
一、虚拟机下载
虚拟机选择 VMware Workstation Pro,这是官网下载地址:Fusion and Workstation | VMware 。
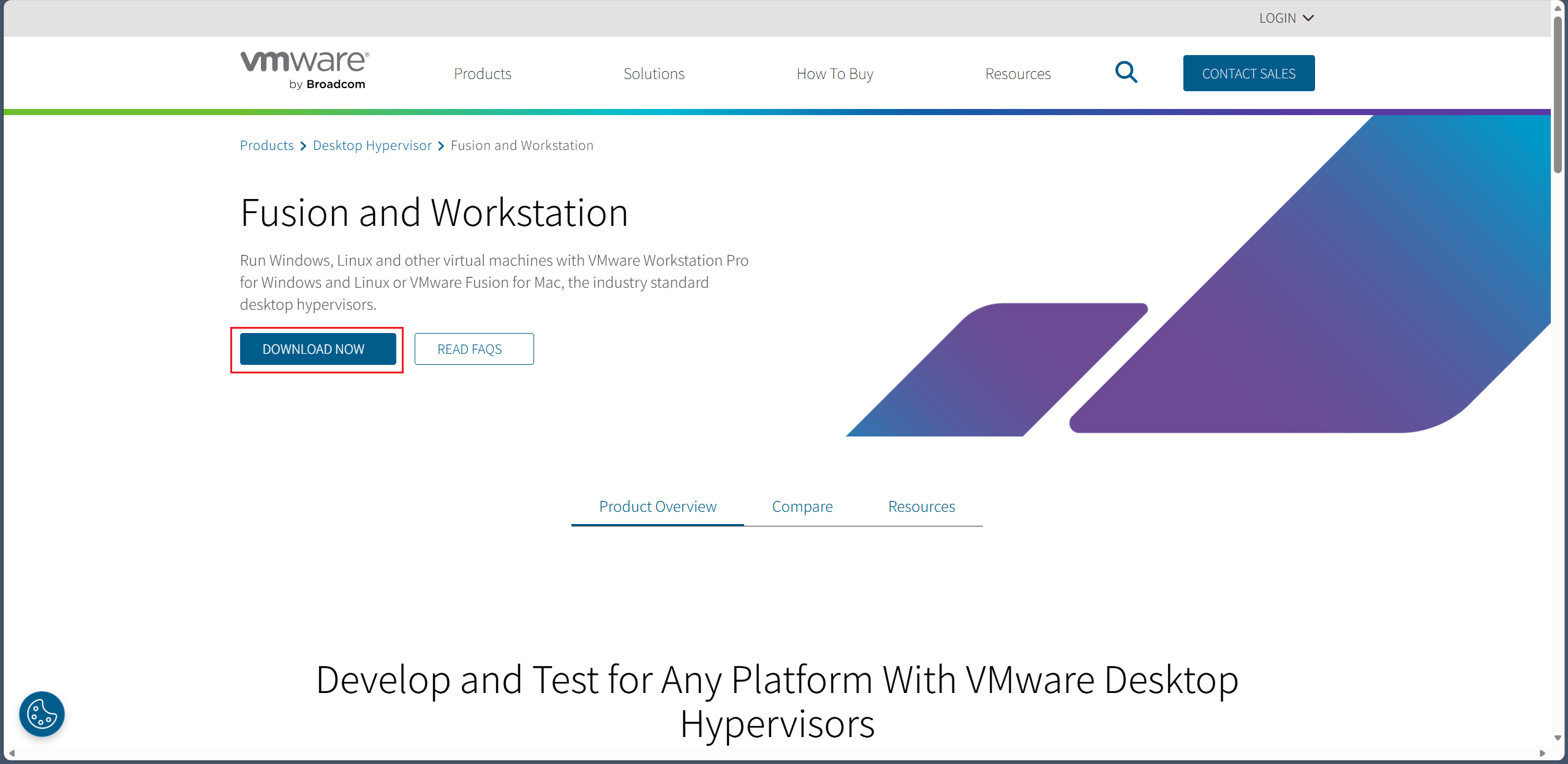
随便吐槽一下,我不知道把下载链接藏这么深是何意味😕?而且你不登录还下载(下载链接会验证你是否登录)不了,本来网站就在国外,没有梯子网站都打不开,更别说注册账号了😥。
这里是放百度网盘上的官网下载的安装包,如果实在登录不上去就用百度网盘慢慢下吧。
VMware Workstation Pro 17 百度网盘下载链接:https://pan.baidu.com/s/1-e6lWJHMtQ_6ha_0Lnin5w?pwd=tcdb
VMware Workstation Pro 25H2 百度网盘下载链接:https://pan.baidu.com/s/1gtJnZkblIJoSvceF7-wjjg?pwd=cw54
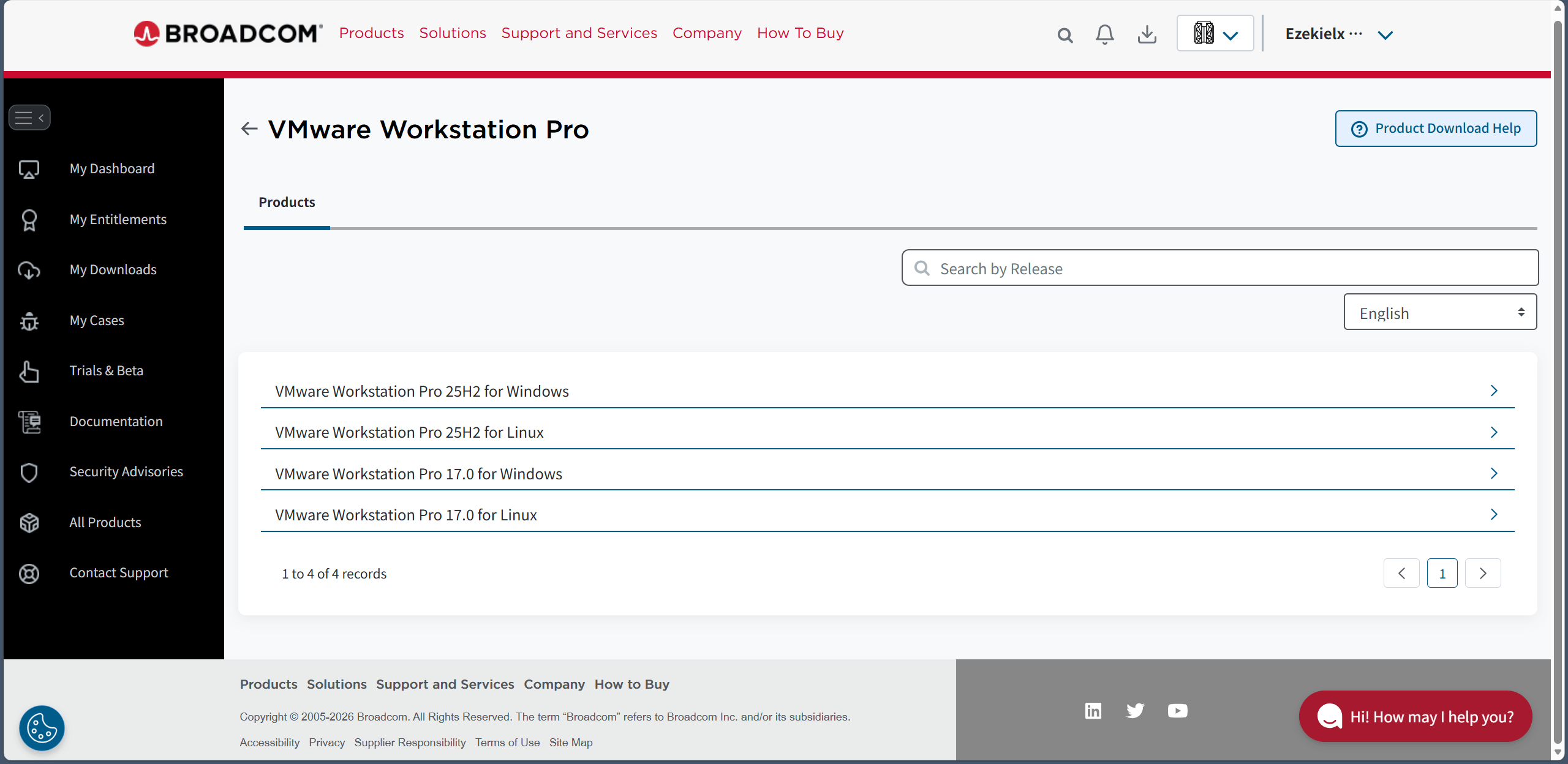
这里有两个版本,一个 VMware Workstation Pro 17 和 VMware Workstation Pro 25H2。这个 25H2 版本是 VMware 被 Broadcom 收购后出的新版本,版本号命名改成和微软一样的命名法。
按道理来说 25H2 多了很多新功能,但作为一款支持多语言的软件偏偏把简体中文砍了🤗。
所以选什么版本看自己选择,想要体验新功能就 25H2(但其实一般用户也不会在意),想要中文就 17。
二、系统镜像下载
大部分教程都是选的 CentOS 7,这是一个很老的 Linux 发行版了,学习当然没问题,但已经停止支持了。
我这里就选 Rocky 10 作为系统镜像,Rocky 也相当于 CentOS 的后继吧(可以看我之前写的:CentOS 停更之后:Rocky Linux 如何接棒 Red Hat 生态 - 滕王阁)。
官网下载地址:Download - Rocky Linux
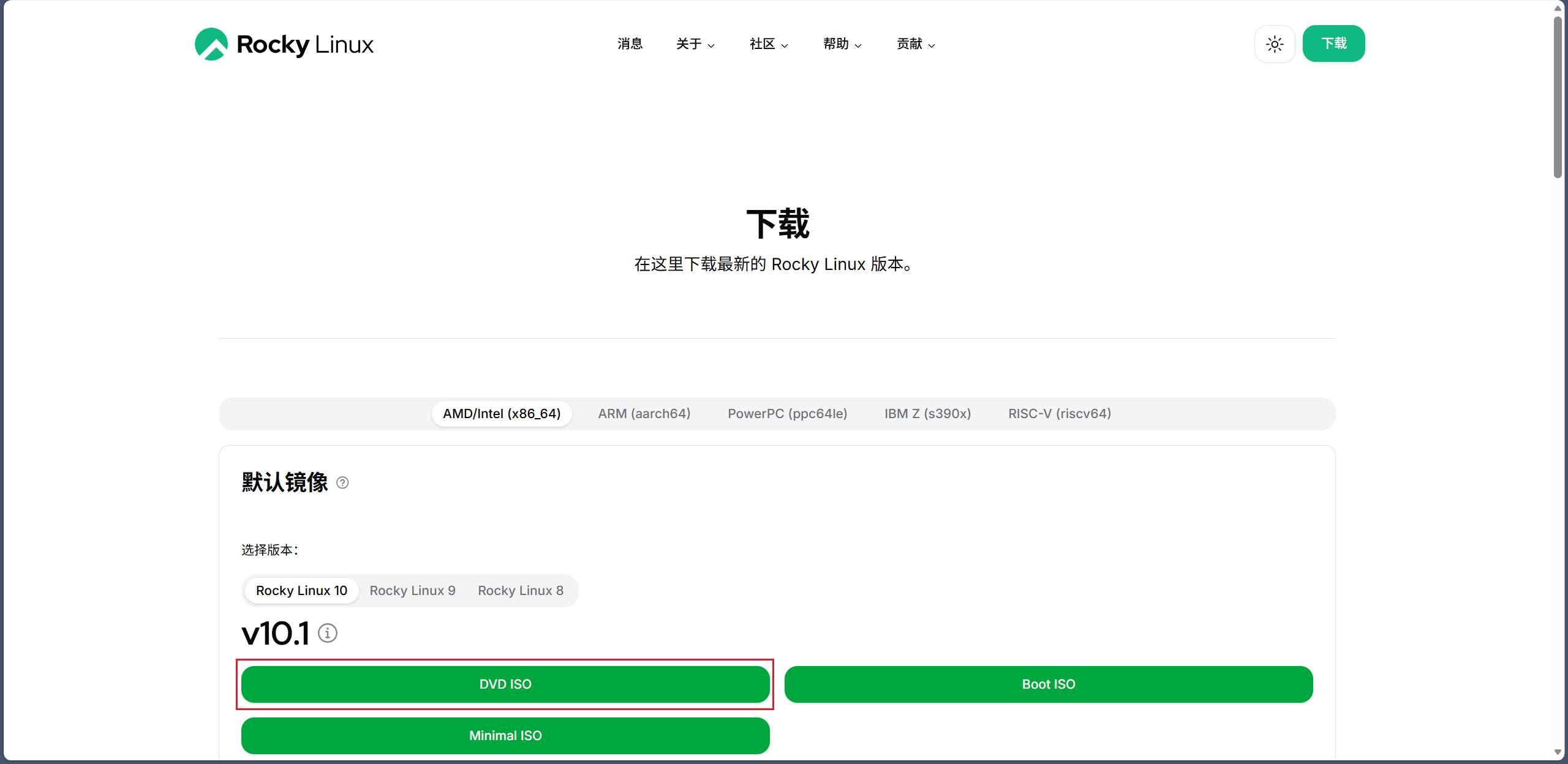
下载 DVD 镜像(完整版),Boot 镜像只包含启动程序,安装时需要联网下载软件,Minimal 最小系统镜像只安装最基础的系统,没有图形和额外软件。
三、安装 Linux 虚拟机
左上角选择安装虚拟机,选择下载的系统镜像和虚拟机安装位置。
选择磁盘空间大小,默认 20G 一般是够的,下面那个选项是是否分割虚拟磁盘为多个文件,上面都有介绍,改不改没关系。
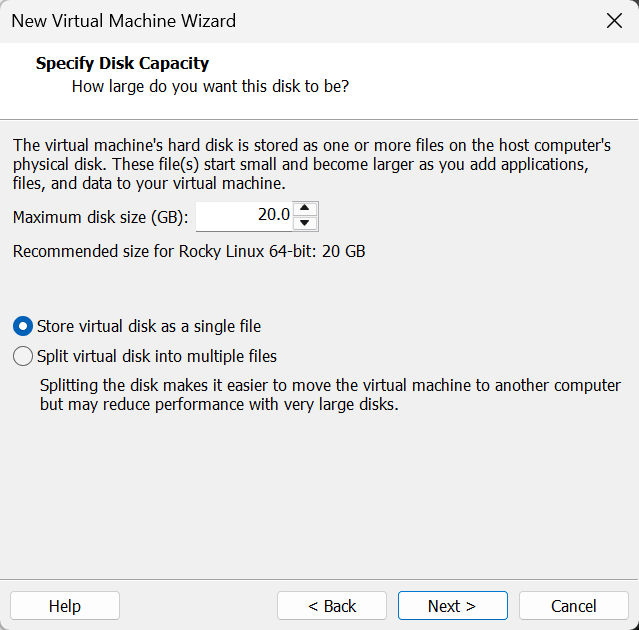
后面的是虚拟硬件的详细设置,也没什么可改的,根据你自己的内存大小把虚拟内存调一调,最小一般 4G 就可以了😀。
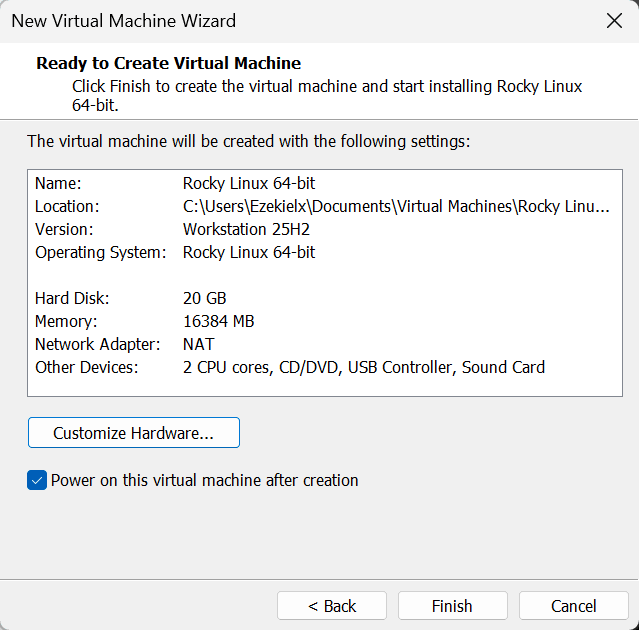
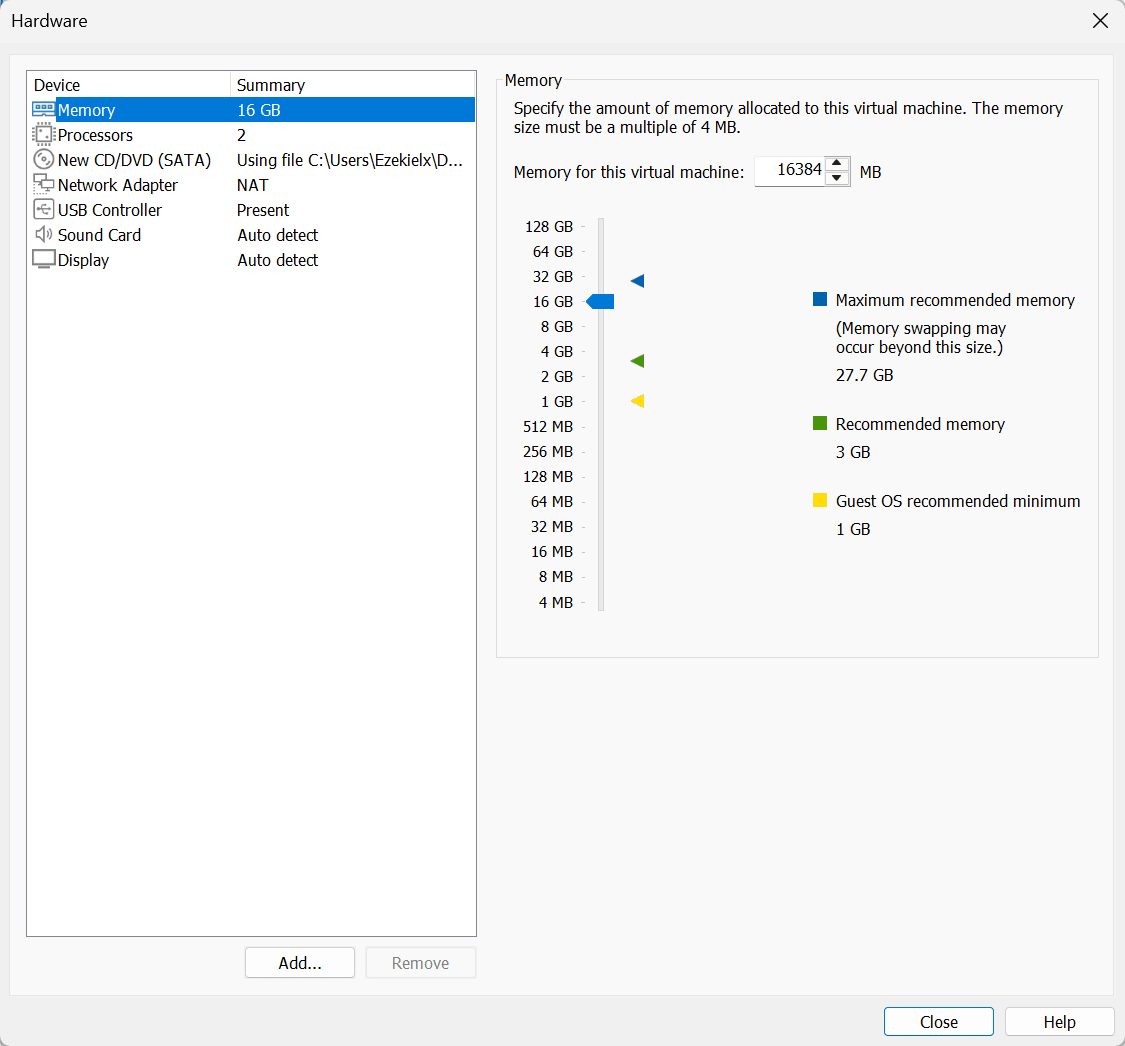
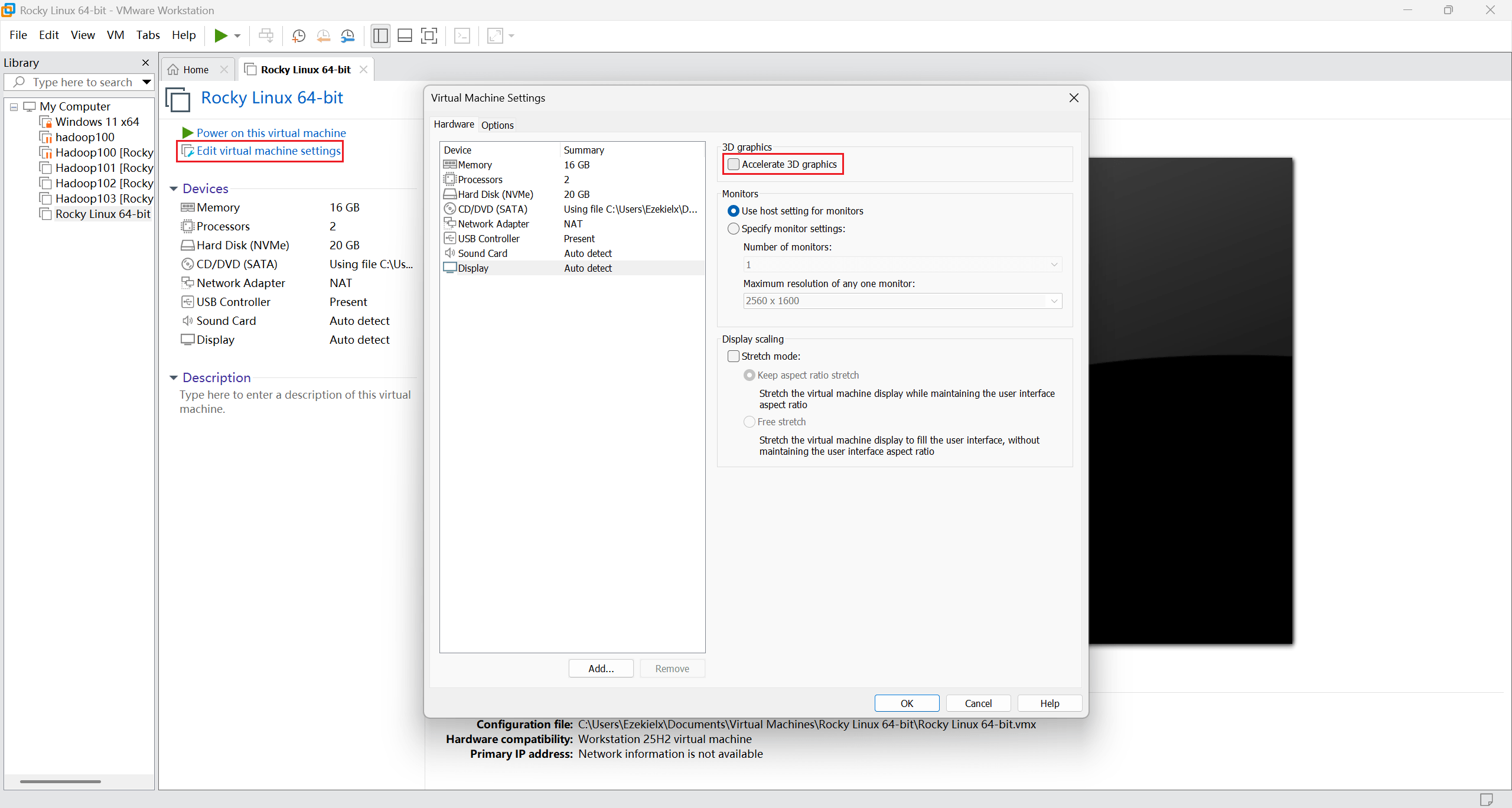
如果启动后出现如下报错,可以尝试把 3D graphics 关了。
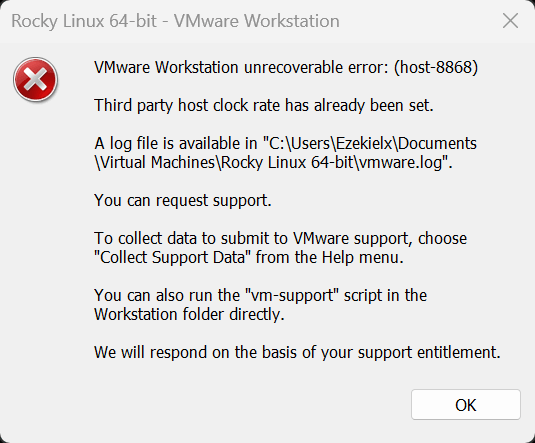
VMware Workstation unrecoverable error: (host-8868)
Third party host clock rate has already been set.
A log file is available in "C:\Users\Ezekielx\Documents\Virtual Machines\Rocky Linux 64-bit\vmware.log".
You can request support.
To collect data to submit to VMware support, choose "Collect Support Data" from the Help menu.
You can also run the "vm-support" script in the Workstation folder directly.
We will respond on the basis of your support entitlement.
进入系统后选择第一项安装系统。

系统语言选英文选中文都可以,都不影响。
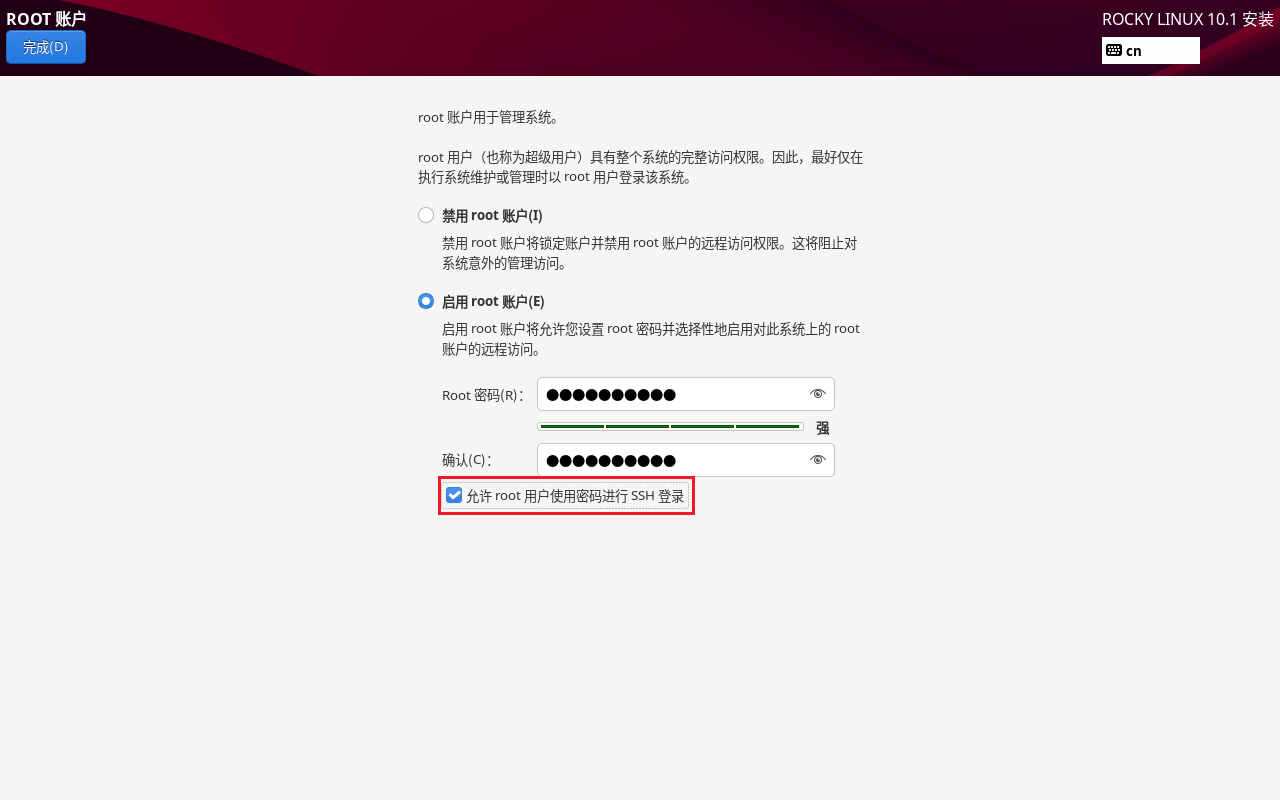
来的引导界面后选择磁盘(就一个可选),创建 root 账户(允许 SSH 密码登录选上,这样一开始配环境方便一点),下面那个普通用户可以不用创建。

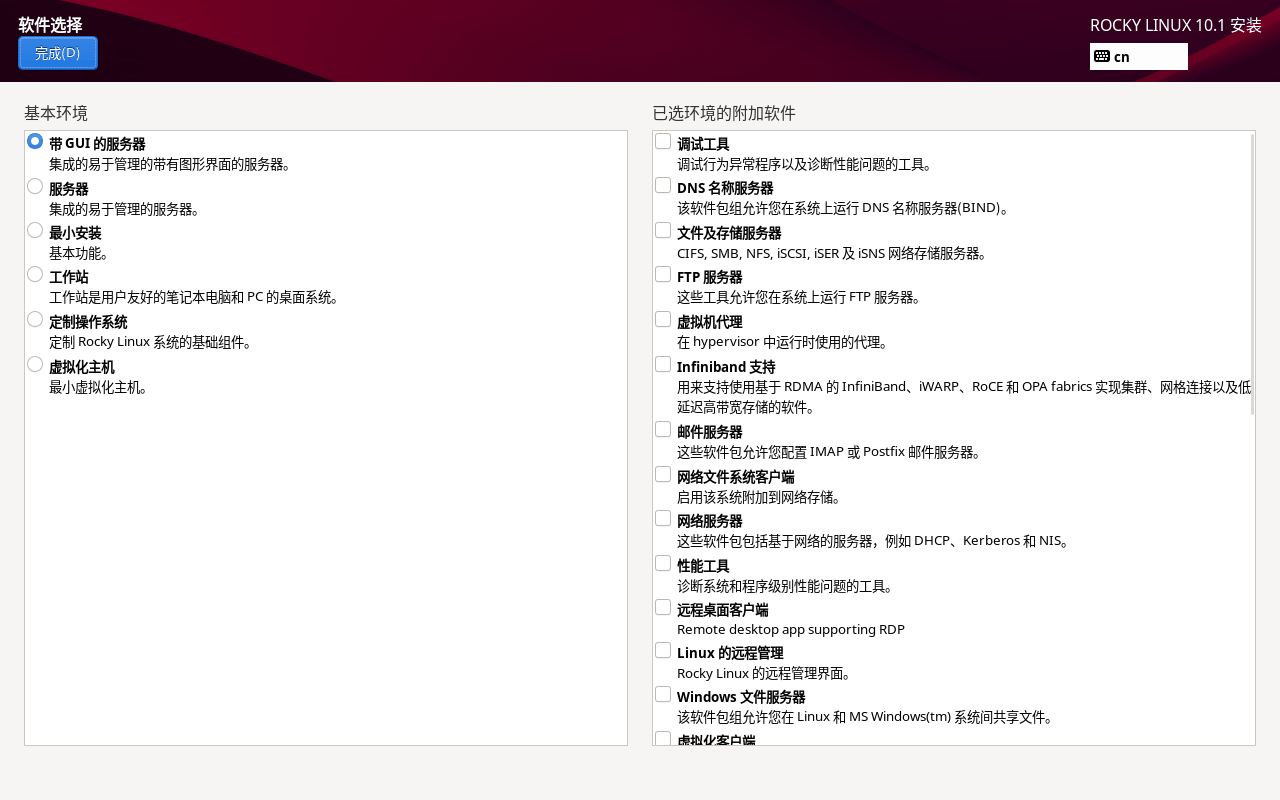
如果不想要 GUI 界面(只有命令行界面),可以在软件选择那里选服务器或者最小化安装,这个全看你自己,图方便的话直接默认带 GUI 的就完事了。
设置完后开始安装。
进去后会要你创建一个普通用户,随便建一个就好了,不重要,反正后面直接用 root 用户就行了😋。
四、配置网络和主机名
为了让 Linux 虚拟机能访问互联网和其他虚拟机及你的真实物理机,需要连接到 VMware Workstation Pro 自带的 NAT 网络 VMnet8。
打开终端。
输入:
nmtui
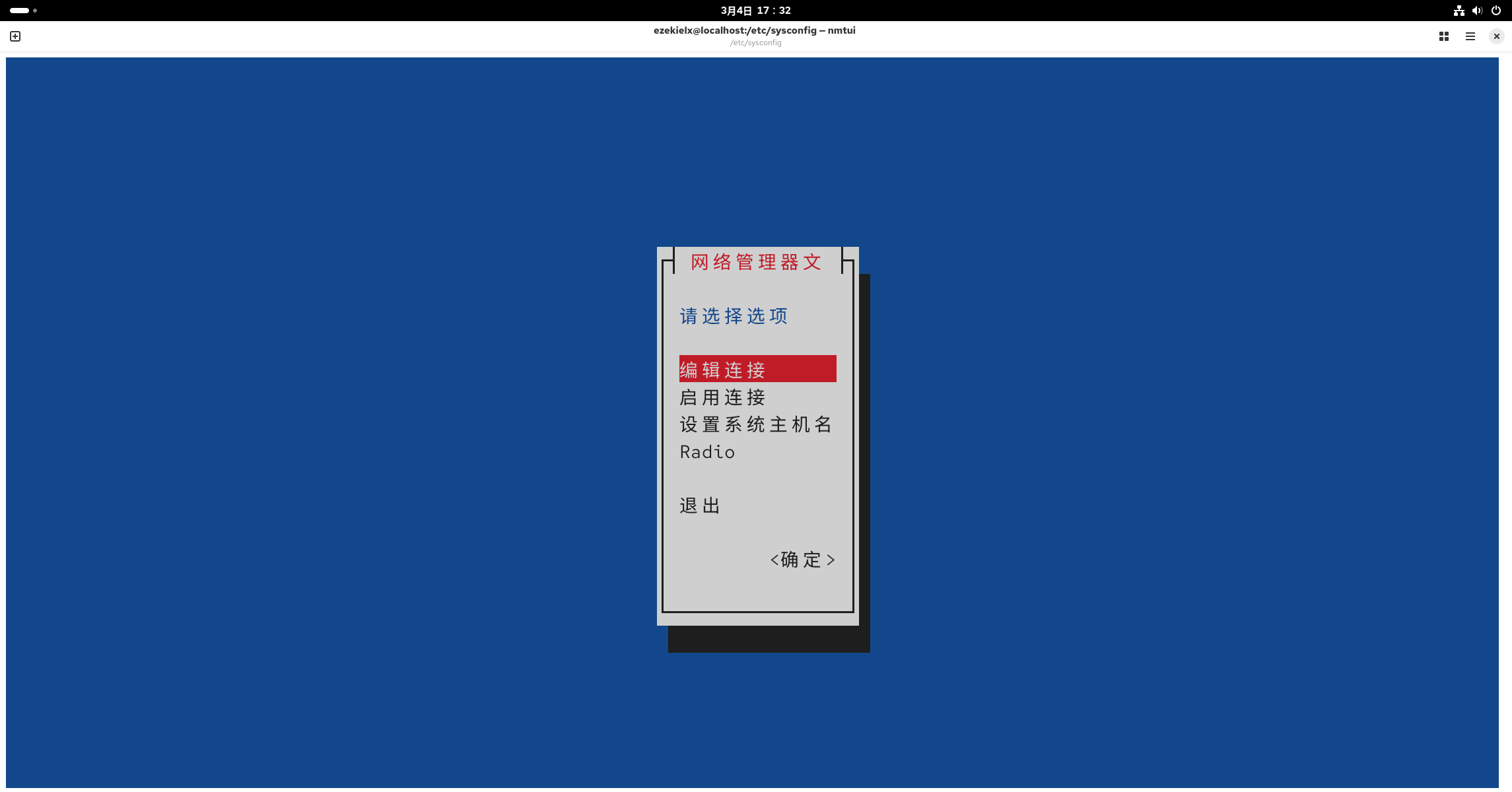
使用图形化界面修改主机配置(和直接改网络配置文件是一样的,nmtui 带图形界面方便一点)。
编辑连接,选择 ens 开头的配置,IPv4 改为手动。
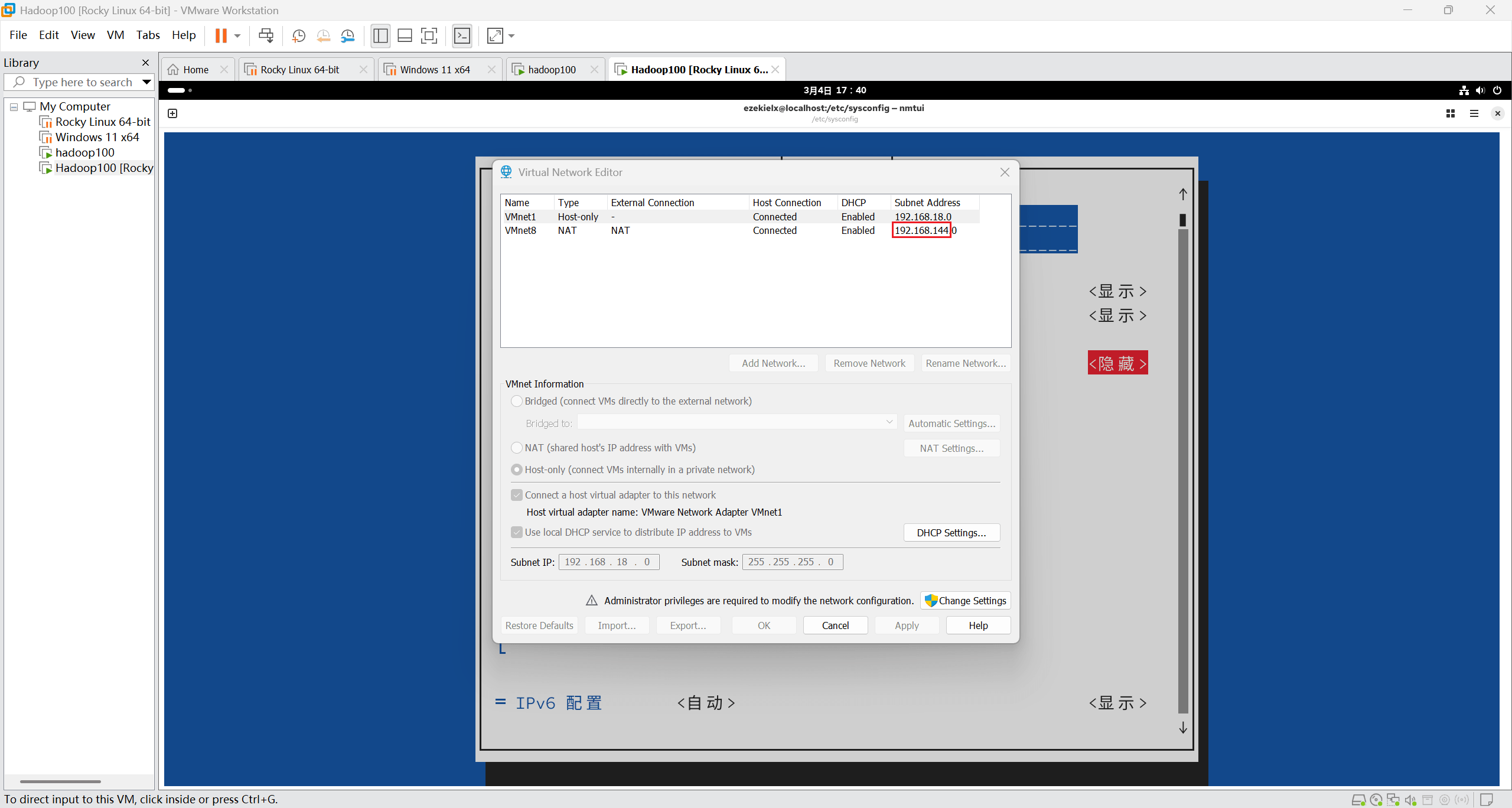
接下来打开 VMware Workstation,在 [Edit - Virtual Network Editor] 中查看 NAT 模式下的虚拟网卡 VMnet8 的网段(我的是 192.168.144.0)。
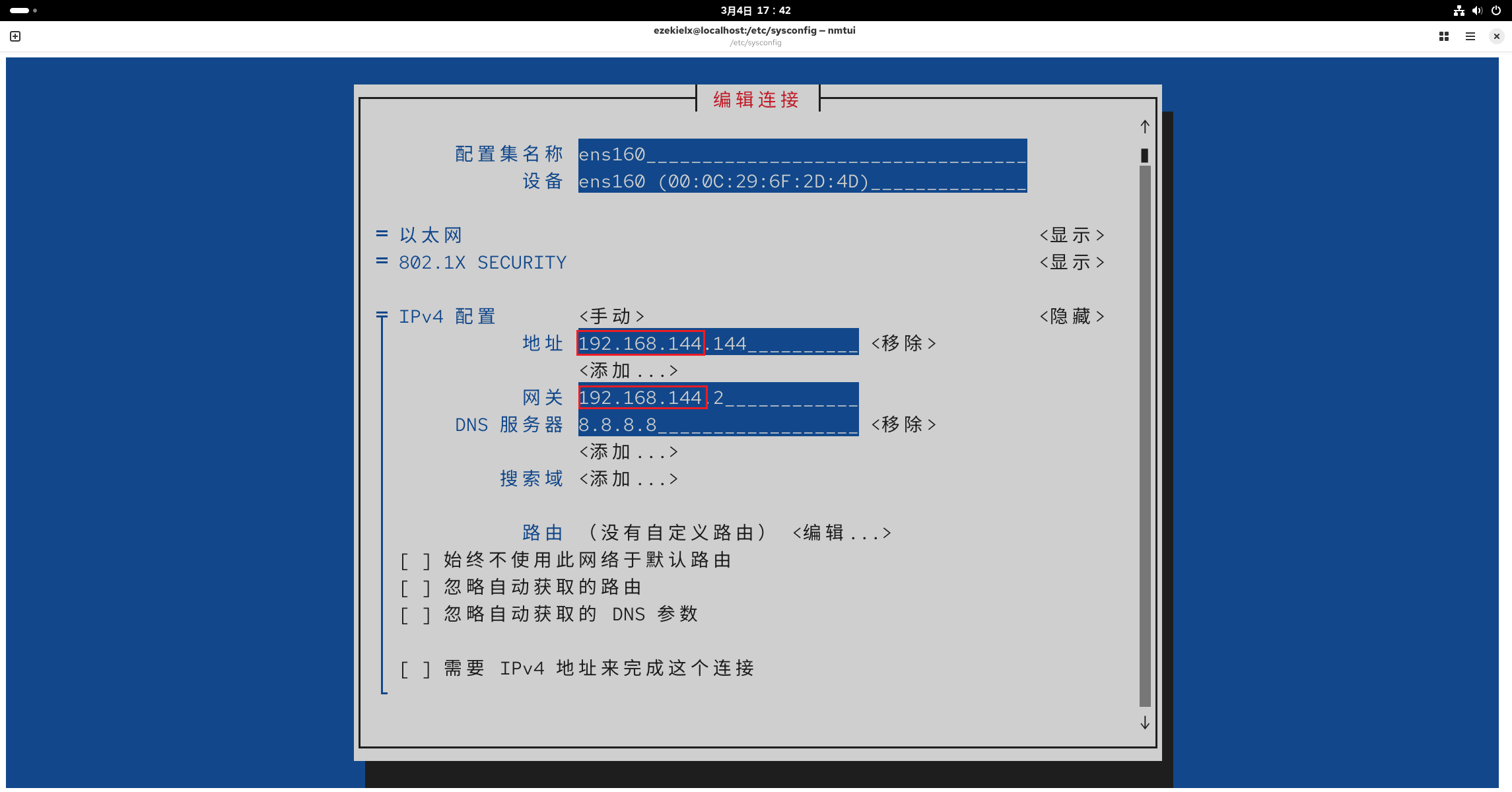
回到虚拟机中,将红框部分替换为刚刚查看的网段,地址那一栏红框外的那个三位数可以从 3 ~ 254 随便选一个填。
回到 nmtui 的主页,在启用连接中关闭后再打开一次 ens 开头的配置(就是刷新一下)。
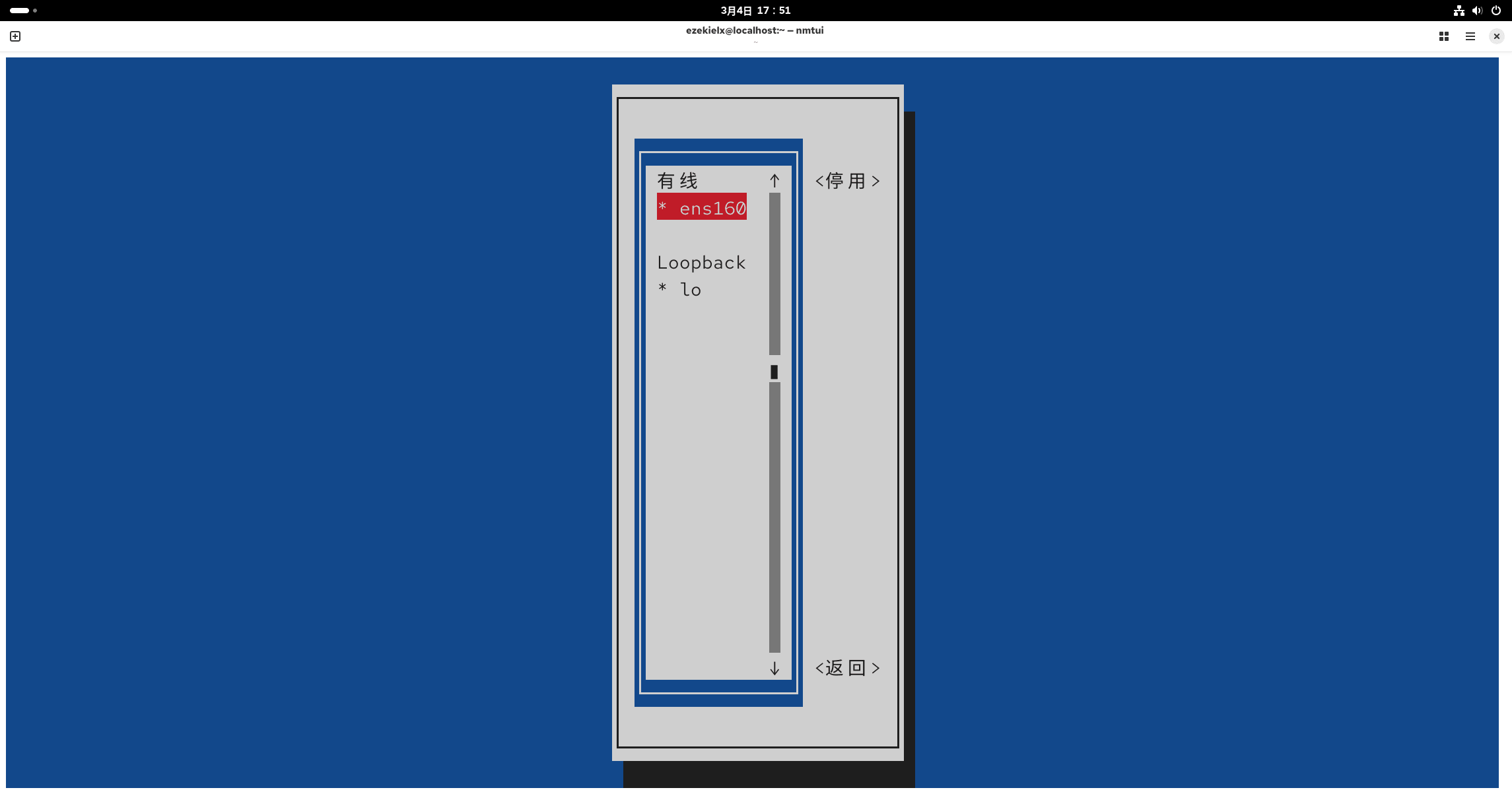
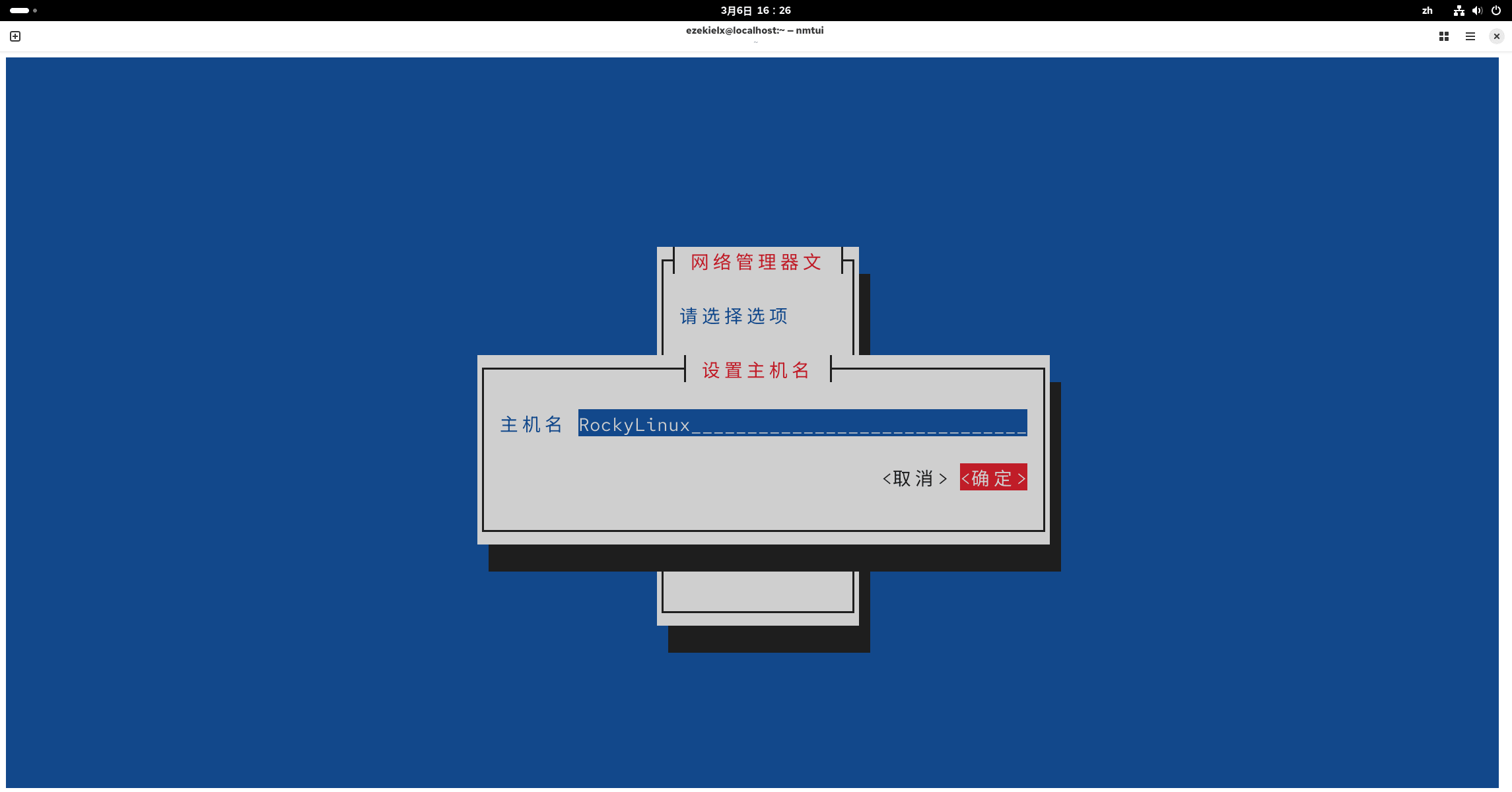
再回到主页,选择设置系统主机名,自己改一个喜欢的名字。
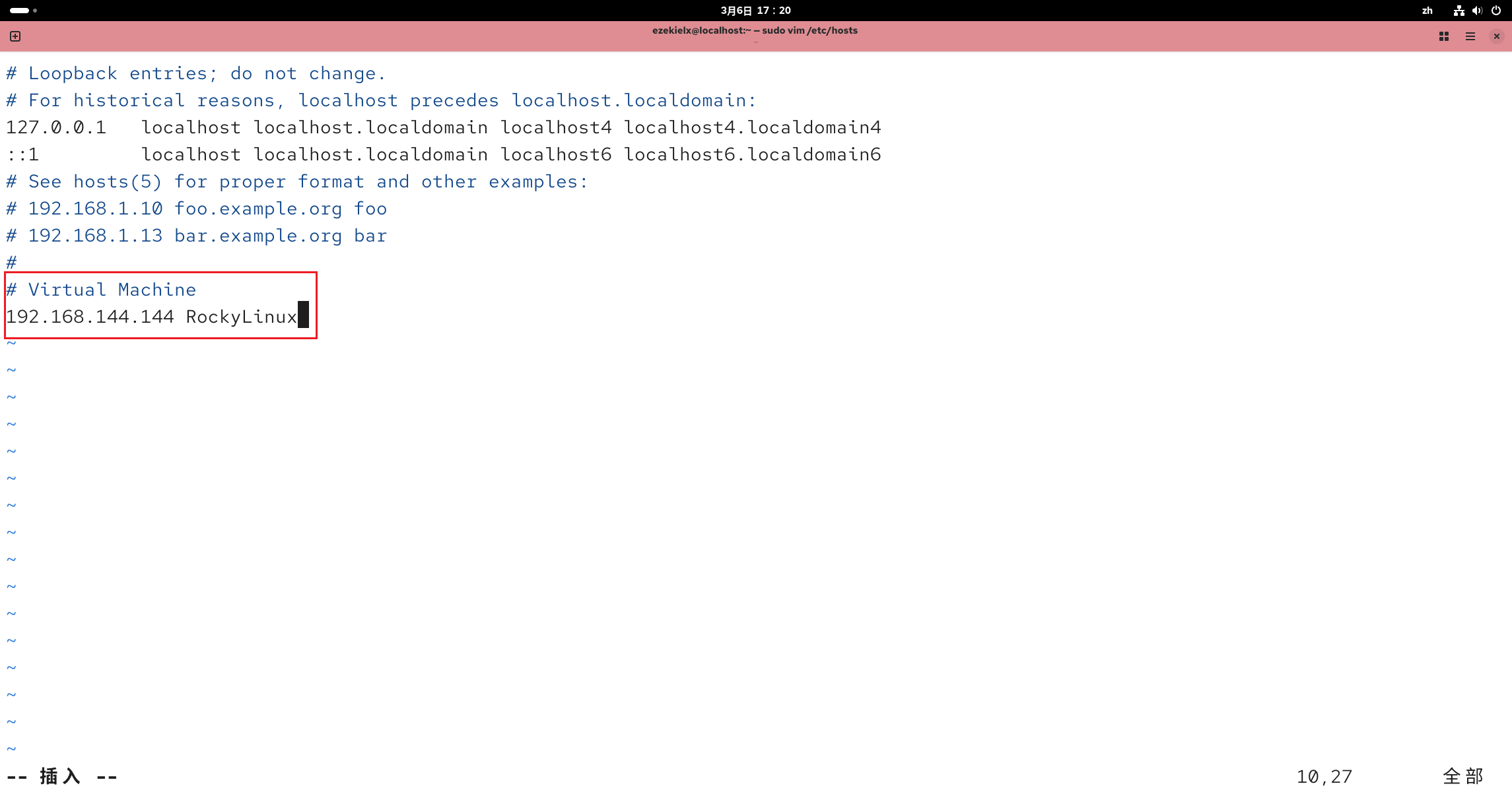
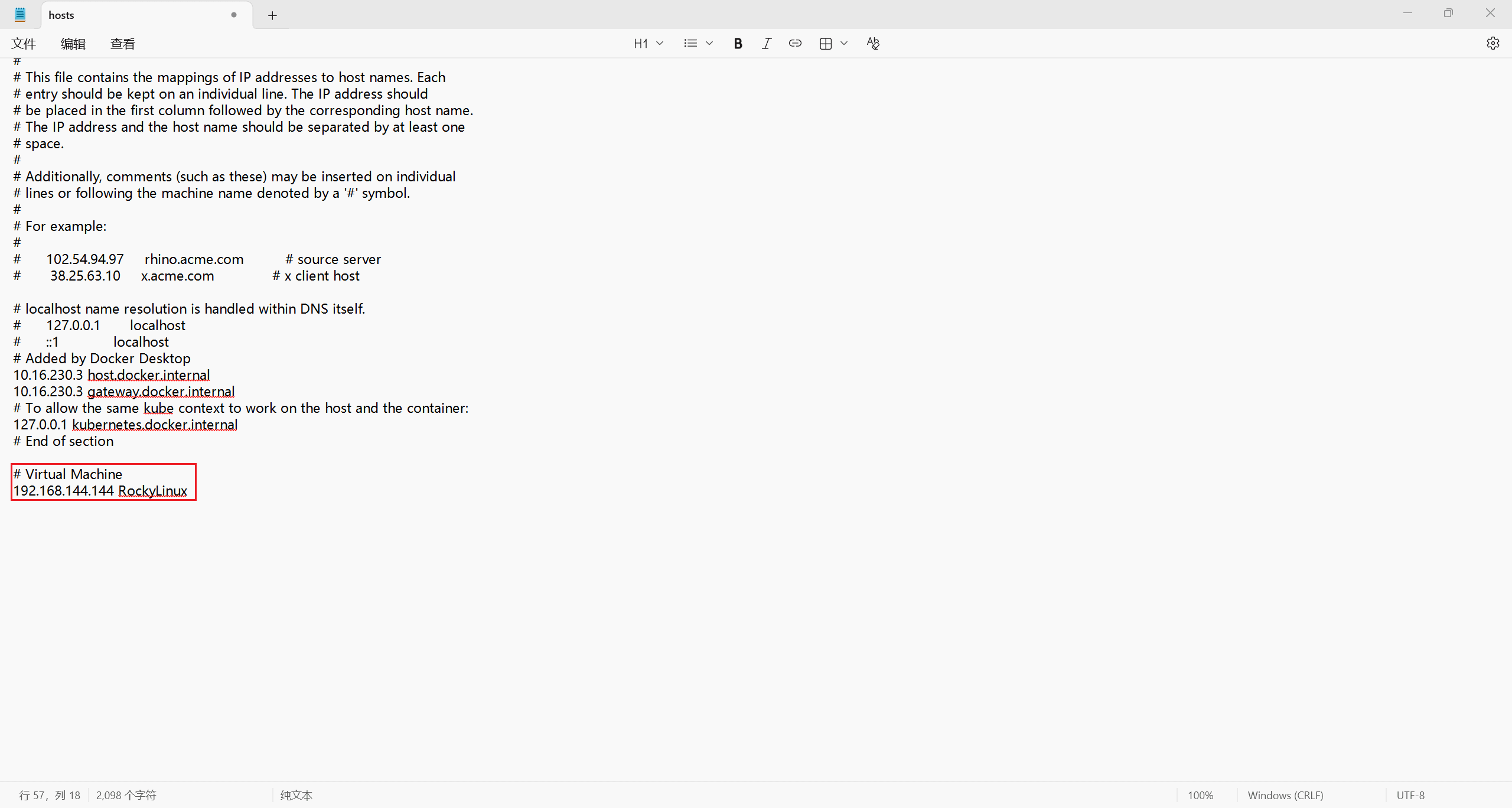
接下来更改物理机和虚拟机的 hosts 文件,让其能识别主机名与 IP 地址对应。
在虚拟机终端中输入:
sudo vim /etc/hosts
按 i 进入编辑模式,在末尾添加如下字段:
# Virtual Machine
192.168.144.144 RockyLinux
按 Esc,输入 :wq 回车保存并退出。
在你自己的 Windows 中的以管理员身份运行记事本,左上角 [文件 - 打开],打开 C:\Windows\System32\drivers\etc\hosts 路径下的文件,在末尾添加相同的字段。
物理机或者虚拟机都可以用以下命令看是否配置成功:
ping RockyLinux
PS C:\Users\Ezekielx> ping RockyLinux
正在 Ping RockyLinux [192.168.144.144] 具有 32 字节的数据:
来自 192.168.144.144 的回复: 字节=32 时间<1ms TTL=64
来自 192.168.144.144 的回复: 字节=32 时间<1ms TTL=64
来自 192.168.144.144 的回复: 字节=32 时间<1ms TTL=64
来自 192.168.144.144 的回复: 字节=32 时间<1ms TTL=64
192.168.144.144 的 Ping 统计信息:
数据包: 已发送 = 4,已接收 = 4,丢失 = 0 (0% 丢失),
往返行程的估计时间(以毫秒为单位):
最短 = 0ms,最长 = 0ms,平均 = 0ms
PS C:\Users\Ezekielx>
类似于这样就成功了。
最后关闭防火墙,否则会阻止物理机访问 WebUI。
sudo systemctl disable firewalld
sudo systemctl stop firewalld
ezekielx@RockyLinux:~$ sudo systemctl disable firewalld
sudo systemctl stop firewalld
[sudo] ezekielx 的密码:
Removed '/etc/systemd/system/multi-user.target.wants/firewalld.service'.
Removed '/etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service'.
ezekielx@RockyLinux:~$
五、创建 Hadoop 运行用户
在安装和运行 Hadoop 时,通常不建议使用 root 用户,而是创建一个专门的普通用户(如 hadoop)来运行 Hadoop 服务。
创建 hadoop 用户
sudo useradd hadoop
sudo passwd hadoop
创建时会要你输入设置密码,随便设置一个就行了😶🌫️。
设置 sudo 权限
wheel 组是 Linux 里一个特殊的管理员用户组,常用来控制谁可以获取 root 权限。
在一开始安装 Linux 时创建的那个用户是自动被添加在 wheel组中的,所以不用设置也可以使用 sudo 命令。
将 hadoop 用户添加到 wheel 组中:
sudo usermod -aG wheel hadoop
如果不想在后续使用 sudo 命令时输入密码,也可以修改配置文件设置 sudo 免密😎。
终端运行:
sudo visudo /etc/sudoers
到这一行:
%wheel ALL=(ALL) ALL
改成:
%wheel ALL=(ALL) NOPASSWD:ALL
创建 Hadoop 运行目录
/opt 一般是 Linux 系统用来存放第三方软件或手动安装的软件的目录,我们的 Hadoop 生态相关软件就安装在里面。但这个目录的所有者是 root,而运行 Hadoop 的用户是 hadoop,hadoop 用户没有修改 /opt 目录的权限,所以需要在 /opt 目录中给 hadoop 用户创建一个用于存放 Hadoop 生态相关软件的子目录。
创建子目录,给与 hadoop 用户权限:
sudo mkdir /opt/hadoop
sudo chown hadoop:hadoop /opt/hadoop
六、Hadoop 启动环境准备
1、安装 JDK
Hadoop 3.3.6 只支持 Java 8 和 Java 11(Hadoop Java Versions - Hadoop - Apache Software Foundation),我这里用 Java 8 的 JDK。
这里用 OpenJDK 的发行版 Corretto 8,下载地址:Downloads for Amazon Corretto 8 - Amazon Corretto 8
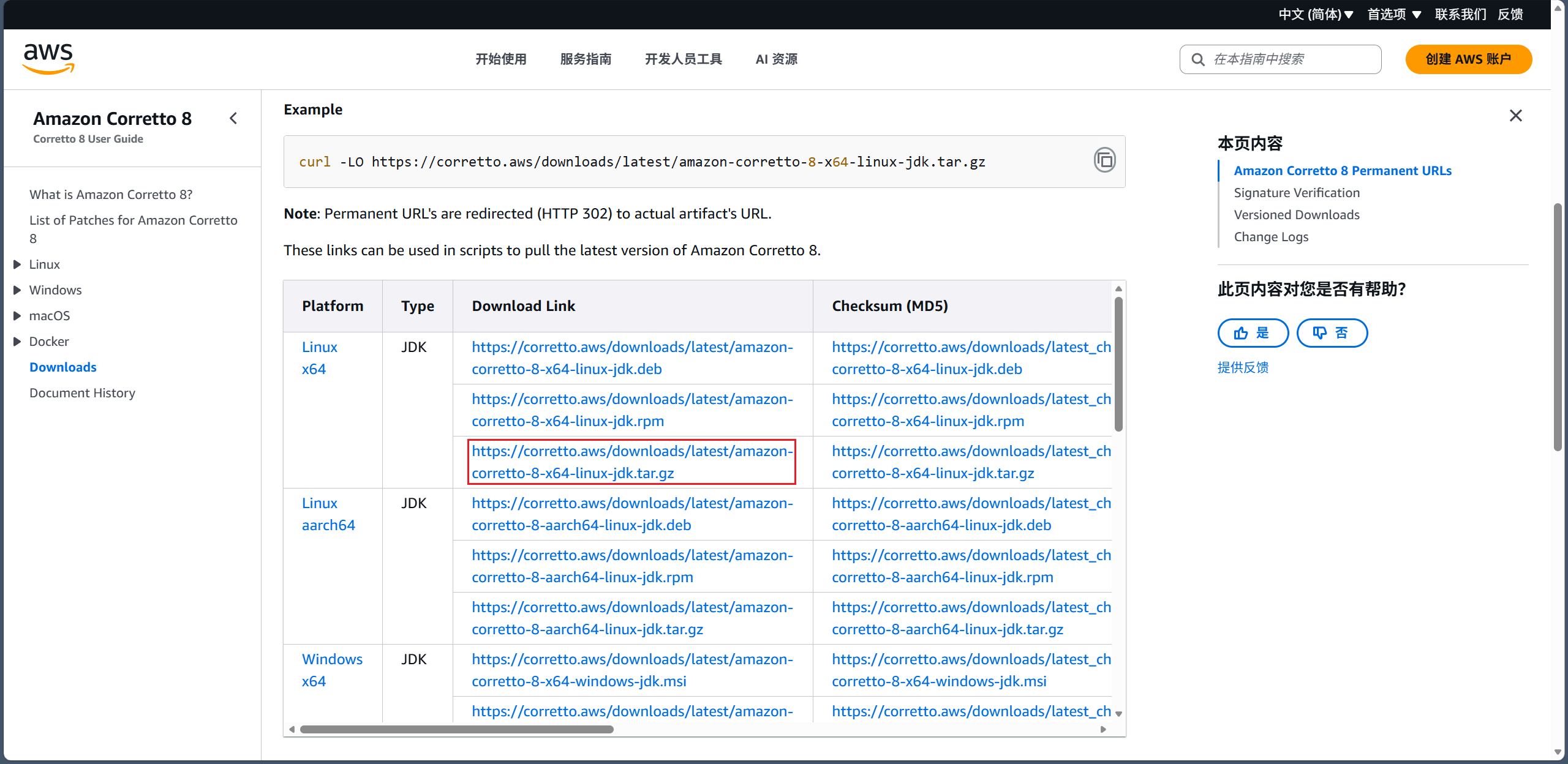
Corretto 8 百度网盘下载链接:https://pan.baidu.com/s/1rluJoZhO2aQOXQebesJ9Rw?pwd=lny9
现在要将下载好的压缩包上传到虚拟机里面,这个有很多办法,比如开个共享文件夹,scp 命令上传......
这里还是建议下一个 SSH 软件远程连接一下,大部分 SSH 软件都支持文件管理🤔,而且如果你添加了 GUI,直接用 GUI 的终端还会有一点卡😑。我用的 MobaXterm 连接的,具体使用方法我以前的文章写过,可以参考:MobaXterm:强大的远程网络工具,SSH 远程连接功能的使用 - 滕王阁 。
而且后面的环境配置操作都是使用 hadoop 用户,如果登录不是用的 hadoop 用户记得切换一下(切换命令:su hadoop)。
SSH 连接成功后在左边侧栏的文件浏览器中进入 /opt/hadoop 目录(也可以放别的目录,但放别的目录记得像上面创建 hadoop 目录一样改权限),把下载好的压缩包拖进去就能上传了。
上传虚拟机后终端输入:
cd /opt/hadoop
tar -zxvf amazon-corretto-8.482.08.1-linux-x64.tar.gz
mv amazon-corretto-8.482.08.1-linux-x64 amazon-corretto-8
rm -rf amazon-corretto-8.482.08.1-linux-x64.tar.gz
然后配置 Hadoop 的环境变量。
终端输入:
vim /home/hadoop/.bashrc
添加:
export JAVA_HOME=/opt/hadoop/amazon-corretto-8
export PATH=$PATH:$JAVA_HOME/bin
按 ESC,输入 :wq 回车保存并退出。
刷新环境变量:
source ~/.bashrc
验证是否配置成功:
java -version
[hadoop@RockyLinux hadoop]$ source ~/.bashrc
[hadoop@RockyLinux hadoop]$ java -version
openjdk version "1.8.0_482"
OpenJDK Runtime Environment Corretto-8.482.08.1 (build 1.8.0_482-b08)
OpenJDK 64-Bit Server VM Corretto-8.482.08.1 (build 25.482-b08, mixed mode)
[hadoop@RockyLinux hadoop]$
安装成功应该像上面这样。
接下来安装 Hadoop 🤗。
2、安装 Hadoop
官方文档地址:https://hadoop.apache.org/docs/stable/
如果想进一步了解可以去参考一下,不过可惜的是没有中文,网上的机翻中文网太生硬了,又完全看不了🥲。
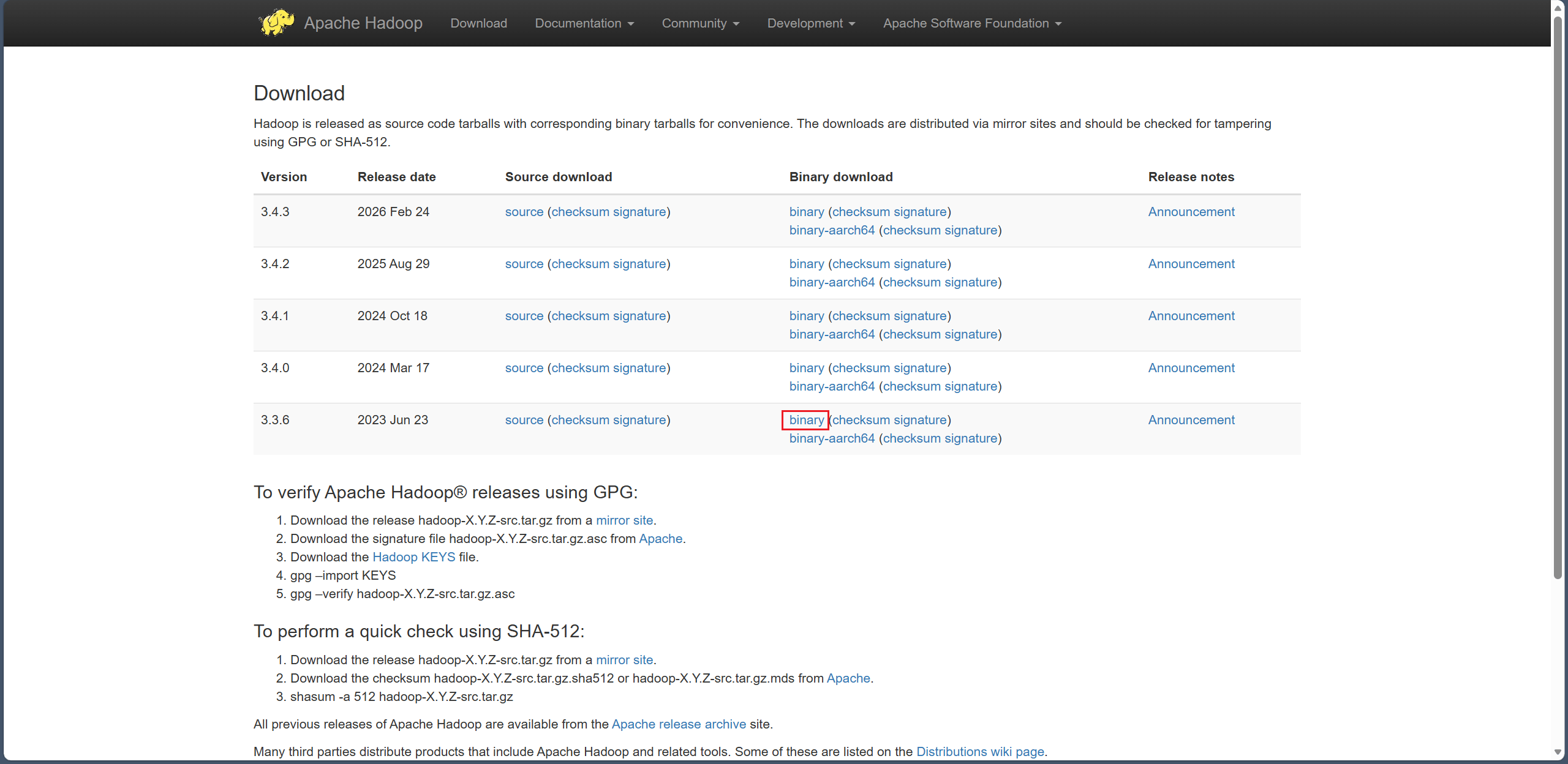
Hadoop 官网下载地址:https://hadoop.apache.org/releases.html
选个稳定一点的 3.3.6 下载(选那个 Binary download)😶🌫️。
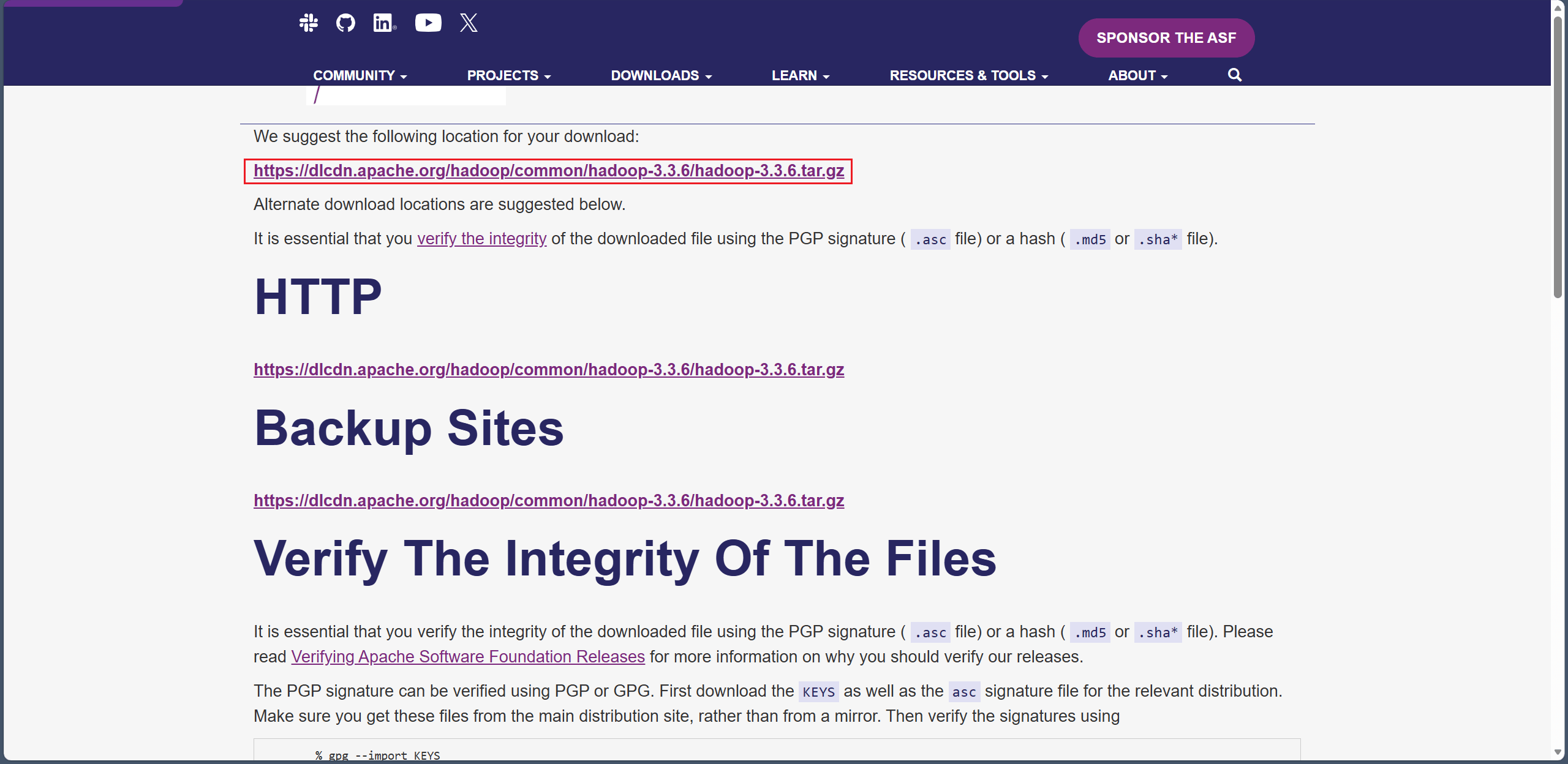
终端依次输入,解压并删除压缩包:
cd /opt/hadoop
tar -zxvf hadoop-3.3.6.tar.gz
rm -rf hadoop-3.3.6.tar.gz
然后配置 Hadoop 的环境变量。
终端输入:
vim /home/hadoop/.bashrc
按 i 进入编辑模式,添加:
export HADOOP_HOME=/opt/hadoop/hadoop-3.3.6
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
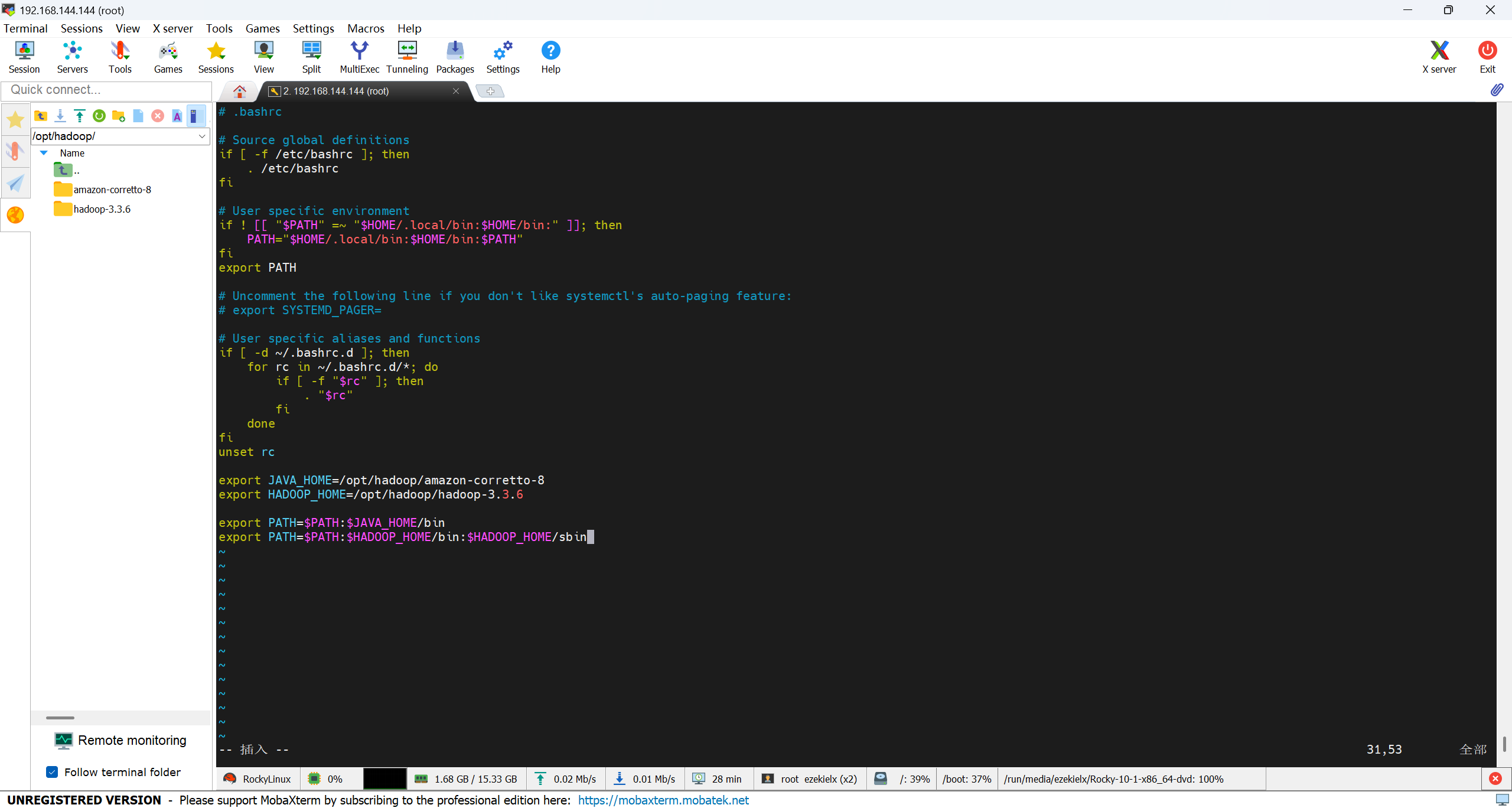
刷新环境变量:
source ~/.bashrc
验证是否配置成功:
hadoop version
[hadoop@RockyLinux hadoop]$ source ~/.bashrc
[hadoop@RockyLinux hadoop]$ hadoop version
Hadoop 3.3.6
Source code repository https://github.com/apache/hadoop.git -r 1be78238728da9266a4f88195058f08fd012bf9c
Compiled by ubuntu on 2023-06-18T08:22Z
Compiled on platform linux-x86_64
Compiled with protoc 3.7.1
From source with checksum 5652179ad55f76cb287d9c633bb53bbd
This command was run using /opt/hadoop/hadoop-3.3.6/share/hadoop/common/hadoop-common-3.3.6.jar
[hadoop@RockyLinux hadoop]$
像这样就可以下一步了😋。
3、配置 Hadoop 运行使用的 JDK 路径
官方文档参考:
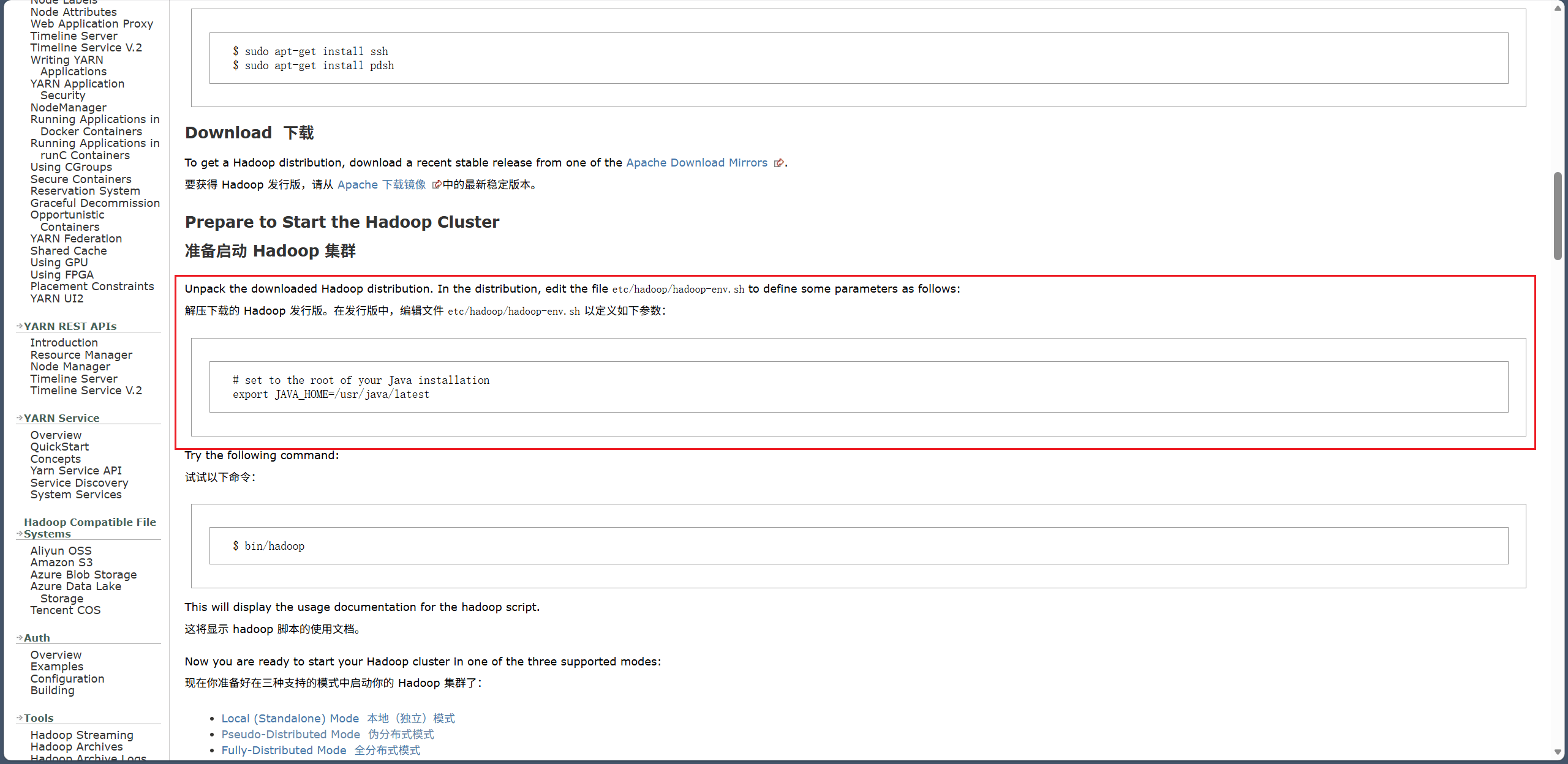
编辑 Hadoop 环境脚本:
vim /opt/hadoop/hadoop-3.3.6/etc/hadoop/hadoop-env.sh
找到 export JAVA_HOME= 这一行,修改为:
export JAVA_HOME=/opt/hadoop/amazon-corretto-8
如果你使用是的 MobaXterm,觉得命令行太难编辑,可以直接在 MobaXterm 左边的文件浏览器打开你要编辑的文件,使用物理机上的编辑软件(记事本、VSCode)进行编辑。
七、Hadoop 伪分布式环境配置
1、修改配置文件
首先配置核心模块 HDFS(分布式存储系统)和 Yarn(集群资源管理和任务调度)。官方文档参考:
编辑 /opt/hadoop/hadoop-3.3.6/etc/hadoop/core-site.xml 配置文件:
vim /opt/hadoop/hadoop-3.3.6/etc/hadoop/core-site.xml
<configuration> 中添加以下内容:
<property>
<name>fs.defaultFS</name>
<value>hdfs://RockyLinux:9000</value>
</property>
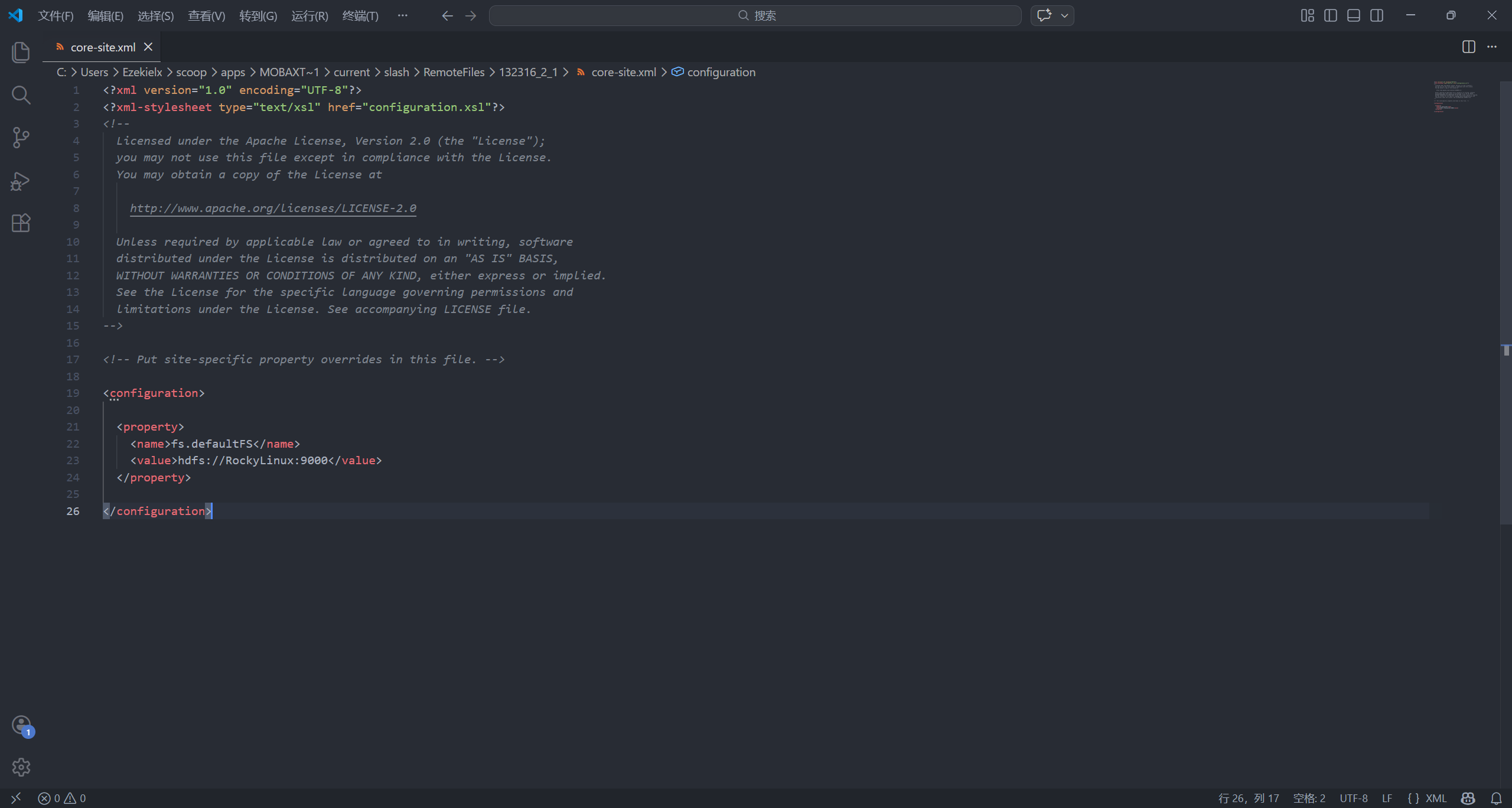
fs.defaultFS 指定 Hadoop 默认访问的文件系统地址。注意,<value> 中的 RockyLinux 代表是主机名,如果你和我不同,改成你自己的(你可以理解为网址,是不分大小写的)!
编辑 /opt/hadoop/hadoop-3.3.6/etc/hadoop/hdfs-site.xml 配置文件:
vim /opt/hadoop/hadoop-3.3.6/etc/hadoop/hdfs-site.xml
<configuration> 中添加以下内容:
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
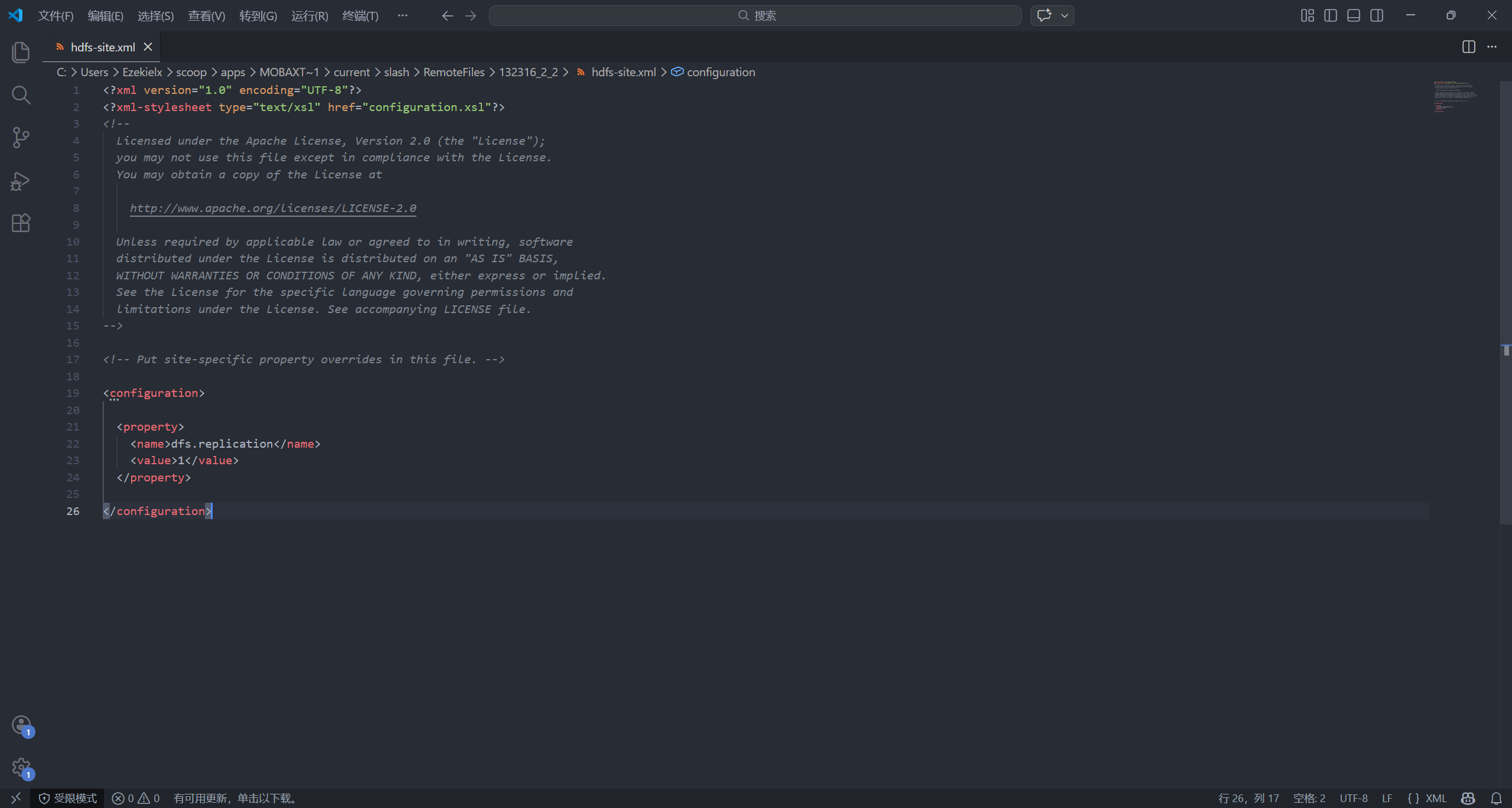
dfs.replication 指定 HDFS 数据块副本数量,即每个数据块保存多少份。由于伪分布式只有 一个 DataNode,如果设置超过 1 会报错。
然后配置让 Yarn 上以伪分布式模式运行 MapReduce 作业。官方文档参考:
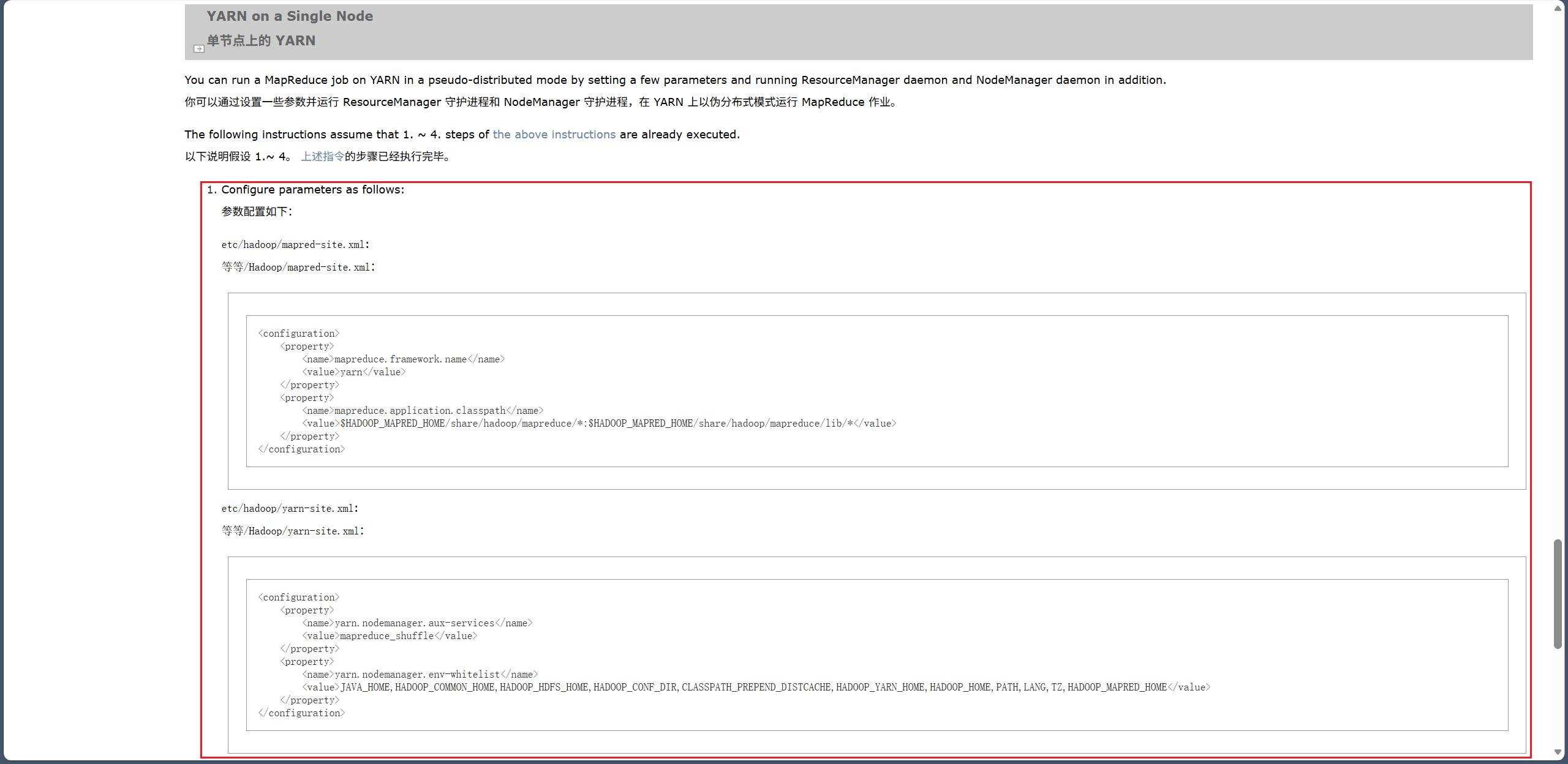
编辑 /opt/hadoop/hadoop-3.3.6/etc/hadoop/mapred-site.xml 配置文件:
vim /opt/hadoop/hadoop-3.3.6/etc/hadoop/mapred-site.xml
<configuration> 中添加以下内容:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>
$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*
</value>
</property>
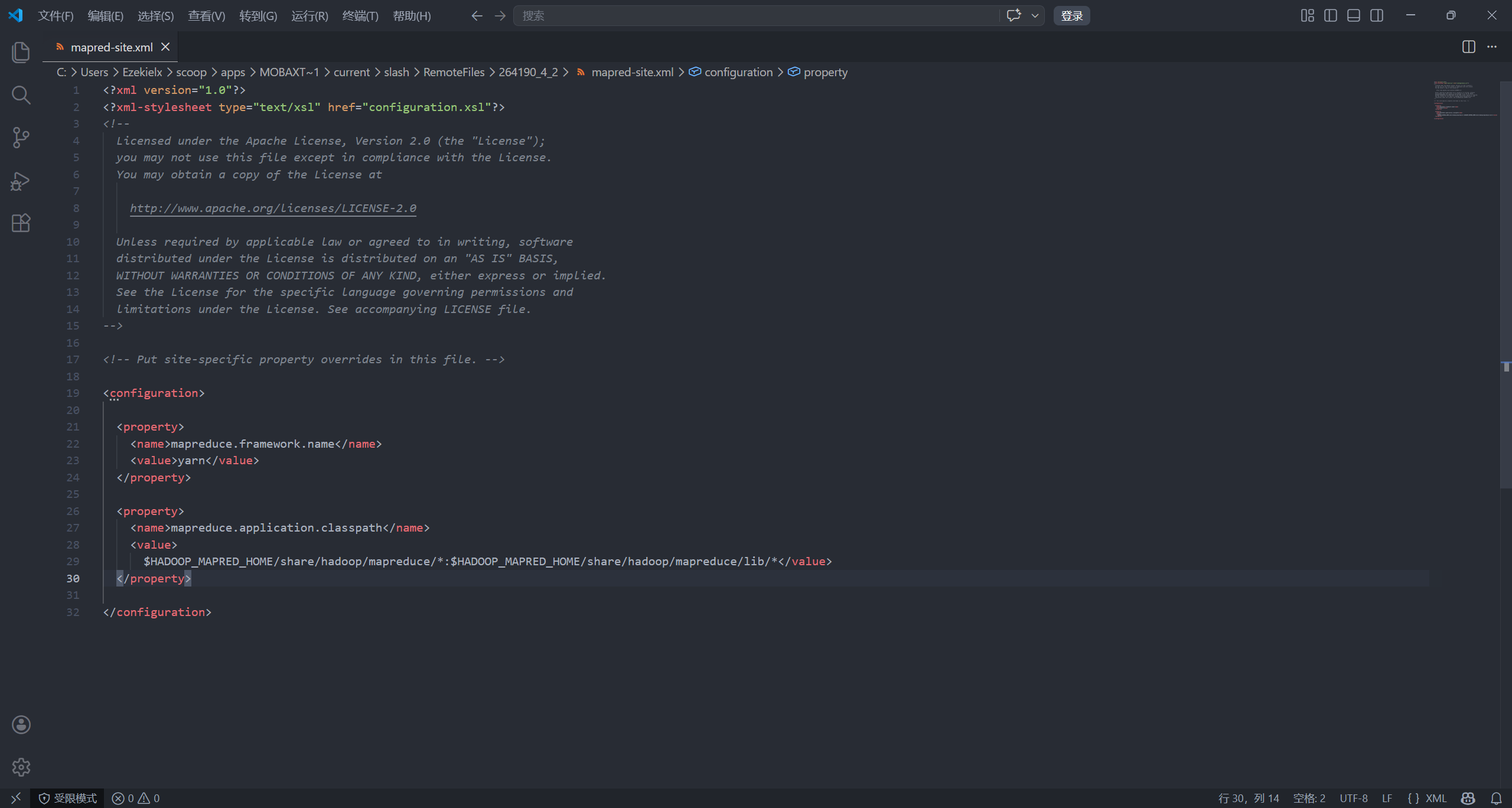
mapreduce.framework.name用于指定 MapReduce 的运行模式为 yarn。MapReduce 有两种运行方式:local(本地模式,单进程)、yarn(yarn 集群上运行)。mapreduce.application.classpath:指定 MapReduce 任务运行时的 Java 类路径,告诉容器去哪里找 Hadoop 和 MapReduce 所需的 jar 包。
编辑 /opt/hadoop/hadoop-3.3.6/etc/hadoop/yarn-site.xml 配置文件:
vim /opt/hadoop/hadoop-3.3.6/etc/hadoop/yarn-site.xml
<configuration> 中添加以下内容:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ,HADOOP_MAPRED_HOME</value>
</property>
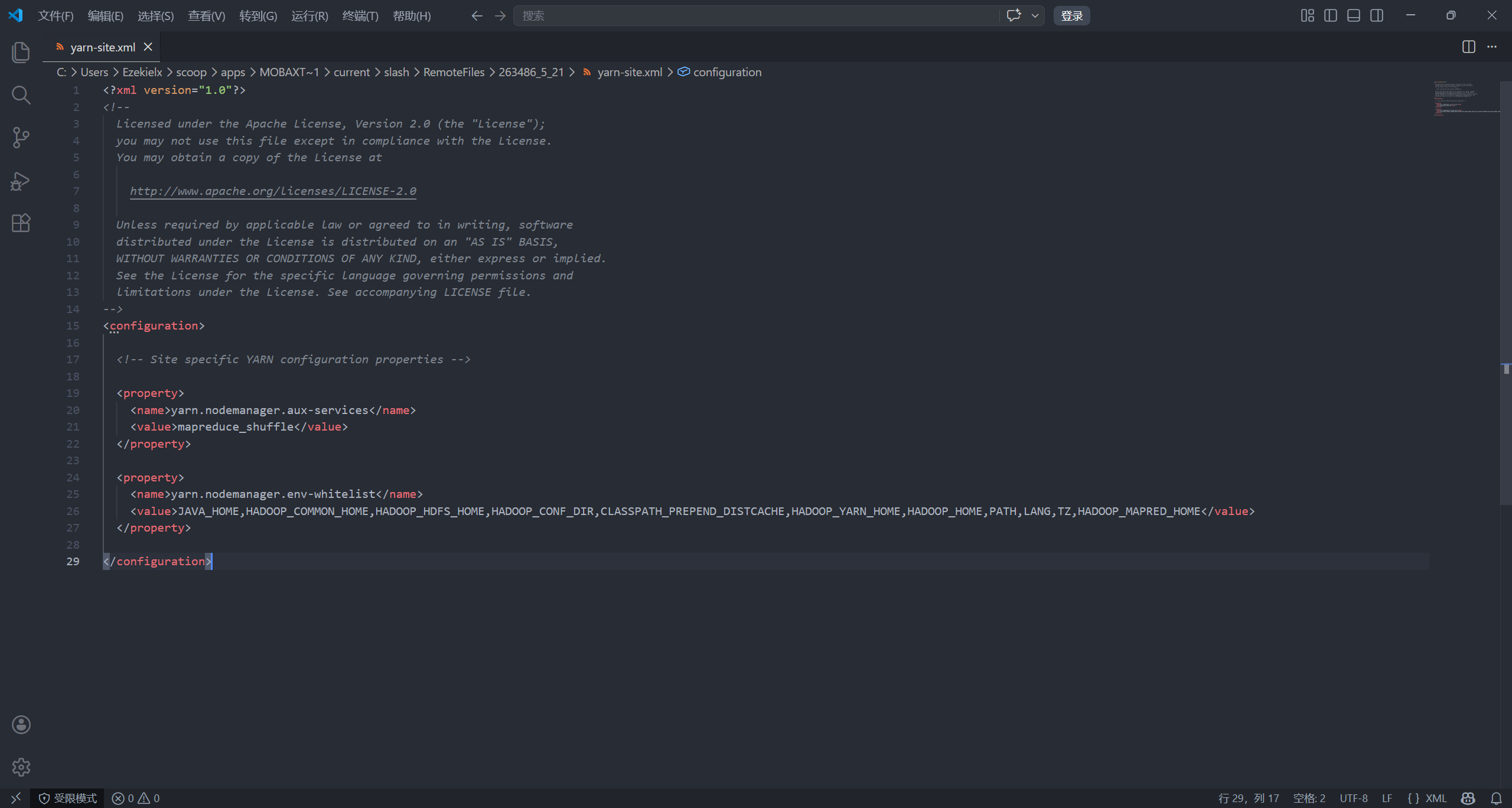
注意⚠️⚠️⚠️,如果和我一样使用 VSCode 打开,千万不要使用一键格式化,否则会导致
yarn.nodemanager.env-whitelist一项的值前面出现空行,导致配置识别不到。你卤味的,做个项目卡了我几天,急头白脸找解决方法找😵我了,在换遍搜索引擎终于在 Google 引擎的不知名小角落找到了是 VSCode 格式化自动加空格的原因,这谁能绷住不笑。
yarn.nodemanager.aux-services用于为 MapReduce 应用设置 Shuffle 服务。Shuffle 服务用于将 Map 节点的输出数据传给 Reduce 节点。yarn.nodemanager.env-whitelist:列出 NodeManager 启动的容器 允许访问的环境变量,未列出的变量容器无法看到,用于安全和一致性。
可以看到 mapreduce.application.classpath 使用了许多之前没有配置的环境变量,但那些其实在 HADOOP_HOME 中都有,单独写出来应该是为了区分不同版本的,我们这里就一个 Hadoop,所以在 hadoop-env.sh 中都改为当前 hadoop 的家目录。
编辑 /opt/hadoop/hadoop-3.3.6/etc/hadoop/hadoop-env.sh 配置文件:
vim /opt/hadoop/hadoop-3.3.6/etc/hadoop/hadoop-env.sh
末尾(或者随便找个地方)添加:
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
2、设置 SSH 免密登录
你可能会疑问,为什么明明伪分布式模式就在一台机器上运行,设置 SSH 免密是要登录到哪台机器去🧐?
虽然伪分布式只有一台机器,但 Hadoop 仍然按集群逻辑运行,而 Hadoop 在各个节点执行命令又是通过 SSH 的,使用如果不配置 SSH 免密,Hadoop 每次操作节点时都要提示你输入密码,所以 SSH 免密是必要的👻。
首先切换到运行 Hadoop 的 hadoop 用户:
su hadoop
生成 SSH 公私钥(输入命令后一直回车就可以了,不用管那些提示):
ssh-keygen -t rsa
[hadoop@RockyLinux ~]$ ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/home/hadoop/.ssh/id_rsa):
Created directory '/home/hadoop/.ssh'.
Enter passphrase for "/home/hadoop/.ssh/id_rsa" (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/hadoop/.ssh/id_rsa
Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub
The key fingerprint is:
SHA256:8DwG5mMlTpbLj8mZ/s9BIXRU2Y1IKQrje2p6m/bCk4s hadoop@RockyLinux
The key's randomart image is:
+---[RSA 3072]----+
| ..ooo= o |
| oo .. + o .|
| .Ooo... |
| B.O.. . |
| B.S . |
| o.O.o |
| .*+. . |
| oX. . . |
| E==Bo.o |
+----[SHA256]-----+
[hadoop@RockyLinux ~]$
之后复制公钥到授权文件:
ssh-copy-id RockyLinux
[hadoop@RockyLinux ~]$ ssh-copy-id RockyLinux
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/home/hadoop/.ssh/id_rsa.pub"
The authenticity of host 'rockylinux (192.168.144.144)' can't be established.
ED25519 key fingerprint is SHA256:sboDlw6zOneUBsH7uIXSAtByegm3B6voRFlMFWbnxS0.
This key is not known by any other names.
Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
hadoop@rockylinux's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'RockyLinux'"
and check to make sure that only the key(s) you wanted were added.
[hadoop@RockyLinux ~]$
执行命令后第一次询问输入 yes,第二次输入 root 用户密码,像上面这样。
八、运行 Hadoop
1、启动 Hadoop
首先格式化文件系统(记得使用 hadoop 用户,官方不建议使用 root 用户运行,否则会报错):
hdfs namenode -format
启动文件管理系统 HDFS(NameNode + DataNode):
start-dfs.sh
启动后会运行:
- NameNode
- DataNode
- SecondaryNameNode
启动资源管理系统 Yarn:
start-yarn.sh
启动后会运行:
- ResourceManager
- NodeManager
参考是否运行成功:
jps
[hadoop@RockyLinux hadoop]$ jps
20916 ResourceManager
21044 NodeManager
20359 DataNode
20567 SecondaryNameNode
20171 NameNode
21437 Jps
[hadoop@RockyLinux hadoop]$
启动成功应该能看到以上内容😋。
也可以使用:
start-all.sh
这个命令会直接启动所有运行在 Hadoop 上的软件,比如 HBase、Zookeeper 等。而上面两条命令是只分开启动 HDFS 和 Yarn。
2、访问 WebUI
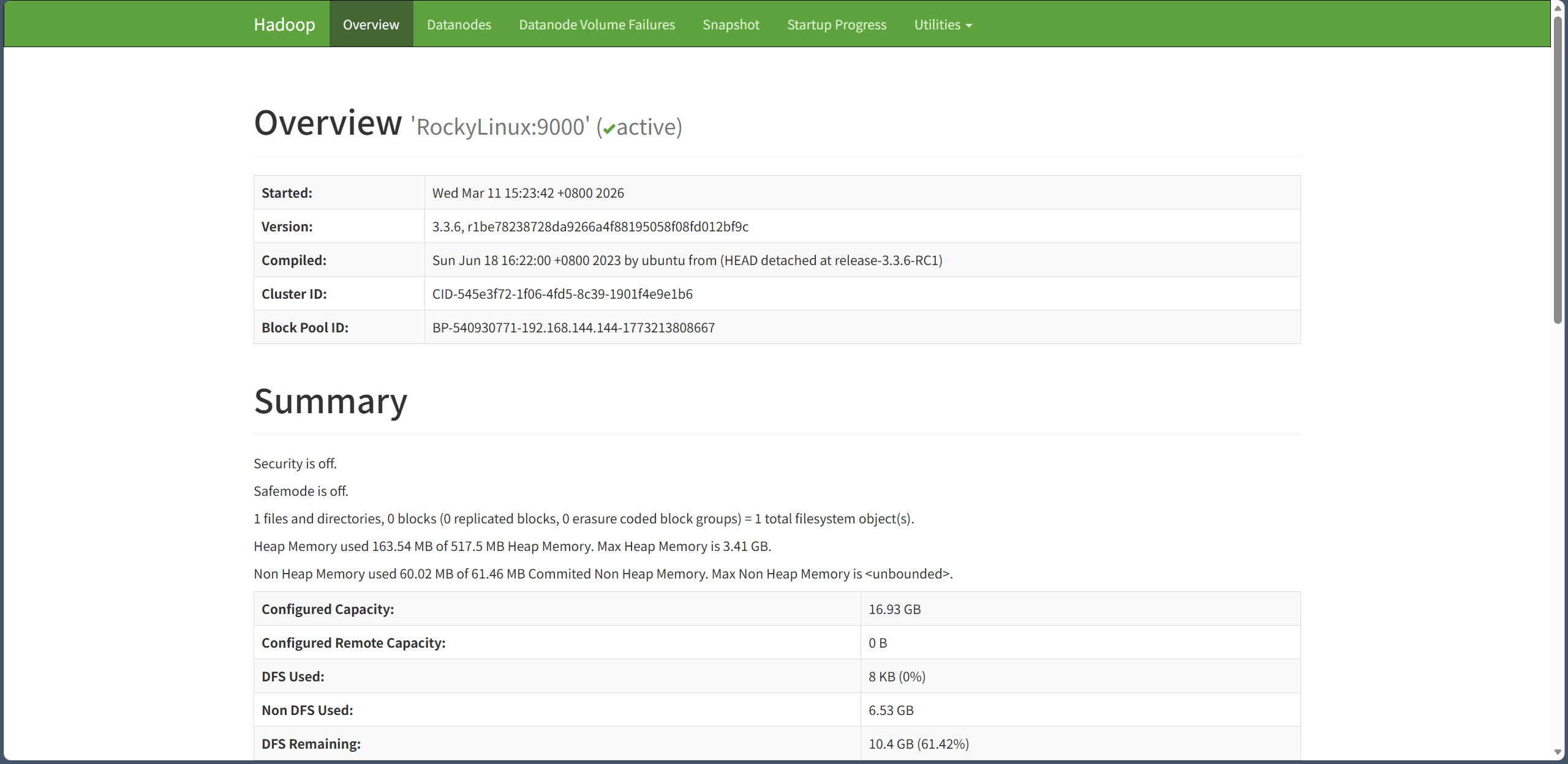
HDFS NameNode WebUI 访问地址:http://RockyLinux:9870/ 。
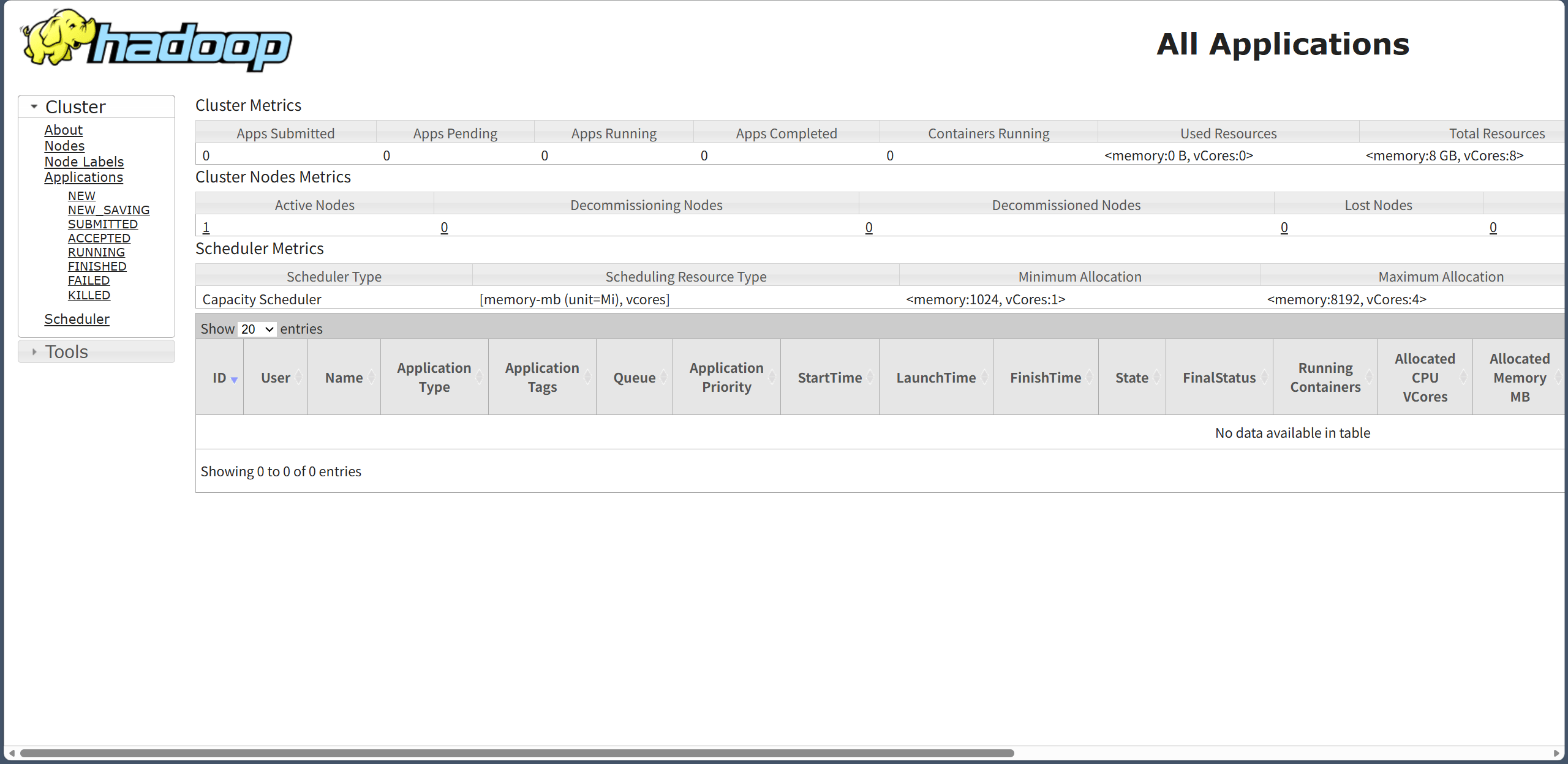
Yarn ResourceManager WebUI 访问地址:http://RockyLinux:8088/ 。
2、停止 Hadoop
停止文件管理系统 HDFS:
stop-dfs.sh
停止资源管理系统 Yarn:
stop-yarn.sh
同样的一键停止脚本:
stop-all.sh
九、后记
由于放假手贱重装系统了,想着反正要重装环境就干脆写一篇文章的,没想到这么难写(做起来倒不难)😭。
马上要准备考研了,花时间到这种小癖好上自己真的有点绷不住😶🌫️。