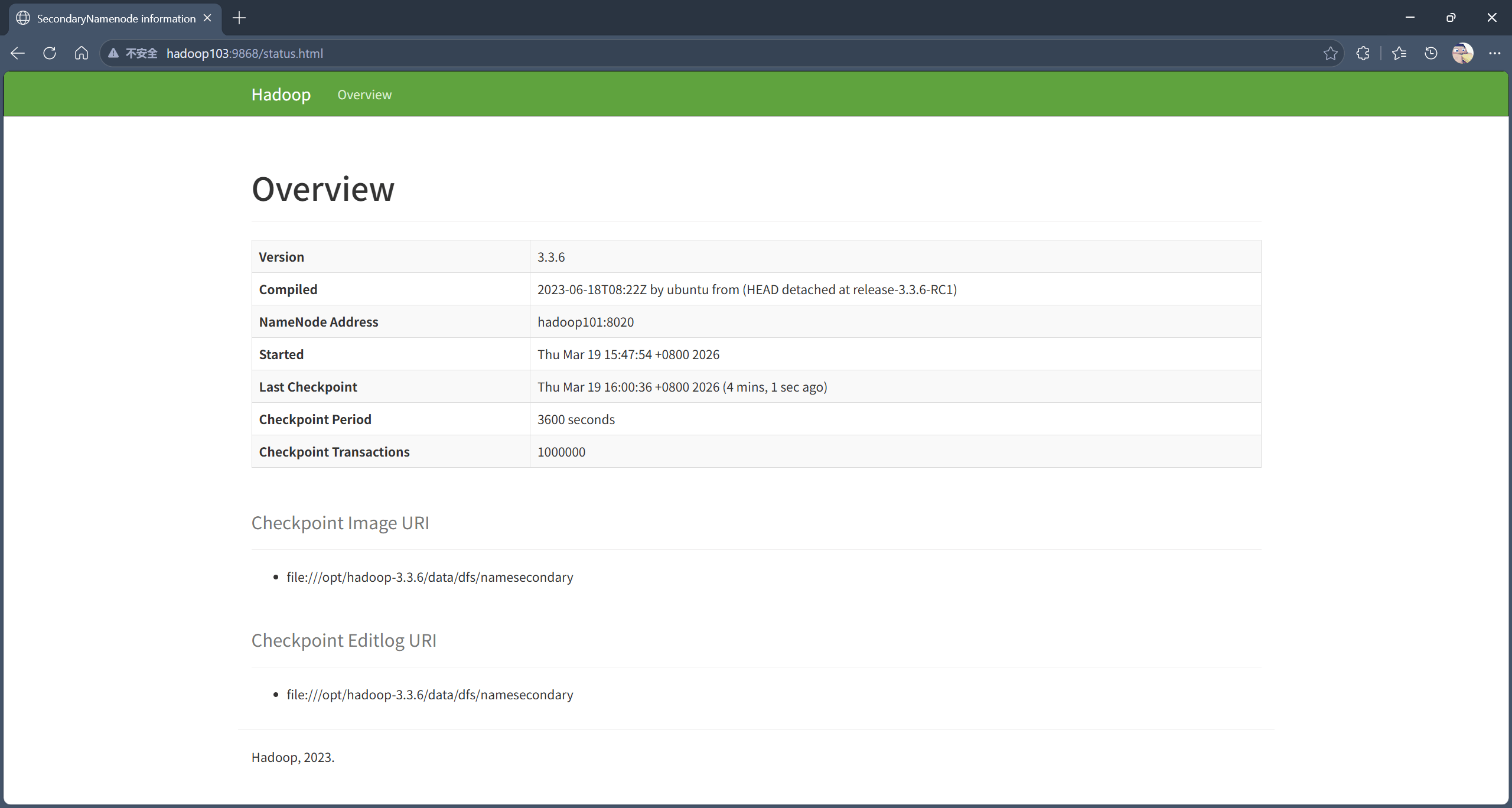
Web 端查看 SecondaryNameNode。
浏览器中输入:http://hadoop103:9868/status.html/
3、使用 chrony 进行集群时间同步配置
在 Hadoop 集群中,多个节点之间需要保持时间一致,否则可能会导致:
- HDFS 数据异常
- YARN 任务失败
- 日志时间混乱,难以排查问题
因此,搭建 Hadoop 集群之前,最好进行时间同步配置。
注意,如果使用的是 CentOS 7 这种老旧的 Linux 发行版,使用的默认时间同步软件是 NTP,但现在已经逐渐被 chrony 所取代🤔。
我自己用的 Rocky Linux 10 就是 chrony,配置方式会和 NTP 有很大不同。这和两个软件的工作方式有很大关系,chrony 是持续进行同步,而 NTP 是定时同步,所有在配置 NTP 教程里可以看到配置同步间隔为 10 分钟,而配置 chrony 则不需要🧐。
配置时间同步的集群关系如下:
hadoop101 192.168.144.101 (时间服务器)
hadoop102 192.168.144.102 (客户端)
hadoop103 192.168.144.103 (客户端)
配置时间服务器(hadoop101)
在 hadoop101 上修改配置 chrony 配置文件:
sudo vim /etc/chrony.conf
在默认配置基础上,做这两处修改。
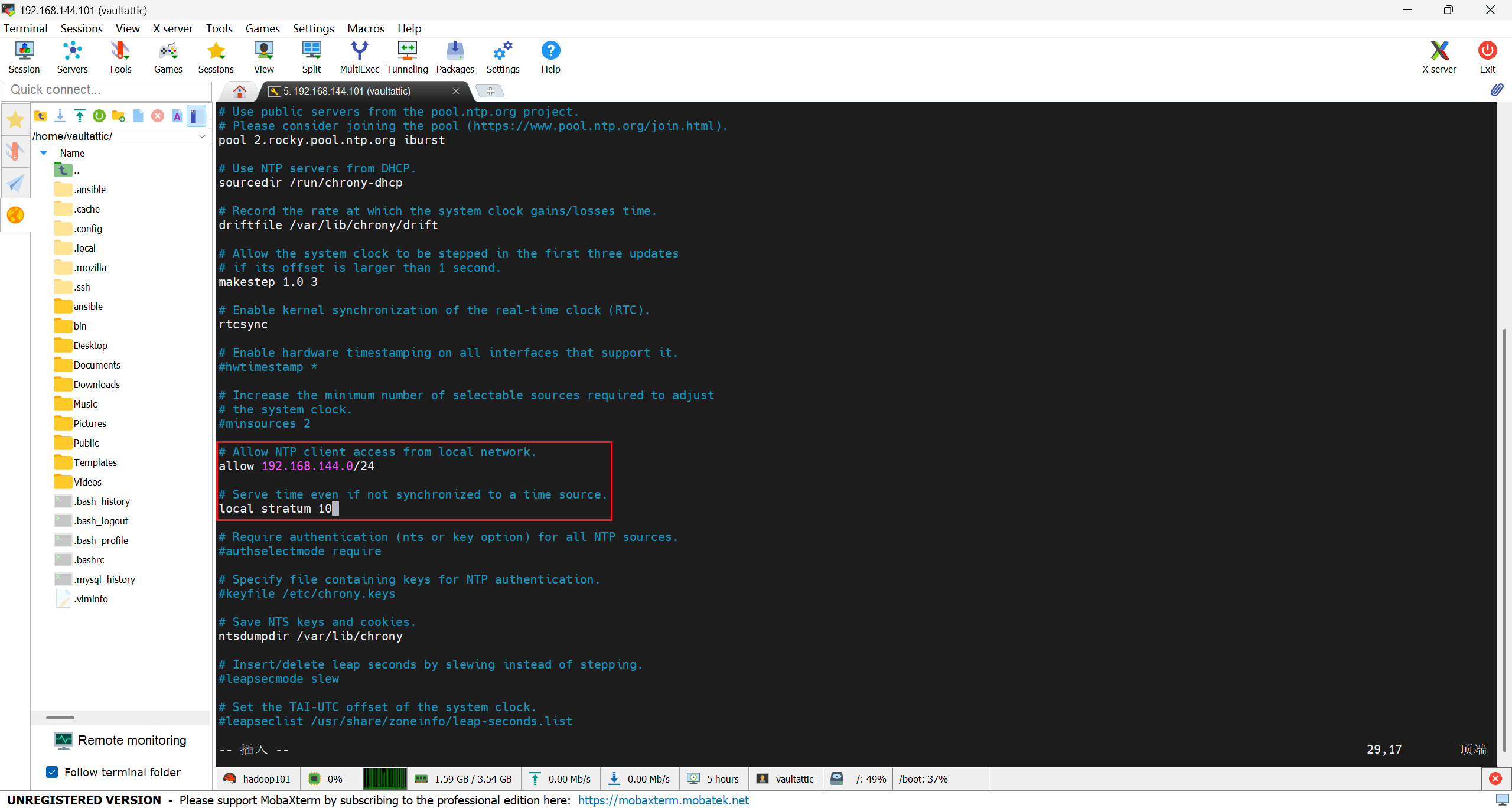
放开内网访问(取消注释并改网段),找到 #allow 192.168.0.0/16 这一行,去掉注释改成(其中 IP 地址的第三位 144 这个数字改为你自己虚拟机 IP 地址的第三位):
allow 192.168.144.0/24
开启本地兜底(正常是同步互联网上的时间服务器,这一步是为了在断网时仍然能和 hadoop101 的本地时间同步),找到 #local stratum 10 这一行,去掉注释改成:
local stratum 10
保存配置文件后启动服务:
sudo systemctl enable chronyd
sudo systemctl restart chronyd
验证是否配置成功:
chronyc sources -v
[vaultattic@hadoop101 ~]$ chronyc sources -v
.-- Source mode '^' = server, '=' = peer, '#' = local clock.
/ .- Source state '*' = current best, '+' = combined, '-' = not combined,
| / 'x' = may be in error, '~' = too variable, '?' = unusable.
|| .- xxxx [ yyyy ] +/- zzzz
|| Reachability register (octal) -. | xxxx = adjusted offset,
|| Log2(Polling interval) --. | | yyyy = measured offset,
|| \ | | zzzz = estimated error.
|| | | \
MS Name/IP address Stratum Poll Reach LastRx Last sample
===============================================================================
^- 84.16.73.33 1 6 203 90 +46ms[ +49ms] +/- 196ms
^* time.nju.edu.cn 1 6 377 38 +68ms[ +72ms] +/- 128ms
^- ntp5.flashdance.cx 2 6 337 37 +3025us[+3025us] +/- 175ms
^+ 119.28.206.193 2 6 377 39 +48ms[ +52ms] +/- 122ms
[vaultattic@hadoop101 ~]$
看到下面出现一大串 IP 和域名就配置成功了😋。
配置客户端(hadoop102 / hadoop103)
在 hadoop102、hadoop103 修改配置文件(记得两个都要改😘):
sudo vim /etc/chrony.conf
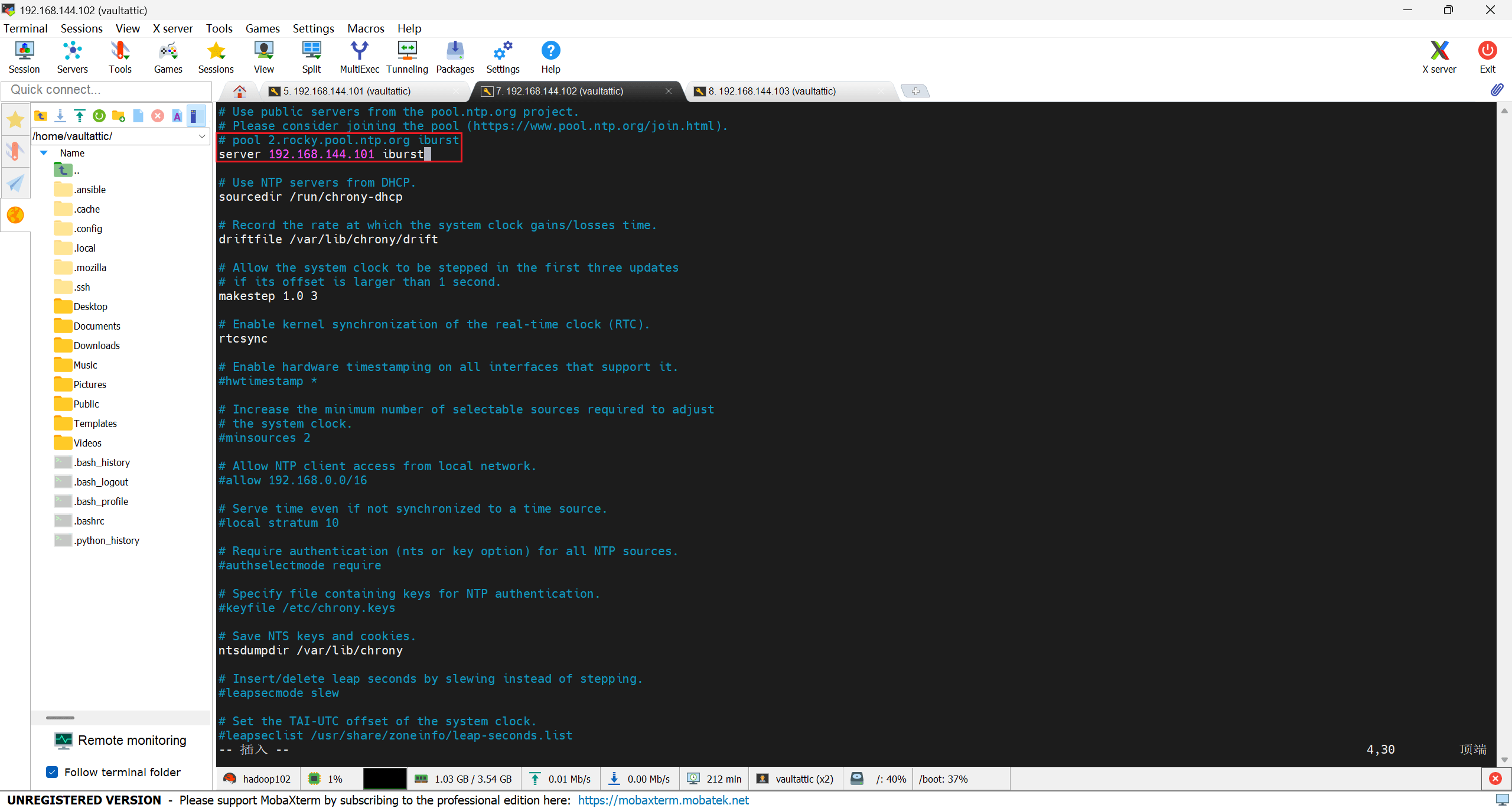
注释默认公网源(hadoop101 从互联网获取时间,hadoop102、hadoop103 从 hadoop101 获取时间),找到 pool 2.rocky.pool.ntp.org iburst 这一行,把它注释掉:
#pool 2.rocky.pool.ntp.org iburst
在注释下方添加时间服务器 hadoop101:
server 192.168.144.101 iburst
保存配置文件后启动服务:
sudo systemctl enable chronyd
sudo systemctl restart chronyd
验证是否配置成功:
chronyc sources -v
[vaultattic@hadoop102 ~]$ chronyc sources -v
.-- Source mode '^' = server, '=' = peer, '#' = local clock.
/ .- Source state '*' = current best, '+' = combined, '-' = not combined,
| / 'x' = may be in error, '~' = too variable, '?' = unusable.
|| .- xxxx [ yyyy ] +/- zzzz
|| Reachability register (octal) -. | xxxx = adjusted offset,
|| Log2(Polling interval) --. | | yyyy = measured offset,
|| \ | | zzzz = estimated error.
|| | | \
MS Name/IP address Stratum Poll Reach LastRx Last sample
===============================================================================
^* hadoop101 2 6 17 12 +11us[ -199us] +/- 49ms
[vaultattic@hadoop102 ~]$
看到下方只出现 hadoop101 就成功了😶🌫️。
我看老师给的教程里面还有一节参数调优,我看暂时用不到就省略了😥。
4、安装 ZooKeeper
ZooKeeper 是一个开源的分布式协调服务,用于分布式环境下的协调工作。
在 Hadoop 体系中,具体承担了 HDFS NameNode 和 YARN ResourceManager 的高可用切换任务,确保主备节点故障时能快速、一致地完成切换,是整个大数据平台高可用架构的关键依赖。
但是,Hadoop 本身并不依赖 ZooKeeper,但若要实现 HDFS NameNode 或 YARN ResourceManager 的高可用(HA),就需要 ZooKeeper 来协调主备切换和状态同步。
软件包下载
ZooKeeper 官网下载地址:https://zookeeper.apache.org/releases.html
最新稳定版是 3.8.6,如果想用老版本可以在下面的集合里面找,这里我就用新版了。
百度网盘下载链接:https://pan.baidu.com/s/1EzTZ1Aw0nUfy-OeuzCOcYw?pwd=xubm
下载好后将软件压缩包使用 MobeXterm 上传到 hadoop101 的 ~/ansible/files 目录下。
和前面安装软件的过程一样,复制文件名,将之前写好的 deploy_package.yml 中的变量进行替换。
替换后的 deploy_package.yml:
- name: Deploy package
hosts: hadoop
vars:
pkg_name: apache-zookeeper-3.8.6-bin.tar.gz
dest_dir: zookeeper-3.8.6
tasks:
- name: Copy archive
copy:
src: "./files/{{ pkg_name }}"
dest: "/opt/{{ pkg_name }}"
- name: Get top directory name from archive
shell: tar -tf /opt/{{ pkg_name }} | head -1 | cut -d/ -f1
register: archive_dir
- name: Extract archive
command: tar -xzf /opt/{{ pkg_name }} -C /opt
- name: Rename directory
command: mv /opt/{{ archive_dir.stdout | trim }} /opt/{{ dest_dir }}
args:
creates: /opt/{{ dest_dir }}
- name: Change ownership
file:
path: "/opt/{{ dest_dir }}"
owner: vaultattic
group: vaultattic
recurse: yes
- name: Remove archive
file:
path: "/opt/{{ pkg_name }}"
state: absent
运行 deploy_package.yml:
ansible-playbook deploy_package.yml
执行完后可以在各节点的 /opt 目录下查看 ZooKeeper 目录是否存在。
cluster-run.sh ls /opt
[vaultattic@hadoop101 ansible]$ cluster-run.sh ls /opt
--------- hadoop101 ----------
amazon-corretto-8
data_mocker
hadoop-3.3.6
zookeeper-3.8.6
--------- hadoop102 ----------
amazon-corretto-8
hadoop-3.3.6
zookeeper-3.8.6
--------- hadoop103 ----------
amazon-corretto-8
hadoop-3.3.6
zookeeper-3.8.6
[vaultattic@hadoop101 ansible]$
使用 set_env.yml 配置 ZOOKEEPER_HOME 环境变量。
复制要配置环境变量的目录路径,将 set_env.yml 中的变量进行替换:
---
- name: Configure environment variables
hosts: hadoop
vars:
env_name: ZOOKEEPER_HOME
env_path: /opt/zookeeper-3.8.6
tasks:
- name: Add environment variables to /home/vaultattic/.bashrc
lineinfile:
path: "/home/vaultattic/.bashrc"
line: "export {{ env_name }}={{ env_path }}"
create: yes
- name: Add PATH for {{ env_name }}
lineinfile:
path: "/home/vaultattic/.bashrc"
line: "export PATH=${{ env_name }}/bin:$PATH"
运行 set_env.yml:
ansible-playbook set_env.yml
执行 playbook 后使用:
source ~/.bashrc
zkServer.sh version
[vaultattic@hadoop101 ansible]$ source ~/.bashrc
[vaultattic@hadoop101 ansible]$ zkServer.sh version
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper-3.8.6/bin/../conf/zoo.cfg
Apache ZooKeeper, version 3.8.6 2026-01-28 20:28 UTC
[vaultattic@hadoop101 ansible]$
配置 zoo.cfg
cd /opt/zookeeper-3.8.6/conf
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
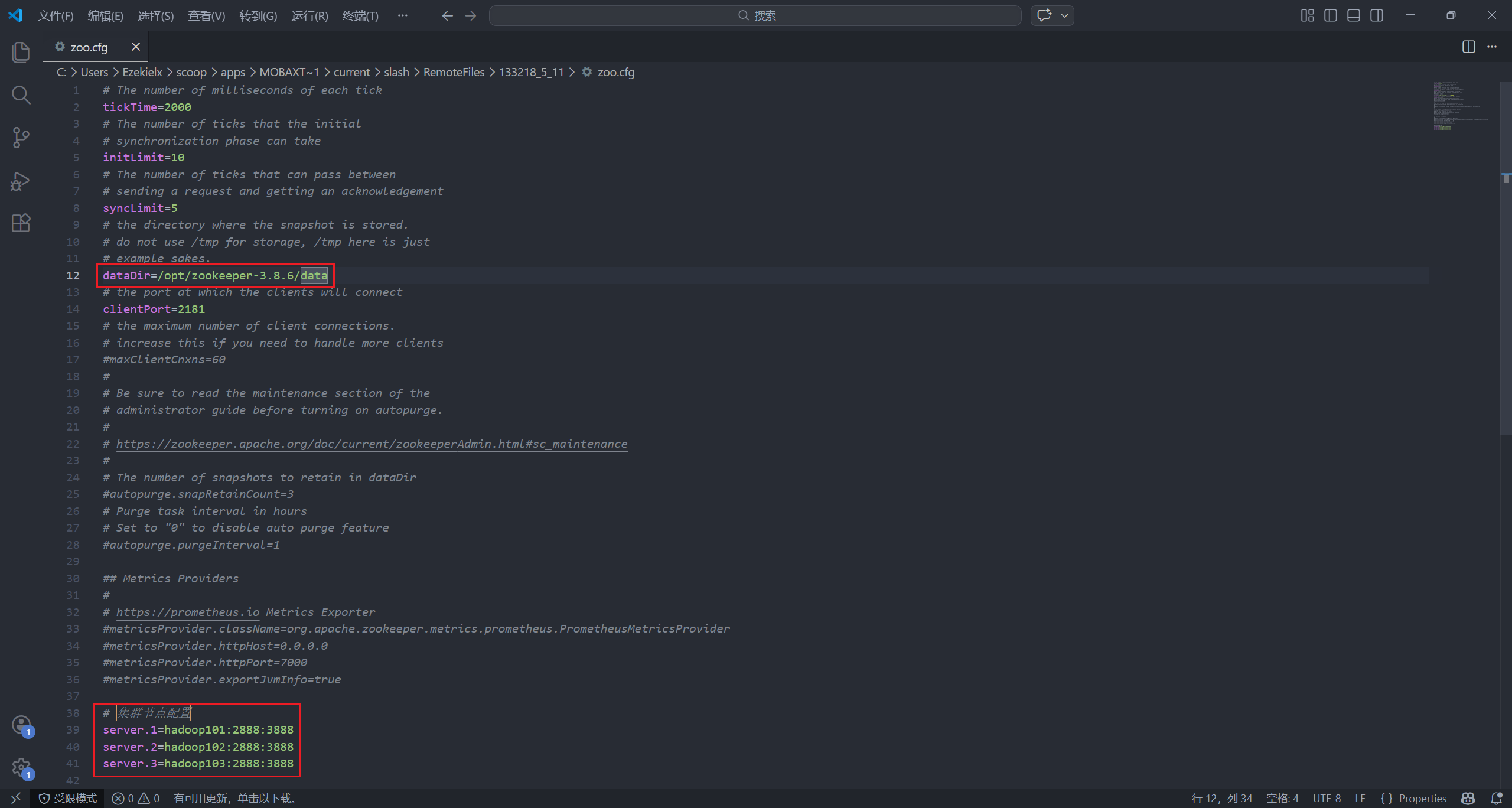
将 dataDir 行修改为:
dataDir=/opt/zookeeper-3.8.6/data
配置文件末尾添加:
# 集群节点配置
server.1=hadoop101:2888:3888
server.2=hadoop102:2888:3888
server.3=hadoop103:2888:3888
修改之前编写的 distribute_config.yml,分发配置文件。
修改后的 distribute_config.yml:
---
- name: Distribute Hadoop config files
hosts: hadoop
vars:
files:
- zoo.cfg
tasks:
- name: Copy Hadoop config files
copy:
src: "/opt/zookeeper-3.8.6/conf/{{ item }}"
dest: "/opt/zookeeper-3.8.6/conf/{{ item }}"
owner: vaultattic
group: vaultattic
mode: '0644'
loop: "{{ files }}"
运行 playbook:
ansible-playbook distribute_config.yml
配置 myid(每台机器不同)
每台机器都分别执行以下命令😡。
hadoop101:
mkdir -p /opt/zookeeper-3.8.6/data
echo 1 > /opt/zookeeper-3.8.6/data/myid
hadoop102:
mkdir -p /opt/zookeeper-3.8.6/data
echo 2 > /opt/zookeeper-3.8.6/data/myid
hadoop103:
mkdir -p /opt/zookeeper-3.8.6/data
echo 3 > /opt/zookeeper-3.8.6/data/myid
使用之前创建的脚本确认是否添加成功:
cluster-run.sh cat /opt/zookeeper-3.8.6/data/myid
[vaultattic@hadoop101 ansible]$ cluster-run.sh cat /opt/zookeeper-3.8.6/data/myid
--------- hadoop101 ----------
1
--------- hadoop102 ----------
2
--------- hadoop103 ----------
3
[vaultattic@hadoop101 ansible]$
编写 ZooKeeper 集群管理脚本
创建启动脚本:
vim ~/bin/zk-start.sh
#!/bin/bash
hosts=(hadoop101 hadoop102 hadoop103)
ZK_HOME=/opt/zookeeper-3.8.6
for host in "${hosts[@]}"
do
echo "========== $host =========="
ssh $host "$ZK_HOME/bin/zkServer.sh start"
done
echo "===== ZooKeeper 集群启动完成 ====="
创建停止脚本:
vim ~/bin/zk-stop.sh
#!/bin/bash
hosts=(hadoop101 hadoop102 hadoop103)
ZK_HOME=/opt/zookeeper-3.8.6
for host in "${hosts[@]}"
do
echo "========== $host =========="
ssh $host "$ZK_HOME/bin/zkServer.sh stop"
done
echo "===== ZooKeeper 集群已停止 ====="
创建状态检查脚本:
vim ~/bin/zk-status.sh
#!/bin/bash
hosts=(hadoop101 hadoop102 hadoop103)
ZK_HOME=/opt/zookeeper-3.8.6
for host in "${hosts[@]}"
do
echo "========== $host =========="
ssh $host "$ZK_HOME/bin/zkServer.sh status"
done
给脚本添加执行权限:
chmod +x ~/bin/zk-*.sh
测试脚本:
[vaultattic@hadoop101 ansible]$ zk-start.sh
========== hadoop101 ==========
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper-3.8.6/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
========== hadoop102 ==========
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper-3.8.6/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
========== hadoop103 ==========
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper-3.8.6/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
===== ZooKeeper 集群启动完成 =====
[vaultattic@hadoop101 ansible]$ zk-status.sh
========== hadoop101 ==========
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper-3.8.6/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
========== hadoop102 ==========
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper-3.8.6/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: leader
========== hadoop103 ==========
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper-3.8.6/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
[vaultattic@hadoop101 ansible]$ zk-stop.sh
========== hadoop101 ==========
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper-3.8.6/bin/../conf/zoo.cfg
Stopping zookeeper ... STOPPED
========== hadoop102 ==========
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper-3.8.6/bin/../conf/zoo.cfg
Stopping zookeeper ... STOPPED
========== hadoop103 ==========
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper-3.8.6/bin/../conf/zoo.cfg
Stopping zookeeper ... STOPPED
===== ZooKeeper 集群已停止 =====
[vaultattic@hadoop101 ansible]$ zk-status.sh
========== hadoop101 ==========
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper-3.8.6/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Error contacting service. It is probably not running.
========== hadoop102 ==========
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper-3.8.6/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Error contacting service. It is probably not running.
========== hadoop103 ==========
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper-3.8.6/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Error contacting service. It is probably not running.
[vaultattic@hadoop101 ansible]$
5、安装 Kafka
Kafka 可以理解成一个专门用来 “存数据并转发数据” 的系统,就像一个高性能的数据中转站。
比如:你有一个网站,用户每天会产生很多行为(登录、点击、下单)。这些数据如果直接让后台系统处理,可能会被瞬间压垮。这时候就可以先把数据写进 Kafka,Kafka 负责把这些数据 “存起来”,然后再慢慢分发给后面的系统去处理。
Kafka 和传统消息队列不一样的地方在于:它不是把数据用完就删,而是像写日志一样一条一条往后追加保存。这样做的好处是,不仅可以让多个系统同时消费同一份数据,还可以在需要的时候重新读取历史数据。
在实际的大数据架构中,Kafka通常放在最前面,作为数据入口:上游系统把数据写进 Kafka,下游的 Flink、Spark、数据库等再从 Kafka 读取数据进行计算或存储。简单来说,Kafka 就是连接各个系统的数据 “枢纽”。
Kafka 中常见名词可以简单理解为:
-
Producer:消息的生产者,也就是负责把数据发送到 Kafka 的程序。
-
Consumer:消息的消费者,也就是负责从 Kafka 中读取数据的程序
-
Topic:Kafka 中消息的分类。生产者发送消息时需要指定 Topic,消费者消费消息时也是从某个 Topic 中读取数据。例如:
order_topic:订单主题log_topic:日志主题
-
Broker:Broker 指的是 Kafka 集群中的一台服务器。
一个 Kafka 集群通常由多个 Broker 组成,共同完成消息的存储和处理。 -
Partition:Topic 的分区。
一个 Topic 可以被分成多个 Partition,用来提高并发能力和存储能力。可以理解为:Partition 是 Topic 的拆分单位。例如一个 Topic 有 3 个分区:- partition 0
- partition 1
- partition 2
-
Offset:消息在 Partition 中的位置编号。
Kafka 中的消息按顺序存储,每条消息都会有一个唯一的 offset。 -
Consumer Group:消费者组,表示多个消费者以组的方式共同消费一个 Topic。
在同一个消费者组内,一条消息只会被其中一个消费者消费。 -
Message:Kafka 中传递的数据本身。生产者发送到 Kafka 的每一条数据,都可以称为一条消息。例如:
{"orderId":1001,"amount":99.9} -
Replica:分区的副本,用来保证数据可靠性。
Kafka 会把同一个 Partition 的数据复制到多台 Broker 上,防止某台机器故障导致数据丢失。 -
Leader:分区的主副本,生产者和消费者都只和 Leader 交互。
-
Follower:分区的从副本,跟随 Leader 同步数据,当 Leader 出现故障时,Follower 可以被选举为新的 Leader。
软件包下载
Kafka 官网下载地址:https://kafka.apache.org/community/downloads/
选择 3.9.2 版本下载,不使用 4.0+ 的原因是 Kafka 4.0+ 已经移除了 ZooKeeper 模式,只支持 KRaft,如果采用 Kafka + ZooKeeper 的经典集群安装方式,只能选择 Kafka 4.0+ 以前的版本。
百度网盘下载链接:https://pan.baidu.com/s/1gRoAPRgYA1rhYH4xxpl2cw?pwd=yslb
下载好后将软件压缩包使用 MobeXterm 上传到 hadoop101 的 ~/ansible/files 目录下。
和前面安装软件的过程一样,复制文件名,将之前写好的 deploy_package.yml 中的变量进行替换。
替换后的 deploy_package.yml:
- name: Deploy package
hosts: hadoop
vars:
pkg_name: apache-flume-1.11.0-bin.tar.gz
dest_dir: flume-1.11.0
tasks:
- name: Copy archive
copy:
src: "./files/{{ pkg_name }}"
dest: "/opt/{{ pkg_name }}"
- name: Get top directory name from archive
shell: tar -tf /opt/{{ pkg_name }} | head -1 | cut -d/ -f1
register: archive_dir
- name: Extract archive
command: tar -xzf /opt/{{ pkg_name }} -C /opt
- name: Rename directory
command: mv /opt/{{ archive_dir.stdout | trim }} /opt/{{ dest_dir }}
args:
creates: /opt/{{ dest_dir }}
- name: Change ownership
file:
path: "/opt/{{ dest_dir }}"
owner: vaultattic
group: vaultattic
recurse: yes
- name: Remove archive
file:
path: "/opt/{{ pkg_name }}"
state: absent
运行 deploy_package.yml:
ansible-playbook deploy_package.yml
执行完后可以在各节点的 /opt 目录下查看 Kafka 目录是否存在。
cluster-run.sh ls /opt
[vaultattic@hadoop101 ansible]$ cluster-run.sh ls /opt
--------- hadoop101 ----------
amazon-corretto-8
data_mocker
flume-1.11.0
hadoop-3.3.6
kafka-3.9.2
zookeeper-3.8.6
--------- hadoop102 ----------
amazon-corretto-8
flume-1.11.0
hadoop-3.3.6
kafka-3.9.2
zookeeper-3.8.6
--------- hadoop103 ----------
amazon-corretto-8
flume-1.11.0
hadoop-3.3.6
kafka-3.9.2
zookeeper-3.8.6
[vaultattic@hadoop101 ansible]$
使用 set_env.yml 配置 KAFKA_HOME 环境变量。
复制要配置环境变量的目录路径,将 set_env.yml 中的变量进行替换:
---
- name: Configure environment variables
hosts: hadoop
vars:
env_name: KAFKA_HOME
env_path: /opt/kafka-3.9.2
tasks:
- name: Add environment variables to /home/vaultattic/.bashrc
lineinfile:
path: "/home/vaultattic/.bashrc"
line: "export {{ env_name }}={{ env_path }}"
create: yes
- name: Add PATH for {{ env_name }}
lineinfile:
path: "/home/vaultattic/.bashrc"
line: "export PATH=${{ env_name }}/bin:$PATH"
运行 set_env.yml:
ansible-playbook set_env.yml
执行 playbook 后使用:
source ~/.bashrc
kafka-topics.sh --version
[vaultattic@hadoop101 ansible]$ source ~/.bashrc
[vaultattic@hadoop101 ansible]$ kafka-topics.sh --version
3.9.2
[vaultattic@hadoop101 ansible]$
配置 server.properties
官网配置文档:Broker Configs | Apache Kafka 。
修改所有集群 hadoop101、hadoop102、hadoop103 的配置文件:
vim /opt/kafka-3.9.2/config/server.properties
broker.id:在 hadoop101 上改为1, hadoop102 上改为2, hadoop103 上改为3log.dirs:改为/opt/kafka-3.9.2/datazookeeper.connect:改为hadoop101:2181,hadoop102:2181,hadoop103:2181
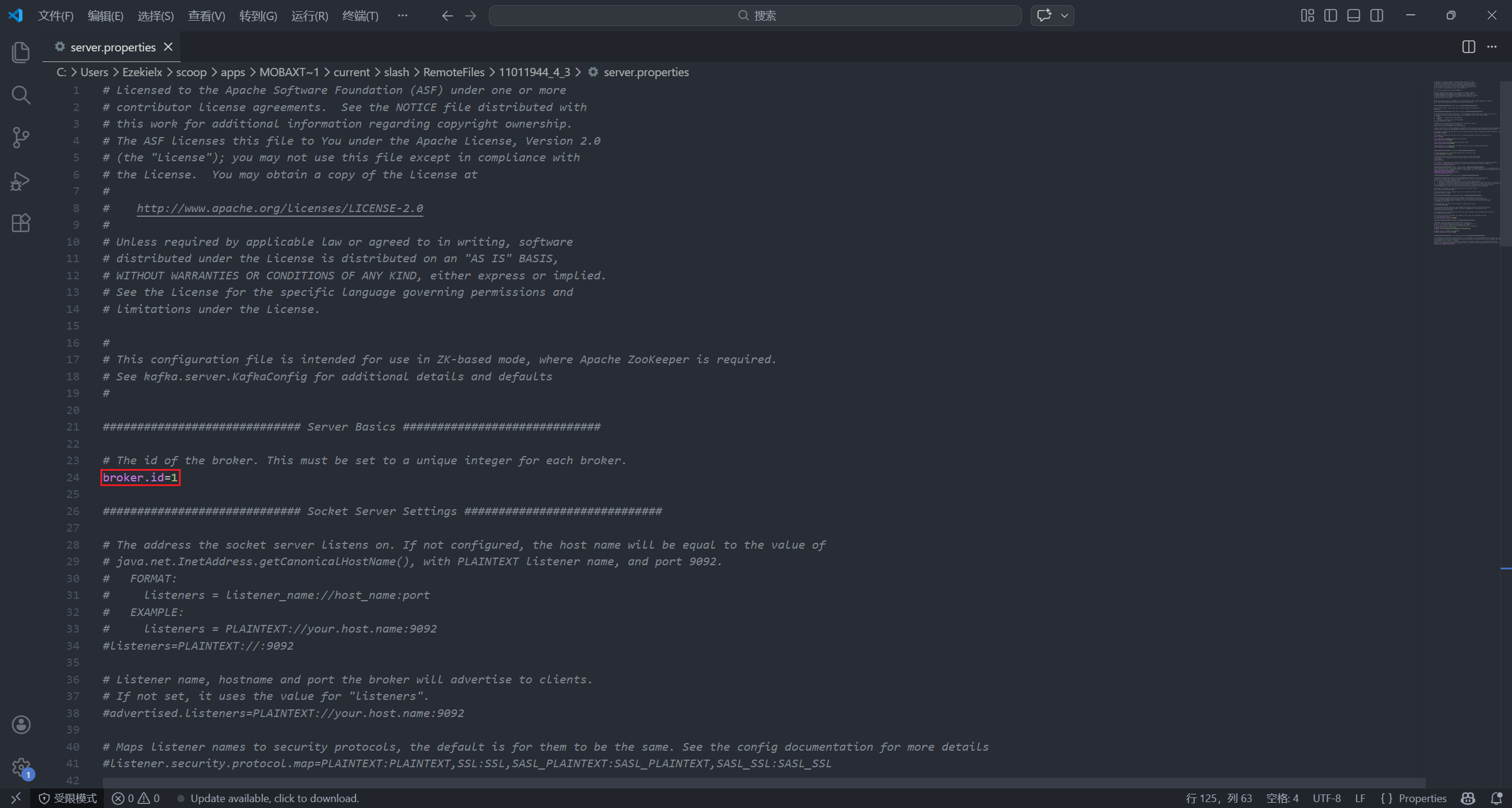
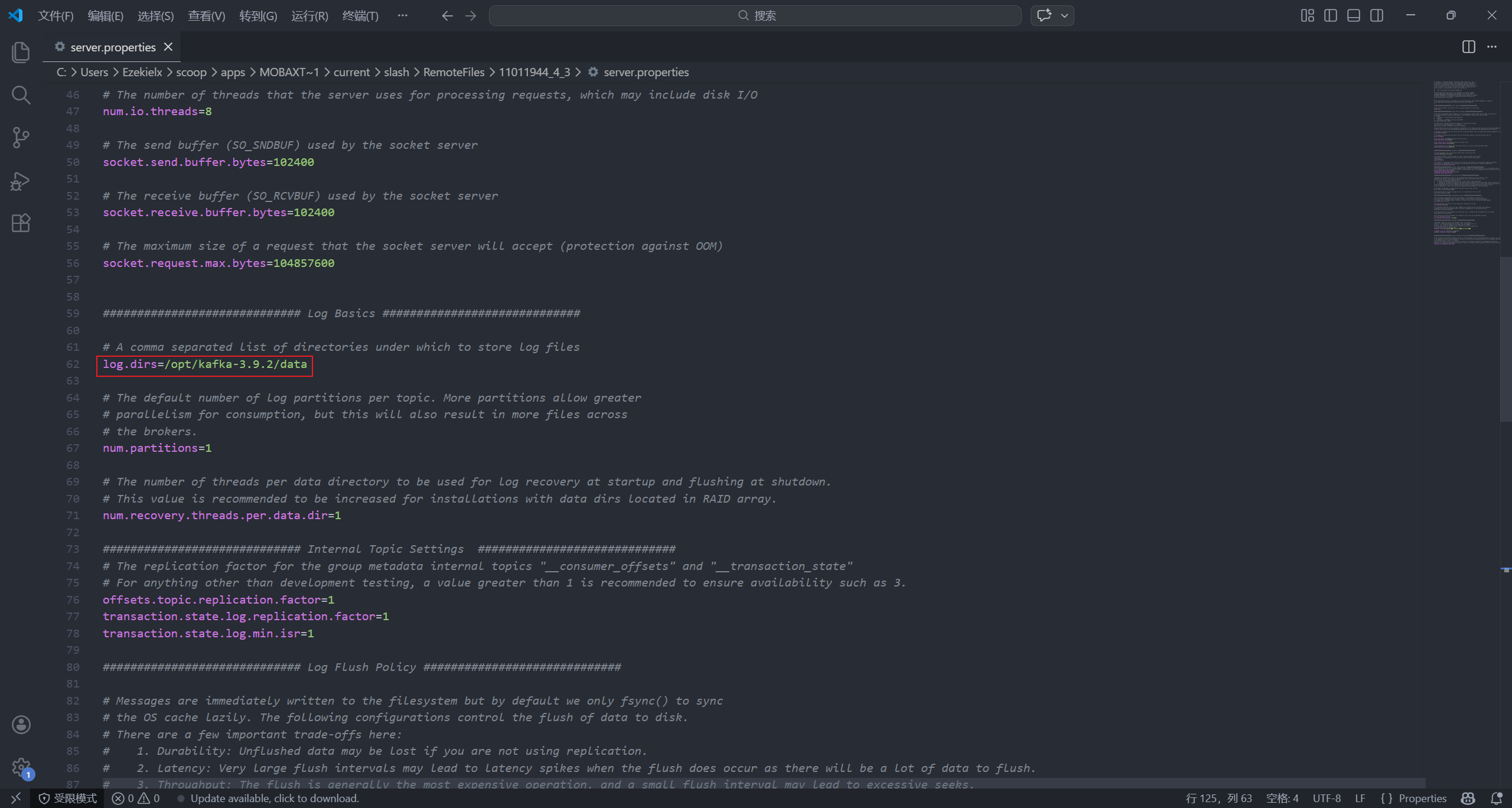
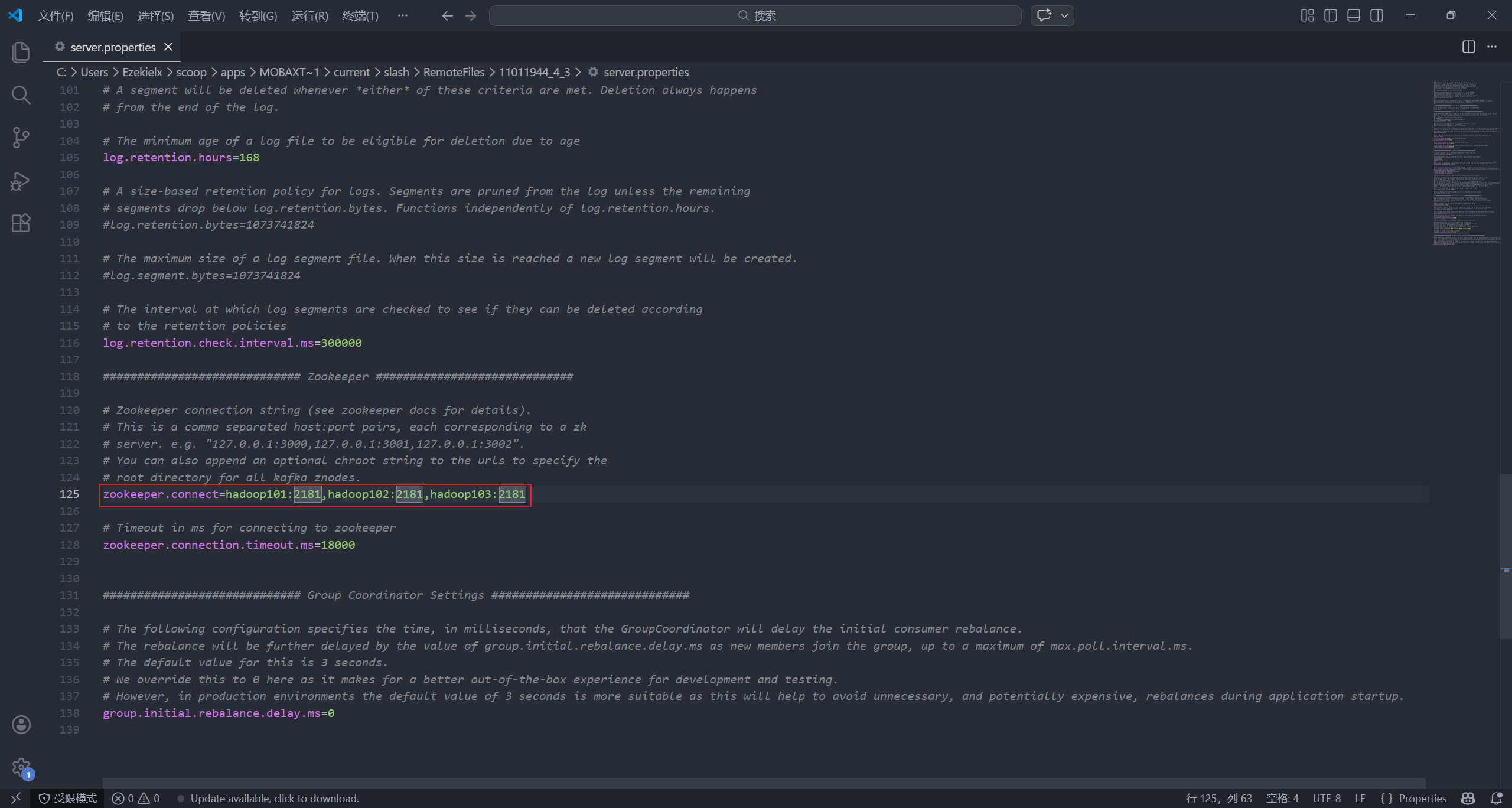
注意每台机器都要改哦🥰(也可以用之前的配置分发脚本,但用了也要改 broker.id 干脆手动改了)。
编写 Kafka 集群管理脚本
创建启动脚本:
vim ~/bin/kafka-start.sh
#!/bin/bash
hosts=(hadoop101 hadoop102 hadoop103)
KAFKA_HOME=/opt/kafka-3.9.2
for host in "${hosts[@]}"
do
echo "========== $host =========="
ssh $host "$KAFKA_HOME/bin/kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties"
done
echo "===== Kafka 集群启动完成 ====="
创建停止脚本:
vim ~/bin/kafka-stop.sh
#!/bin/bash
hosts=(hadoop101 hadoop102 hadoop103)
KAFKA_HOME=/opt/kafka-3.9.2
for host in "${hosts[@]}"
do
echo "========== $host =========="
ssh $host "$KAFKA_HOME/bin/kafka-server-stop.sh"
done
echo "===== Kafka 集群停止完成 ====="
创建状态检查脚本:
vim ~/bin/kafka-status.sh
#!/bin/bash
hosts=(hadoop101 hadoop102 hadoop103)
for host in "${hosts[@]}"
do
echo "========== $host =========="
ssh $host "jps | grep Kafka"
done
给脚本添加执行权限:
chmod +x ~/bin/kafka-*.sh
测试脚本(启动前记得保持 ZooKeeper 运行):
[vaultattic@hadoop101 ~]$ kafka-start.sh
========== hadoop101 ==========
========== hadoop102 ==========
========== hadoop103 ==========
===== Kafka 集群启动完成 =====
[vaultattic@hadoop101 ~]$ kafka-status.sh
========== hadoop101 ==========
133992 Kafka
========== hadoop102 ==========
42779 Kafka
========== hadoop103 ==========
64802 Kafka
[vaultattic@hadoop101 ~]$ kafka-stop.sh
========== hadoop101 ==========
========== hadoop102 ==========
========== hadoop103 ==========
===== Kafka 集群停止完成 =====
[vaultattic@hadoop101 ~]$ kafka-status.sh
========== hadoop101 ==========
========== hadoop102 ==========
========== hadoop103 ==========
[vaultattic@hadoop101 ~]$
6、安装 Flume
Flume 是 Apache 提供的一个分布式日志采集工具,主要用于高效地收集、聚合和传输大量日志数据。它本身不负责复杂计算,而是用于数据采集和传输。在大数据系统中,Flume 通常被用来收集服务器上的日志文件,再把这些日志发送到 Kafka、HDFS、HBase 等系统中。
例如:一台 Web 服务器会持续产生日志,这些日志如果只保存在本地文件中,不方便统一管理和分析。这时候就可以使用 Flume 对日志进行实时监听和采集,一旦有新的日志写入,Flume 就会把它读取出来,并发送到后续的存储或计算系统中。
从整体定位上看,Flume 更像是大数据平台中的“日志搬运工”。它位于数据链路的前端,负责把分散在各台机器上的原始日志稳定地采集起来,再传输给后面的系统继续处理。简单来说,Flume 的作用就是:把日志从产生的地方搬运到需要的地方。
Flume 中常见名词可以简单理解为:
- Source:数据来源,也就是负责接收外部数据的组件。Flume 可以通过 Source 监听日志文件、网络端口,或者接收其他系统发送过来的数据。
- Channel:数据通道,也就是负责临时存储数据的组件。Source 接收到的数据不会直接发送出去,而是先写入 Channel,再由 Sink 从 Channel 中取出数据继续处理。
- Sink:数据出口,也就是负责把数据发送到目标系统的组件。目标系统可以是 HDFS、Kafka、HBase,或者其他存储和处理平台。
- Agent:一个完整的 Flume 运行实例。一个 Agent 通常由 Source、Channel 和 Sink 三部分组成,用来完成一次完整的数据采集和传输流程。
- Event:Flume 中传输的基本数据单元。每条被采集和传输的数据,在 Flume 中都会被封装成一个 Event。
- Interceptor:拦截器,用来在数据进入 Flume 后、写入 Channel 前对数据进行简单处理。例如给日志加时间戳、过滤部分数据、修改字段等。
Flume 的工作流程可以简单概括为:
Source -> Channel -> Sink
也就是:先接收数据,再临时缓存,最后发送到目标系统。
软件包下载
Flume 官网下下载地址:https://flume.apache.org/download.html
直接下最新版就好了,大多数教程用的是 1.9.0 想用旧版的翻一下这个页面下面的历史存档就行了。
这项目怎么还停止维护了,那我学集贸🐔。
百度网盘链接:https://pan.baidu.com/s/1MTilcu-Xx7_LP2GOf37cOA?pwd=8pz1
下载好后将软件压缩包使用 MobeXterm 上传到 hadoop101 的 ~/ansible/files 目录下。
和前面安装软件的过程一样,复制文件名,将之前写好的 deploy_package.yml 中的变量进行替换。
替换后的 deploy_package.yml:
- name: Deploy package
hosts: hadoop
vars:
pkg_name: kafka_2.13-3.9.2.gz
dest_dir: kafka-3.9.2
tasks:
- name: Copy archive
copy:
src: "./files/{{ pkg_name }}"
dest: "/opt/{{ pkg_name }}"
- name: Get top directory name from archive
shell: tar -tf /opt/{{ pkg_name }} | head -1 | cut -d/ -f1
register: archive_dir
- name: Extract archive
command: tar -xzf /opt/{{ pkg_name }} -C /opt
- name: Rename directory
command: mv /opt/{{ archive_dir.stdout | trim }} /opt/{{ dest_dir }}
args:
creates: /opt/{{ dest_dir }}
- name: Change ownership
file:
path: "/opt/{{ dest_dir }}"
owner: vaultattic
group: vaultattic
recurse: yes
- name: Remove archive
file:
path: "/opt/{{ pkg_name }}"
state: absent
运行 deploy_package.yml:
ansible-playbook deploy_package.yml
执行完后可以在各节点的 /opt 目录下查看 Kafka 目录是否存在。
cluster-run.sh ls /opt
[vaultattic@hadoop101 ansible]$ cluster-run.sh ls /opt
--------- hadoop101 ----------
amazon-corretto-8
data_mocker
hadoop-3.3.6
kafka-3.9.2
zookeeper-3.8.6
--------- hadoop102 ----------
amazon-corretto-8
hadoop-3.3.6
kafka-3.9.2
zookeeper-3.8.6
--------- hadoop103 ----------
amazon-corretto-8
hadoop-3.3.6
kafka-3.9.2
zookeeper-3.8.6
[vaultattic@hadoop101 ansible]$
使用 set_env.yml 配置 KAFKA_HOME 环境变量。
复制要配置环境变量的目录路径,将 set_env.yml 中的变量进行替换:
---
- name: Configure environment variables
hosts: hadoop
vars:
env_name: FLUME_HOME
env_path: /opt/flume-1.11.0
tasks:
- name: Add environment variables to /home/vaultattic/.bashrc
lineinfile:
path: "/home/vaultattic/.bashrc"
line: "export {{ env_name }}={{ env_path }}"
create: yes
- name: Add PATH for {{ env_name }}
lineinfile:
path: "/home/vaultattic/.bashrc"
line: "export PATH=${{ env_name }}/bin:$PATH"
运行 set_env.yml:
ansible-playbook set_env.yml
执行 playbook 后使用:
source ~/.bashrc
flume-ng version
[vaultattic@hadoop101 ansible]$ source ~/.bashrc
[vaultattic@hadoop101 ansible]$ flume-ng version
Flume 1.11.0
Source code repository: https://git.apache.org/repos/asf/flume.git
Revision: 1a15927e594fd0d05a59d804b90a9c31ec93f5e1
Compiled by rgoers on Sun Oct 16 14:44:15 MST 2022
From source with checksum bbbca682177262aac3a89defde369a37
[vaultattic@hadoop101 ansible]$
配置 flume-env.sh
先复制配置文件模板:
cd $FLUME_HOME/conf
cp flume-env.sh.template flume-env.sh
编辑配置文件,添加 Java 路径和 Flume 运行内存:
vim flume-env.sh
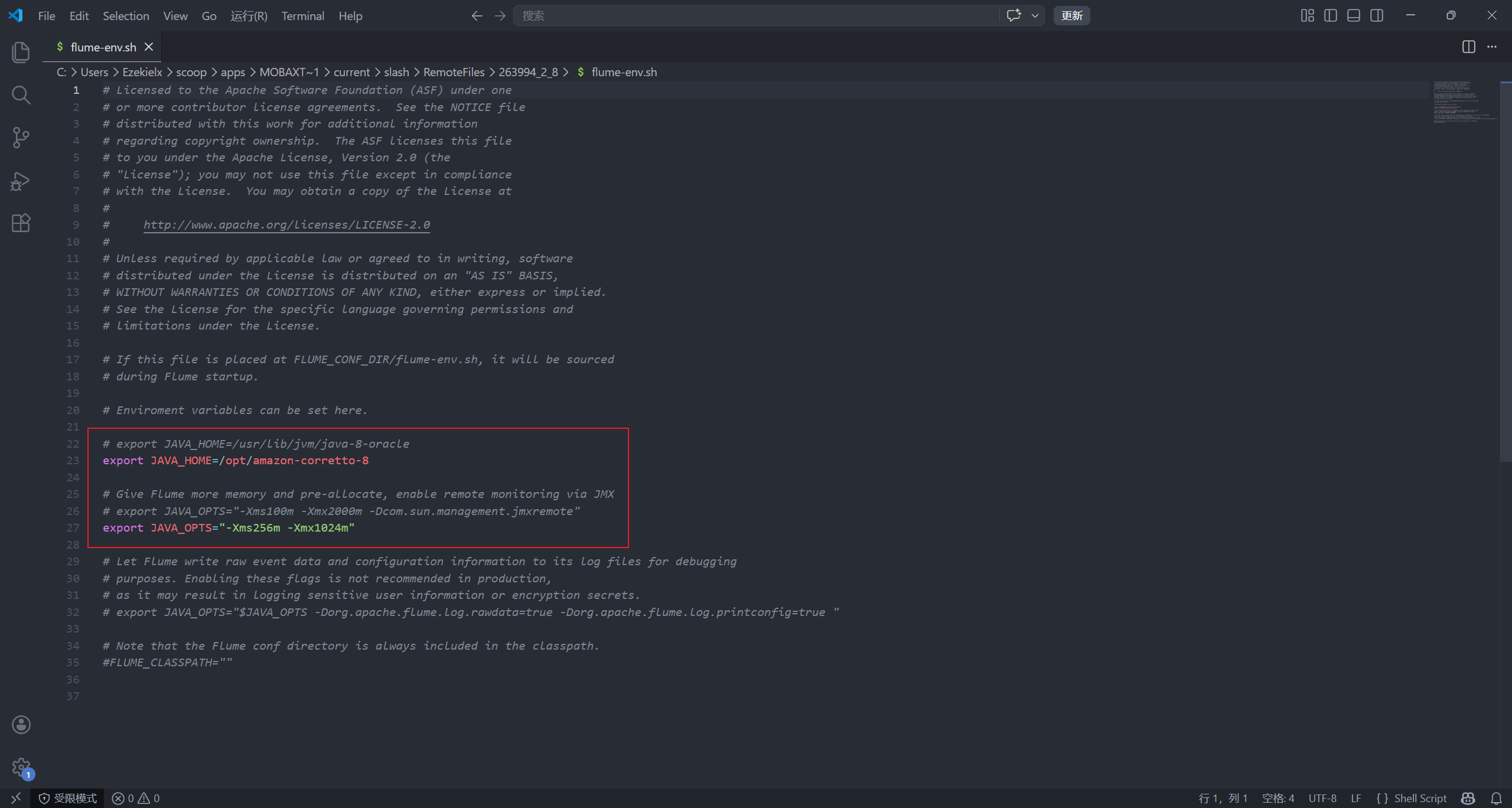
使用 distribute_config.yml,替换变量,将配置文件分发下去。
替换后的 distribute_config.yml:
---
- name: Distribute Hadoop config files
hosts: hadoop
vars:
files:
- flume-env.sh
tasks:
- name: Copy Hadoop config files
copy:
src: "/opt/flume-1.11.0/conf/{{ item }}"
dest: "/opt/flume-1.11.0/conf/{{ item }}"
owner: vaultattic
group: vaultattic
mode: '0644'
loop: "{{ files }}"
运行 distribute_config.yml:
ansible-playbook distribute_config.yml
执行完后在各节点配置文件中搜索 JAVA_HOME 查看是否配置成功。
cluster-run.sh grep JAVA_HOME /opt/flume-1.11.0/conf/flume-env.sh
[vaultattic@hadoop101 ansible]$ cluster-run.sh grep JAVA_HOME /opt/flume-1.11.0/conf/flume-env.sh
--------- hadoop101 ----------
# export JAVA_HOME=/usr/lib/jvm/java-8-oracle
export JAVA_HOME=/opt/amazon-corretto-8
--------- hadoop102 ----------
# export JAVA_HOME=/usr/lib/jvm/java-8-oracle
export JAVA_HOME=/opt/amazon-corretto-8
--------- hadoop103 ----------
# export JAVA_HOME=/usr/lib/jvm/java-8-oracle
export JAVA_HOME=/opt/amazon-corretto-8
[vaultattic@hadoop101 ansible]$
四、Flume 日志采集通道搭建
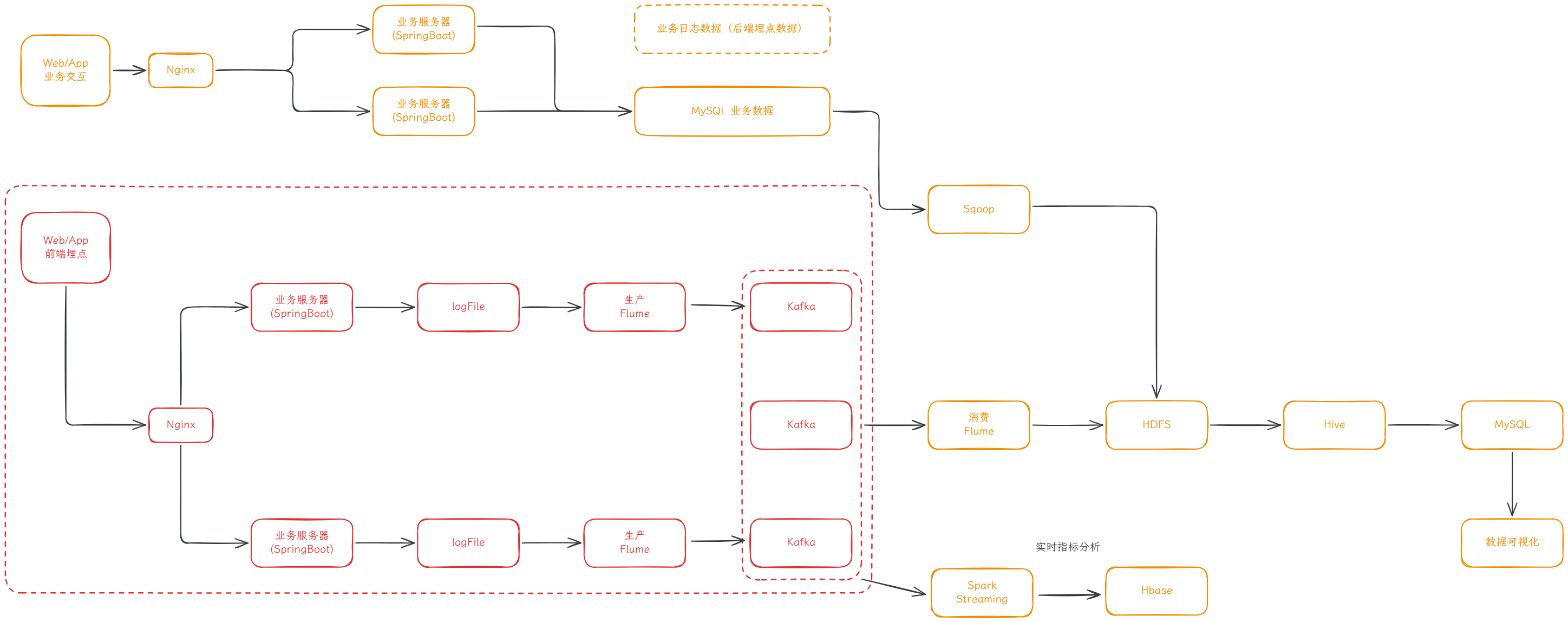
在这个项目中,业务系统产生的日志通常需要先采集到 Kafka,再由下游程序消费并写入 HDFS,最终进入数仓 ODS(Operational Data Store 原始数据)层。
三台节点作用如下:
| 主机 | 作用 |
|---|---|
| hadoop101 | 日志采集端 Flume |
| hadoop102 | 日志采集端 Flume |
| hadoop103 | Kafka 消费端 Flume,写入 HDFS |
1、采集架构设计
本次日志采集链路分为两段。
第一段是从业务日志文件采集数据到 Kafka:
日志文件 -> Taildir Source -> ETL 拦截器 -> Kafka Channel -> Kafka
第二段是从 Kafka 消费数据并写入 HDFS:
Kafka -> Kafka Source -> Timestamp 拦截器 -> File Channel -> HDFS Sink -> HDFS
整体架构如下:
hadoop101 / hadoop102
业务日志文件
↓
Taildir Source
↓
ETLInterceptor
↓
Kafka Channel
↓
Kafka topic_log
hadoop103
Kafka Source
↓
TimestampInterceptor
↓
File Channel
↓
HDFS Sink
↓
/origin_data/edu/log/edu_log/日期
首先,Kafka 可以作为日志数据的缓冲层。采集端只负责快速把日志写入 Kafka,下游 HDFS 写入速度即使偶尔变慢,也不会直接影响业务日志采集。
其次,Flume 采集端和消费端解耦。后续如果需要把日志写入其他系统,比如 Flink、Doris、ClickHouse 或 Spark Streaming,也可以直接从 Kafka 订阅数据。
最后,HDFS 写入端使用 File Channel,可以提高可靠性。即使 Flume 进程异常退出,File Channel 中未处理的数据也可以保存在磁盘中。
2、Flume 组件选型
Source 选型:
采集日志文件时,Flume 常见的 Source 有 Exec Source、Spooling Directory Source 和 Taildir Source。
Exec Source 通常配合 tail -F 使用,配置简单,但可靠性较差。如果 Flume 挂掉,日志消费位置不容易准确恢复。
Spooling Directory Source 适合采集已经写完的文件,比如某个目录下不断生成完整日志文件的场景。但它不适合采集正在持续追加的日志文件。
Taildir Source 更适合业务日志采集场景。它可以监听文件新增内容,并且通过 position 文件记录读取位置,支持断点续传。
所以采集端选择 Taildir Source。
消费 Kafka 时,Flume 提供了 Kafka Source,因此消费端选择 Kafka Source。
Channel 选型:
Channel 主要用于在 Source 和 Sink 之间缓存数据。
Memory Channel 性能高,但数据在内存中,可靠性较差。进程异常退出时,内存中的数据可能丢失。
File Channel 会将数据写入磁盘,可靠性更高,适合重要数据链路。
Kafka Channel 比较适合将 Flume 采集到的数据直接写入 Kafka。使用 Kafka Channel 后,采集端不需要再单独配置 Kafka Sink,链路更简洁。
所以采集端选择 Kafka Channel,消费端选择 File Channel。
Sink 选型:
采集端使用 Kafka Channel 后,数据已经直接写入 Kafka,因此采集端不需要配置 Kafka Sink。
消费端的目标是将 Kafka 中的日志落到 HDFS,所以消费端使用 HDFS Sink。
最终组件组合如下:
| 阶段 | Source | Channel | Sink |
|---|---|---|---|
| 采集端 | Taildir Source | Kafka Channel | 无 |
| 消费端 | Kafka Source | File Channel | HDFS Sink |
3、搭建准备
创建 Flume 相关目录
先在三台机器上创建 Flume 相关目录:
mkdir -p /opt/flume-1.11.0/job
mkdir -p /opt/flume-1.11.0/logs
mkdir -p /opt/flume-1.11.0/taildir_position
在 hadoop103 上额外创建 File Channel 目录:
mkdir -p /opt/flume-1.11.0/file_channel/checkpoint
mkdir -p /opt/flume-1.11.0/file_channel/data
准备自定义拦截器
本次采集链路中使用了两个自定义拦截器:
| 拦截器 | 作用 | 部署节点 |
|---|---|---|
| ETLInterceptor | 过滤非法 JSON 日志 | hadoop101、hadoop102 |
| TimestampInterceptor | 从日志中提取 ts 字段作为 HDFS 分区时间 |
hadoop103 |
在 IDEA 中创建一个 Maven 项目。
删除项目目录中的 Main 类,在 Java 目录下创建一个名为 cn.vaultattic.flume.interceptor 的软件包(cn.vaultattic 是域名反写,自己想改什么改什么)。
在刚刚创建的软件包下再创建 JSONUtils.java、ETLInterceptor.java 和 TimestampInterceptor.java 三个 Java 类文件。
在 pol.xml 文件中添加依赖。
<project> 标签内添加:
<!-- 项目依赖 -->
<dependencies>
<!-- Flume 核心依赖 -->
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>1.9.0</version>
<scope>provided</scope>
</dependency>
<!-- fastjson 依赖,用来解析 JSON -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.83</version>
</dependency>
</dependencies>
<!-- 构建/打包配置 -->
<build>
<plugins>
<!-- assembly 插件,用于把依赖一起打进 jar 包 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.3.0</version>
<configuration>
<descriptorRefs>
<!-- 生成 jar-with-dependencies 包 -->
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<!-- 插件执行的名称,方便区分不同的执行配置 -->
<id>make-assembly</id>
<!-- 在执行 mvn package 的时候触发这个插件 -->
<phase>package</phase>
<goals>
<!-- 执行 assembly 插件的 single 目标,表示根据上面的配置生成一个完整的组装包 -->
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
完整 pol.xml:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.vaultattic</groupId>
<artifactId>flume-interceptor</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<!-- 项目依赖 -->
<dependencies>
<!-- Flume 核心依赖 -->
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>1.9.0</version>
<scope>provided</scope>
</dependency>
<!-- fastjson 依赖,用来解析 JSON -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.83</version>
</dependency>
</dependencies>
<!-- 构建/打包配置 -->
<build>
<plugins>
<!-- assembly 插件,用于把依赖一起打进 jar 包 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.3.0</version>
<configuration>
<descriptorRefs>
<!-- 生成 jar-with-dependencies 包 -->
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<!-- 插件执行的名称,方便区分不同的执行配置 -->
<id>make-assembly</id>
<!-- 在执行 mvn package 的时候触发这个插件 -->
<phase>package</phase>
<goals>
<!-- 执行 assembly 插件的 single 目标,表示根据上面的配置生成一个完整的组装包 -->
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
刷新配置文件。
修改之前创建的两个 Java 类文件。
JSONUtils.java:
package cn.vaultattic.flume.interceptor;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONException;
// JSON 工具类:只负责判断字符串是否可以被 fastjson 正常解析
public class JSONUtils {
public static boolean isJSONValidate(String log) {
try {
// 使用 fastjson 判断是否为合法 JSON
JSON.parse(log);
return true;
} catch (JSONException e) {
// 解析失败,说明不是合法 JSON
return false;
}
}
}
ETLInterceptor.java:
package cn.vaultattic.flume.interceptor;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.nio.charset.StandardCharsets;
import java.util.Iterator;
import java.util.List;
// ETL 拦截器:对 JSON 做合法性校验
public class ETLInterceptor implements Interceptor {
@Override
public void initialize() {
// 初始化方法,当前没有需要初始化的资源
}
@Override
public Event intercept(Event event) {
// 获取 Event 中的 body 数据
byte[] body = event.getBody();
// 将字节数组转换为字符串
String log = new String(body, StandardCharsets.UTF_8);
// 判断日志是否为合法 JSON
if (JSONUtils.isJSONValidate(log)) {
// 合法 JSON 直接返回原 Event
// 注意:这里不修改 body,也不添加 header
return event;
} else {
// 非法 JSON 返回 null,表示该条数据被过滤掉
return null;
}
}
@Override
public List<Event> intercept(List<Event> list) {
// 使用迭代器遍历,方便在遍历过程中删除非法数据
Iterator<Event> iterator = list.iterator();
while (iterator.hasNext()) {
Event next = iterator.next();
// 如果单条处理结果为 null,说明不是合法 JSON,直接从集合中移除
if (intercept(next) == null) {
iterator.remove();
}
}
// 返回过滤后的 Event 集合
return list;
}
@Override
public void close() {
// 关闭方法,当前没有需要释放的资源
}
// Builder 用于 Flume 创建自定义拦截器对象
public static class Builder implements Interceptor.Builder {
@Override
public Interceptor build() {
// 返回当前拦截器实例
return new ETLInterceptor();
}
@Override
public void configure(Context context) {
// 当前没有额外配置项
}
}
}
TimestampInterceptor.java:
package cn.vaultattic.flume.interceptor;
import com.alibaba.fastjson.JSONObject;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.nio.charset.StandardCharsets;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
// 时间戳拦截器:从日志 JSON 中提取 ts 字段,写入 Event 的 header 中
public class TimestampInterceptor implements Interceptor {
// 用于保存批量处理后的 Event
private ArrayList<Event> events = new ArrayList<>();
@Override
public void initialize() {
// 初始化方法,当前没有需要初始化的资源
}
@Override
public Event intercept(Event event) {
// 获取 Event 的 header
Map<String, String> headers = event.getHeaders();
// 获取日志 body,并按照 UTF-8 转换成字符串
String log = new String(event.getBody(), StandardCharsets.UTF_8);
// 将日志字符串解析成 JSON 对象
JSONObject jsonObject = JSONObject.parseObject(log);
// 从 JSON 中获取 ts 字段
String ts = jsonObject.getString("ts");
// 将 ts 写入 header,key 必须是 timestamp
// Flume 的 HDFS Sink 可以根据该 timestamp 进行时间分区
headers.put("timestamp", ts);
return event;
}
@Override
public List<Event> intercept(List<Event> list) {
// 清空上一次批量处理留下的数据
events.clear();
// 遍历每一个 Event,逐条处理
for (Event event : list) {
events.add(intercept(event));
}
return events;
}
@Override
public void close() {
// 关闭方法,当前没有需要释放的资源
}
// Builder 用于让 Flume 创建自定义拦截器对象
public static class Builder implements Interceptor.Builder {
@Override
public Interceptor build() {
// 返回当前拦截器实例
return new TimestampInterceptor();
}
@Override
public void configure(Context context) {
// 如果后续需要从 Flume 配置中读取参数,可以在这里处理
}
}
}
将上面两个类打包为 .jar 文件。
将带有依赖的 .jar 包上传到 hadoop101 的 ~/ansible/files
创建 distribute_file.yml,将 Jar 包分发到各节点的依赖目录中。
vim distribute_file.yml
---
- name: Distribute file
hosts: hadoop
vars:
src: /home/vaultattic/ansible/files/flume-interceptor-1.0-SNAPSHOT-jar-with-dependencies.jar
dest: /opt/flume-1.11.0/lib/flume-interceptor.jar
tasks:
- name: Copy file
copy:
src: "{{ src }}"
dest: "{{ dest }}"
owner: vaultattic
group: vaultattic
mode: '0644'
运行 deploy_package.yml:
ansible-playbook distribute_file.yml
创建 Kafka Topic
kafka-topics.sh \
--bootstrap-server hadoop101:9092,hadoop102:9092,hadoop103:9092 \
--create \
--topic topic_log \
--partitions 3 \
--replication-factor 3
[vaultattic@hadoop101 ~]$ kafka-topics.sh \
--bootstrap-server hadoop101:9092,hadoop102:9092,hadoop103:9092 \
--create \
--topic topic_log \
--partitions 3 \
--replication-factor 3
WARNING: Due to limitations in metric names, topics with a period ('.') or underscore ('_') could collide. To avoid issues it is best to use either, but not both.
Created topic topic_log.
[vaultattic@hadoop101 ~]$
查看 Topic 信息:
kafka-topics.sh \
--bootstrap-server hadoop101:9092,hadoop102:9092,hadoop103:9092 \
--describe \
--topic topic_log
[vaultattic@hadoop101 ~]$ kafka-topics.sh \
--bootstrap-server hadoop101:9092,hadoop102:9092,hadoop103:9092 \
--describe \
--topic topic_log
Topic: topic_log TopicId: V7D5Gy1kR5mB-LfFSTn_zw PartitionCount: 3 ReplicationFactor: 3 Configs:
Topic: topic_log Partition: 0 Leader: 2 Replicas: 2,1,3 Isr: 2,1,3 Elr: N/A LastKnownElr: N/A
Topic: topic_log Partition: 1 Leader: 3 Replicas: 3,2,1 Isr: 3,2,1 Elr: N/A LastKnownElr: N/A
Topic: topic_log Partition: 2 Leader: 1 Replicas: 1,3,2 Isr: 1,3,2 Elr: N/A LastKnownElr: N/A
[vaultattic@hadoop101 ~]$
4、采集端 Flume 配置:日志文件写入 Kafka
采集端部署在:
hadoop101
hadoop102
采集端主要负责监听业务日志文件,并将日志写入 Kafka。整体链路如下:
日志文件 -> Taildir Source -> ETL 拦截器 -> Kafka Channel -> Kafka
在 hadoop101、hadoop102 创建配置文件:
vim /opt/flume-1.11.0/job/file-to-kafka.conf
# agent 名称
a1.sources = r1
a1.channels = c1
# Taildir Source:监听日志文件
a1.sources.r1.type = TAILDIR
# 文件组名称
a1.sources.r1.filegroups = f1
# 监听的日志文件路径
a1.sources.r1.filegroups.f1 = /opt/data_mocker/log/app.*
# 记录读取位置的文件
a1.sources.r1.positionFile = /opt/flume-1.11.0/taildir_position/log_position.json
# 每批读取的最大事件数
a1.sources.r1.batchSize = 1000
# ETL 拦截器:过滤非法日志
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = cn.vaultattic.flume.interceptor.ETLInterceptor$Builder
# Kafka Channel:把数据直接写入 Kafka
a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
# Kafka broker 地址
a1.channels.c1.kafka.bootstrap.servers = hadoop101:9092,hadoop102:9092,hadoop103:9092
# 写入的 topic
a1.channels.c1.kafka.topic = topic_log
# 只写入 Event body,不写入 Flume Event 结构
a1.channels.c1.parseAsFlumeEvent = false
# Kafka Producer 参数
a1.channels.c1.kafka.producer.acks = all
a1.channels.c1.kafka.producer.retries = 3
a1.channels.c1.kafka.producer.batch.size = 32768
a1.channels.c1.kafka.producer.linger.ms = 10
a1.channels.c1.kafka.producer.buffer.memory = 67108864
# 绑定 source 和 channel
a1.sources.r1.channels = c1
注意 hadoop101、hadoop102 都要创建🥰。
5、消费端 Flume 配置:Kafka 写入 HDFS
消费端部署在:
hadoop103
作用是从 Kafka 中读取日志,并写入 HDFS。
在 hadoop103 创建配置文件:
vim /opt/flume-1.11.0/job/kafka-to-hdfs.conf
# agent 名称
a1.sources = r1
a1.channels = c1
a1.sinks = k1
# Kafka Source:从 topic_log 消费数据
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
# Kafka broker 地址
a1.sources.r1.kafka.bootstrap.servers = hadoop101:9092,hadoop102:9092,hadoop103:9092
# 订阅的 topic
a1.sources.r1.kafka.topics = topic_log
# 消费组 ID
a1.sources.r1.kafka.consumer.group.id = flume_hdfs_group
# 每批拉取的最大事件数
a1.sources.r1.batchSize = 5000
# 每批等待时间
a1.sources.r1.batchDurationMillis = 2000
# 没有 offset 时从最新位置开始消费
a1.sources.r1.kafka.consumer.auto.offset.reset = latest
# Timestamp 拦截器:提取日志中的时间戳
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = cn.vaultattic.flume.interceptor.TimestampInterceptor$Builder
# File Channel:本地磁盘缓存
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /opt/flume-1.11.0/file_channel/checkpoint
a1.channels.c1.dataDirs = /opt/flume-1.11.0/file_channel/data
# Channel 容量
a1.channels.c1.capacity = 1000000
# 单次事务处理数量
a1.channels.c1.transactionCapacity = 10000
# HDFS Sink:写入 HDFS
a1.sinks.k1.type = hdfs
# HDFS 输出目录,按日期分区
a1.sinks.k1.hdfs.path = /origin_data/edu/log/edu_log/%Y-%m-%d
# 文件名前缀和后缀
a1.sinks.k1.hdfs.filePrefix = log
a1.sinks.k1.hdfs.fileSuffix = .gz
# 使用事件中的时间戳作为分区时间
a1.sinks.k1.hdfs.useLocalTimeStamp = false
# 文件滚动策略
a1.sinks.k1.hdfs.rollInterval = 3600
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
# 写入参数
a1.sinks.k1.hdfs.batchSize = 5000
a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.codeC = gzip
a1.sinks.k1.hdfs.writeFormat = Text
# 临时文件和空闲文件处理
a1.sinks.k1.hdfs.idleTimeout = 120
a1.sinks.k1.hdfs.inUsePrefix = .
a1.sinks.k1.hdfs.inUseSuffix = .tmp
# 绑定 source、channel、sink
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
6、启动脚本
在 hadoop101 创建采集 Flume 脚本:
vim ~/bin/flume-collect.sh
#!/usr/bin/env bash
set -euo pipefail
FLUME_HOME="/opt/flume-1.11.0"
FLUME_CONF="${FLUME_HOME}/job/file-to-kafka.conf"
AGENT_NAME="a1"
LOG_FILE="${FLUME_HOME}/logs/flume-collect.out"
PID_FILE="${FLUME_HOME}/logs/flume-collect.pid"
HOSTS=(
"hadoop101"
"hadoop102"
)
start() {
for host in "${HOSTS[@]}"; do
echo "========== 启动 ${host} 采集端 Flume =========="
ssh "$host" "
if [ -f '${PID_FILE}' ]; then
pid=\$(cat '${PID_FILE}' 2>/dev/null || true)
if [ -n \"\$pid\" ] && kill -0 \"\$pid\" 2>/dev/null; then
echo '${host} 采集端 Flume 已在运行'
exit 0
fi
fi
mkdir -p '${FLUME_HOME}/logs'
nohup '${FLUME_HOME}/bin/flume-ng' agent \
--conf '${FLUME_HOME}/conf' \
--conf-file '${FLUME_CONF}' \
--name '${AGENT_NAME}' \
-Dflume.root.logger=INFO,console \
> '${LOG_FILE}' 2>&1 < /dev/null &
echo \$! > '${PID_FILE}'
"
sleep 3
if ssh "$host" "
pid=\$(cat '${PID_FILE}' 2>/dev/null || true)
[ -n \"\$pid\" ] && kill -0 \"\$pid\" 2>/dev/null
"; then
echo "${host} 采集端 Flume 启动成功"
else
echo "${host} 采集端 Flume 启动失败,请查看日志:${LOG_FILE}"
fi
done
}
stop() {
for host in "${HOSTS[@]}"; do
echo "========== 停止 ${host} 采集端 Flume =========="
ssh "$host" "
if [ -f '${PID_FILE}' ]; then
pid=\$(cat '${PID_FILE}' 2>/dev/null || true)
if [ -n \"\$pid\" ] && kill -0 \"\$pid\" 2>/dev/null; then
kill \"\$pid\"
sleep 2
fi
if [ -n \"\$pid\" ] && kill -0 \"\$pid\" 2>/dev/null; then
kill -9 \"\$pid\" 2>/dev/null || true
fi
rm -f '${PID_FILE}'
echo '${host} 采集端 Flume 停止完成'
else
echo '${host} 采集端 Flume 未运行'
fi
"
done
}
status() {
for host in "${HOSTS[@]}"; do
echo "========== 查看 ${host} 采集端 Flume =========="
ssh "$host" "
if [ -f '${PID_FILE}' ]; then
pid=\$(cat '${PID_FILE}' 2>/dev/null || true)
if [ -n \"\$pid\" ] && kill -0 \"\$pid\" 2>/dev/null; then
echo '${host} 采集端 Flume 运行中'
else
echo '${host} 采集端 Flume 未运行'
fi
else
echo '${host} 采集端 Flume 未运行'
fi
"
done
}
case "${1:-}" in
start)
start
;;
stop)
stop
;;
restart)
stop
sleep 3
start
;;
status)
status
;;
*)
echo "用法: $0 {start|stop|restart|status}"
exit 1
;;
esac
创建消费 Flume 脚本:
vim ~/bin/flume-consume.sh
#!/usr/bin/env bash
set -euo pipefail
FLUME_HOME="/opt/flume-1.11.0"
FLUME_CONF="${FLUME_HOME}/job/kafka-to-hdfs.conf"
AGENT_NAME="a1"
LOG_FILE="${FLUME_HOME}/logs/flume-consume.out"
PID_FILE="${FLUME_HOME}/logs/flume-consume.pid"
HOSTS=(
"hadoop103"
)
start() {
for host in "${HOSTS[@]}"; do
echo "========== 启动 ${host} 消费端 Flume =========="
ssh "$host" "
if [ -f '${PID_FILE}' ]; then
pid=\$(cat '${PID_FILE}' 2>/dev/null || true)
if [ -n \"\$pid\" ] && kill -0 \"\$pid\" 2>/dev/null; then
echo '${host} 消费端 Flume 已在运行'
exit 0
fi
fi
mkdir -p '${FLUME_HOME}/logs'
nohup '${FLUME_HOME}/bin/flume-ng' agent \
--conf '${FLUME_HOME}/conf' \
--conf-file '${FLUME_CONF}' \
--name '${AGENT_NAME}' \
-Dflume.root.logger=INFO,console \
> '${LOG_FILE}' 2>&1 < /dev/null &
echo \$! > '${PID_FILE}'
"
sleep 3
if ssh "$host" "
pid=\$(cat '${PID_FILE}' 2>/dev/null || true)
[ -n \"\$pid\" ] && kill -0 \"\$pid\" 2>/dev/null
"; then
echo "${host} 消费端 Flume 启动成功"
else
echo "${host} 消费端 Flume 启动失败,请查看日志:${LOG_FILE}"
fi
done
}
stop() {
for host in "${HOSTS[@]}"; do
echo "========== 停止 ${host} 消费端 Flume =========="
ssh "$host" "
if [ -f '${PID_FILE}' ]; then
pid=\$(cat '${PID_FILE}' 2>/dev/null || true)
if [ -n \"\$pid\" ] && kill -0 \"\$pid\" 2>/dev/null; then
kill \"\$pid\"
sleep 2
fi
if [ -n \"\$pid\" ] && kill -0 \"\$pid\" 2>/dev/null; then
kill -9 \"\$pid\" 2>/dev/null || true
fi
rm -f '${PID_FILE}'
echo '${host} 消费端 Flume 停止完成'
else
echo '${host} 消费端 Flume 未运行'
fi
"
done
}
status() {
for host in "${HOSTS[@]}"; do
echo "========== 查看 ${host} 消费端 Flume =========="
ssh "$host" "
if [ -f '${PID_FILE}' ]; then
pid=\$(cat '${PID_FILE}' 2>/dev/null || true)
if [ -n \"\$pid\" ] && kill -0 \"\$pid\" 2>/dev/null; then
echo '${host} 消费端 Flume 运行中'
else
echo '${host} 消费端 Flume 未运行'
fi
else
echo '${host} 消费端 Flume 未运行'
fi
"
done
}
case "${1:-}" in
start)
start
;;
stop)
stop
;;
restart)
stop
sleep 3
start
;;
status)
status
;;
*)
echo "用法: $0 {start|stop|restart|status}"
exit 1
;;
esac
添加执行权限:
chmod +x ~/bin/flume*
先启动消费端,再启动采集端:
flume-consume.sh start
flume-collect.sh start
[vaultattic@hadoop101 ~]$ flume-consume.sh start
========== 启动 hadoop103 消费端 Flume ==========
hadoop103 消费端 Flume 启动成功
[vaultattic@hadoop101 ~]$ flume-collect.sh start
========== 启动 hadoop101 采集端 Flume ==========
hadoop101 采集端 Flume 启动成功
========== 启动 hadoop102 采集端 Flume ==========
hadoop102 采集端 Flume 启动成功
[vaultattic@hadoop101 ~]$
查看状态:
flume-collect.sh status
flume-consume.sh status
重启:
flume-consume.sh restart
flume-collect.sh restart
停止:
flume-consume.sh stop
flume-collect.sh stop
7、测试验证
启动 Flume
启动消费端:
flume-consume.sh start
启动采集端:
flume-collect.sh start
查看 Kafka 数据
新建终端,监听 消费 Kafka 中的数据:
kafka-console-consumer.sh \
--bootstrap-server hadoop101:9092,hadoop102:9092,hadoop103:9092 \
--topic topic_log
生成模拟日志
mock.sh 2022-02-21
如果 Kafka 中能看到刚才写入的 JSON 日志,说明采集端正常。
查看 HDFS 数据
查看 HDFS 目录:
hdfs dfs -ls /origin_data/edu/log/edu_log/
[vaultattic@hadoop101 ~]$ hdfs dfs -ls /origin_data/edu/log/edu_log/
Found 2 items
drwxr-xr-x - vaultattic supergroup 0 2026-05-21 18:10 /origin_data/edu/log/edu_log/2022-02-21
drwxr-xr-x - vaultattic supergroup 0 2026-05-21 18:10 /origin_data/edu/log/edu_log/2022-02-22
[vaultattic@hadoop101 ~]$
有两个是正常的,之前拦截器中说过 2022-02-21 23:59:59 的数据会修改为 2022-02-22 00:00:xx。
查看具体日期目录:
hdfs dfs -ls /origin_data/edu/log/edu_log/2022-02-21
[vaultattic@hadoop101 ~]$ hdfs dfs -ls /origin_data/edu/log/edu_log/2022-02-21
Found 1 items
-rw-r--r-- 3 vaultattic supergroup 402839 2026-05-21 18:12 /origin_data/edu/log/edu_log/2022-02-21/log.1779358214002.gz
[vaultattic@hadoop101 ~]$
查看落盘数据:
hdfs dfs -text /origin_data/edu/log/edu_log/2022-02-21/log*.gz | head
如果能够看到刚才写入的 JSON 日志,说明 Kafka 到 HDFS 的消费链路也已经打通🥰。