
Hadoop Chapter 6:Hadoop Serialization and Compression(Hadoop 的序列化与压缩)
一、Serialization Overview(序列化概述)
计算机以 0 和 1 的比特形式读取、存储和处理数据。序列化是指将任何对象的状态或数据转换为一系列比特(0 和 1)的过程,从而便于计算机将其存储在内存或文件格式中。要将数据传输到其他计算机时,通常使用序列化后的数据。
在进行序列化之前,一个重要的考虑因素是:数据应该采用嵌套结构还是扁平结构。常见的扁平结构数据包括文本文件、CSV 文件;而嵌套结构数据则包括 YAML 和 JSON 文件。
序列化会使用一种特定的序列化格式,这种格式也可用于反序列化(即将比特数据还原为原始对象)。另外,在将数据从一个系统传输到另一个 系统时,还需要考虑另一个重要因素:计算机系统可能在操作系统、硬件组成和内部二进制存储格式上存在很大差异。数据序列化正是在这种场景下提供了一个高效的解决方案。
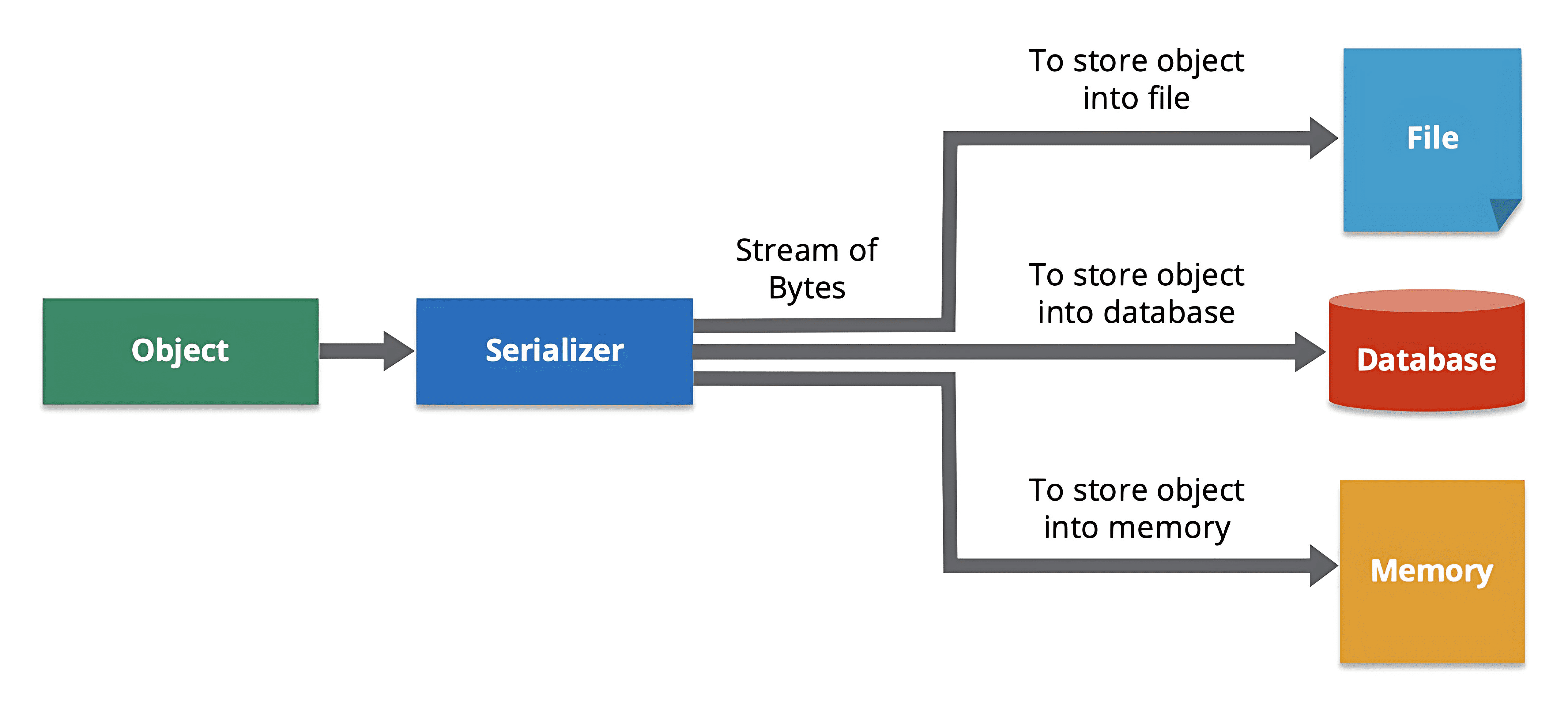
可以根据速度、数据限制、人类需求和存储等因素选择许多不同的序列化格式。常用的格式有 YAML、JSON、CSV、XML 等。一旦序列化的数据被传输并接收,就需要在目的地进行反序列化。
反向过程,也称反序列化,即从一系列字节中构造出数据结构或对象。反序列化过程会重新创建该对象,从而使数据在编程语言中作为本地结构更易于读取和修改。
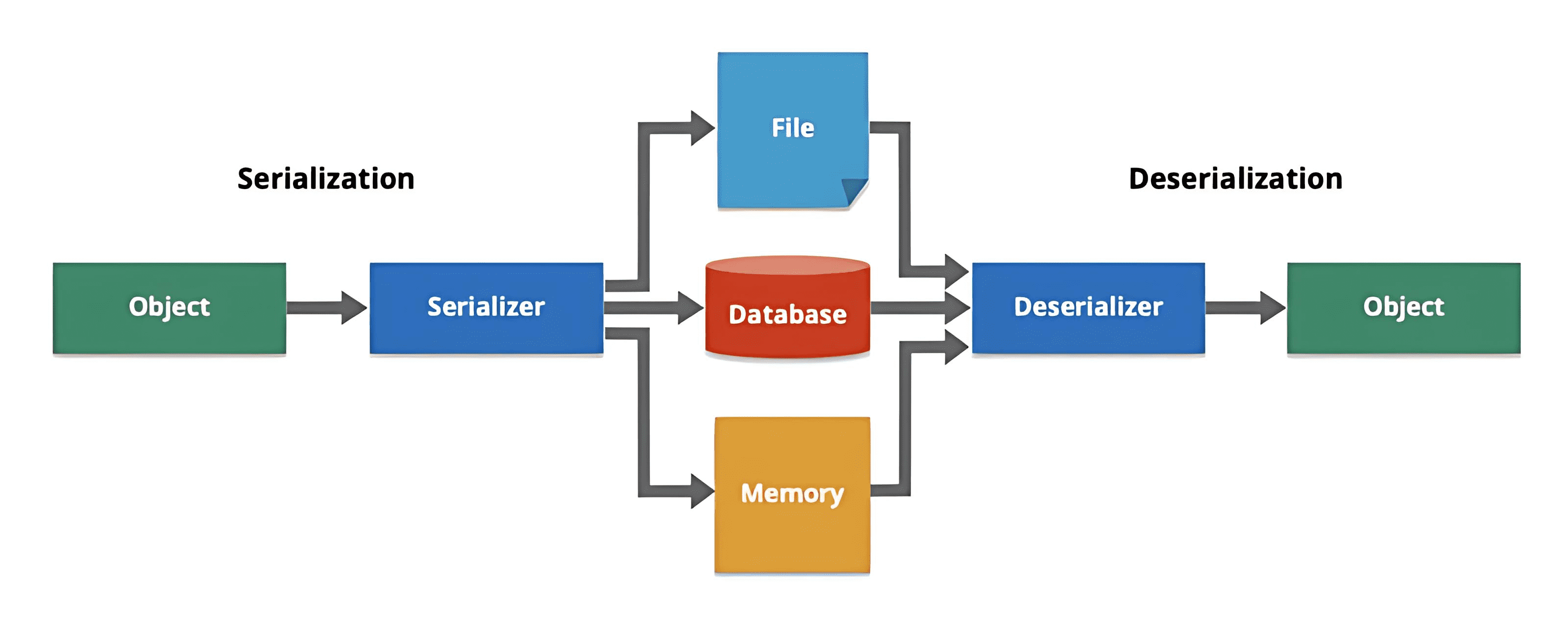
1、Data Serialization in Distributed Systems(分布式系统中的数据序列化)
在一些分布式系统中,数据会被分散存储在多个服务器(也叫节点)上,每份数据通常还有一个或多个副本。当你需要用某份数据时,如果这份数据不在你所在的本地节点,系统就会从别的节点上取回来。在这个过程中,系统需要把数据“打包”(序列化)进行传输,然后在接收端“拆包”(反序列化)再使用。
这种序列化机制在以下常见场景中都会用到:
- 向 Map 中添加键值对,比如保存一条用户 ID 和资料的对应关系
- 把数据放入队列、集合或列表中,用于排队处理、任务分发等操作
- 在 Map 里处理某条数据项,例如读取或更新一条记录
- 锁定某个对象,防止多个节点同时修改,比如多个用户同时抢购同一个商品时,要先锁住这件商品的库存数据
- 向“主题”发送消息,即发送一条消息到一个公共频道,所有订阅了这个主题的节点或应用都可以收到并处理这条消息
2、Data Serialization in Big Data(大数据中的数据序列化)
大数据系统中常常包含被称为“无模式(schema-less)”的技术或数据。这意味着这些系统中管理的数据并不遵循由模式严格定义的结构。
在这种环境下,序列化带来了以下几个好处:
- **结构性:**通过在读取数据时进行序列化,插入某种结构或规则,我们可以避免读取那些缺少必要字段、分类错误或不符合质量要求的数据。
- **可移植性:**大数据来自各种不同的系统,可能使用不同的编程语言编写。序列化能够提供所需的一致性,从而使这些数据可以传输到其他企业系统或应用程序中。
- **版本控制:**大数据是不断变化的。序列化使我们能够为对象添加版本号,方便进行生命周期管理。
3、Data Serialization in Hadoop(Hadoop 中的数据序列化)
在 Hadoop 中,不同的组件通过远程过程调用(RPC)进行通信。调用方进程会将要执行的函数名及其参数序列化为字节流,然后发送给被调用方进程。被调用方进程对这个字节流进行反序列化,解析出函数类型,并使用提供的参数来执行该函数。执行结果再被序列化后返回给调用方。这个流程天然要求序列化和反序列化的速度要快。由于网络带宽非常宝贵,函数名和参数的序列化内容需要尽可能小,以减小传输负载。
下面将通过 Java 编写一个简单的序列化程序。
打开 IDEA,选择构建一个 Maven 项目。
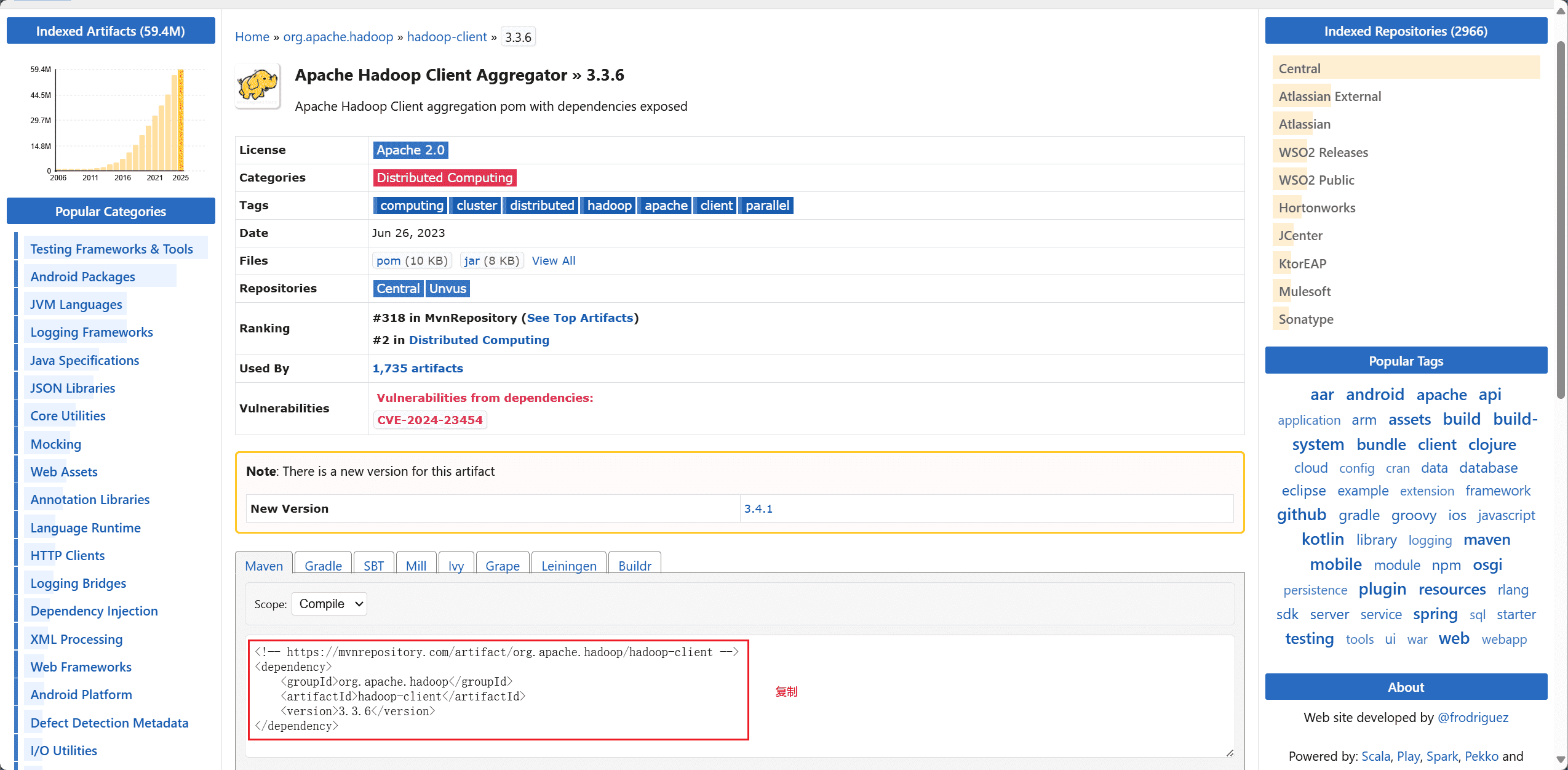
进入 maven 官方官网,搜索 hadoop-client,选择对应的 Hbase 版本,将依赖配置复制下来。
打开项目的 pom.xml 文件。
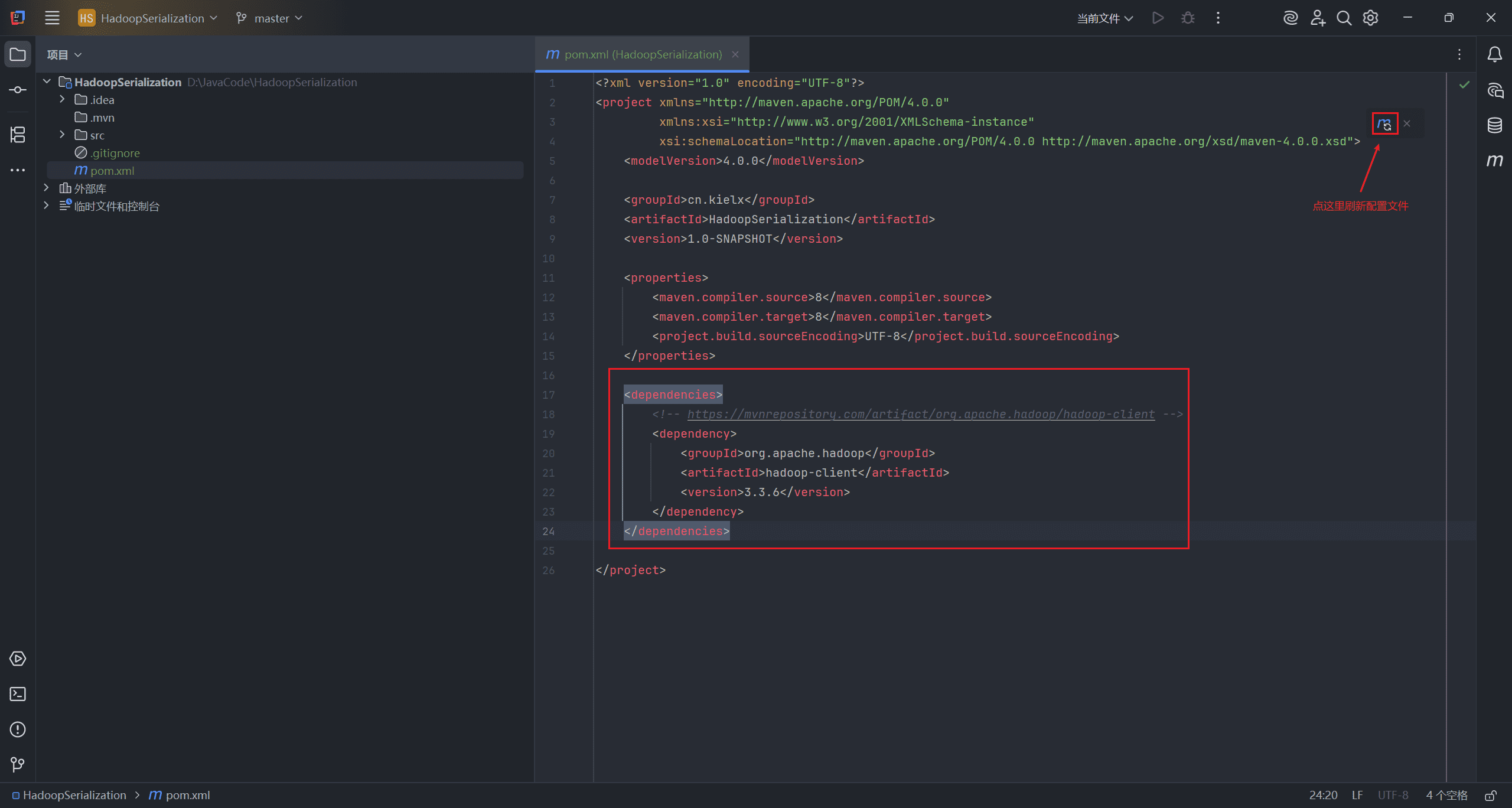
创建 <dependencies> 标签,将复制的配置粘贴进去,刷新配置文件。
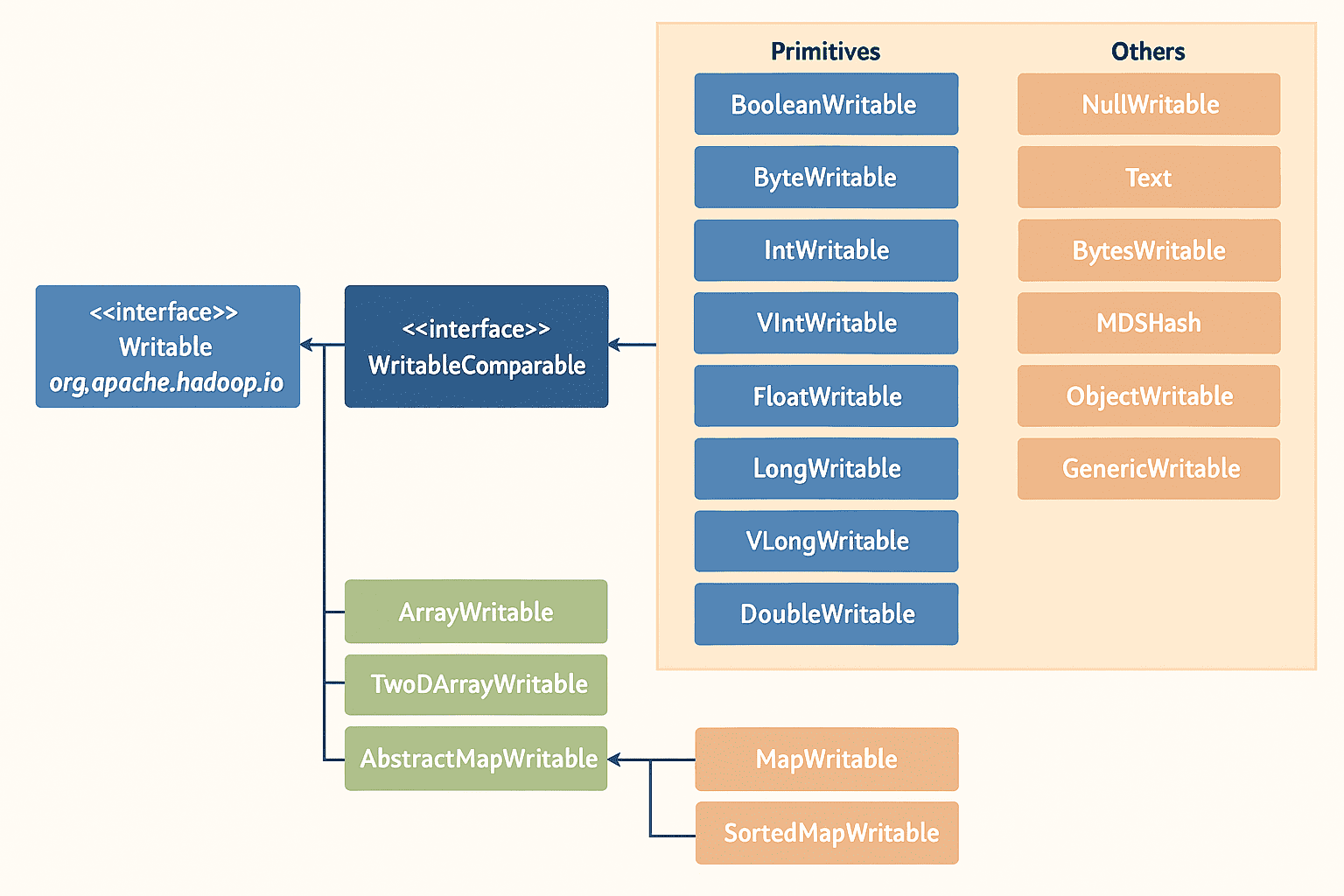
Writable 和 WritableComparable
Hadoop 中的数据序列化和反序列化是通过 Writable 接口来实现的。这个接口有两个方法:void write(DataOutput out) 和 void readFields(DataInput in)。write 方法将对象序列化为字节流,readFields 方法是反序列化操作,它从输入的字节流中读取数据并转换成对象。
Writable 接口的子接口是 WritableComparable。这个接口结合了 Writable 和 Comparable 两个接口的功能。实现这个接口的类不仅支持序列化和反序列化,还支持对值进行比较。让 Hadoop 的数据类型实现这个接口,在对数据对象进行排序和分组时会非常有用。
Hadoop 自带支持许多 WritableComparable 类型的封装类。这些封装类用于包装 Java 的基本类型。例如,IntWritable 封装类用于包装一个 int 类型的数据,而 BooleanWritable 封装类则用于包装 boolean 类型的数据。
下面的方法接收一个 Writable 类型的对象,并将其序列化为字节流。它使用 write 方法将 Writable 类型的内容写入字节流中。该字节流随后会被转换为十六进制字符串,以便在控制台上显示。org.apache.hadoop.util.StringUtils 工具类提供了一些静态函数,可以帮助我们将字节数组转换为十六进制字符串:
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.util.StringUtils;
import java.io.ByteArrayOutputStream;
import java.io.DataOutputStream;
import java.io.IOException;
public class DataSerialization {
public static String serializeToByteString(Writable writable) throws IOException {
// 创建一个内存中的字节输出流,用于接收序列化后的原始字节数据,相当于一个容器。
// 这个流会暂时存储序列化结果,后续可以将其转为 byte[] 或字符串。
ByteArrayOutputStream outputStream = new ByteArrayOutputStream();
// 用 DataOutputStream 包装字节输出流,使其具备写入基本数据类型(如 int、long、String 等)的能力,相当于一个智能写入工具。
// Writable 的 write() 方法要求参数是 DataOutput 类型,而 ByteArrayOutputStream 本身不具备这个功能。
DataOutputStream dataOutputStream = new DataOutputStream(outputStream);
// 调用 Writable 对象的 write() 方法,将对象的内容序列化为字节流,写入到 DataOutputStream 中。
// 实际上对象的每个字段会被逐一编码成字节形式。
writable.write(dataOutputStream);
// 写入完成后,关闭数据输出流。
dataOutputStream.close();
// 从 ByteArrayOutputStream 中提取字节数组,即序列化后的原始二进制数据。
byte[] byteArray = outputStream.toByteArray();
// 使用 Hadoop 提供的工具类 StringUtils,将字节数组转换为十六进制字符串。
// 这样可以方便地在控制台输出、调试或记录序列化后的结果。
return StringUtils.byteToHexString(byteArray);
}
}
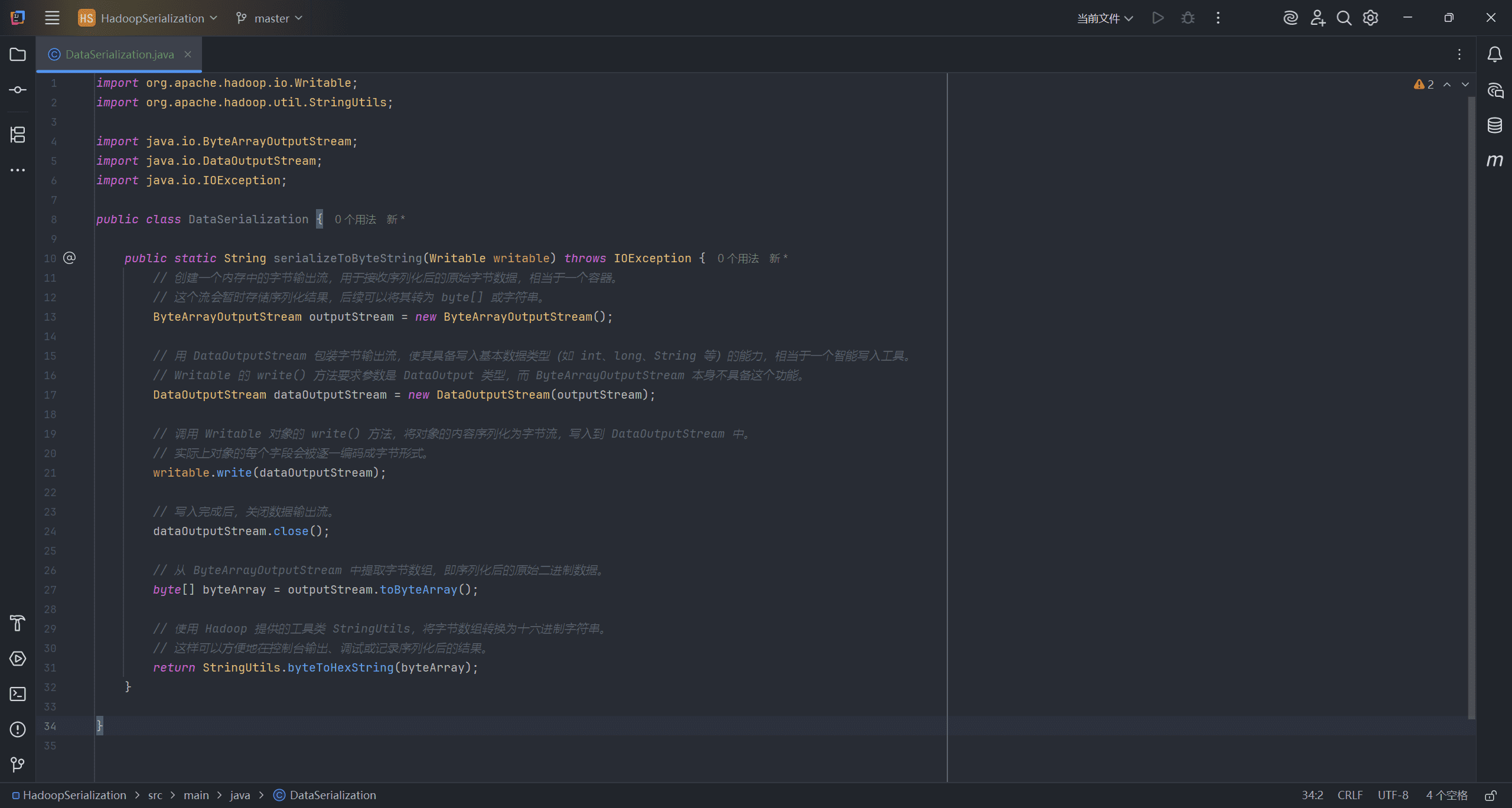
下面的代码会创建四个类的对象,作为学习 Hadoop 序列化的示例。用三个数字作为数据内容:100(一个较小的整数)、1048576(一个普通整数)、4589938592L(一个较大的长整型数字):
import org.apache.hadoop.io.*;
import org.apache.hadoop.util.StringUtils;
import java.io.ByteArrayOutputStream;
import java.io.DataOutputStream;
import java.io.IOException;
public class DataSerialization {
public static String serializeToByteString(Writable writable) throws IOException {
// 创建一个内存中的字节输出流,用于接收序列化后的原始字节数据,相当于一个容器。
// 这个流会暂时存储序列化结果,后续可以将其转为 byte[] 或字符串。
ByteArrayOutputStream outputStream = new ByteArrayOutputStream();
// 用 DataOutputStream 包装字节输出流,使其具备写入基本数据类型(如 int、long、String 等)的能力,相当于一个智能写入工具。
// Writable 的 write() 方法要求参数是 DataOutput 类型,而 ByteArrayOutputStream 本身不具备这个功能。
DataOutputStream dataOutputStream = new DataOutputStream(outputStream);
// 调用 Writable 对象的 write() 方法,将对象的内容序列化为字节流,写入到 DataOutputStream 中。
// 实际上对象的每个字段会被逐一编码成字节形式。
writable.write(dataOutputStream);
// 写入完成后,关闭数据输出流。
dataOutputStream.close();
// 从 ByteArrayOutputStream 中提取字节数组,即序列化后的原始二进制数据。
byte[] byteArray = outputStream.toByteArray();
// 使用 Hadoop 提供的工具类 StringUtils,将字节数组转换为十六进制字符串。
// 这样可以方便地在控制台输出、调试或记录序列化后的结果。
return StringUtils.byteToHexString(byteArray);
}
public static void main(String[] args) throws IOException {
// 创建 Hadoop 中的 IntWritable,用于固定长度(4 字节)序列化 int 类型
IntWritable intWritable = new IntWritable();
// 创建 VIntWritable,用于变长编码 int 类型,更节省空间
VIntWritable vIntWritable = new VIntWritable();
// 创建 LongWritable,用于固定长度(8 字节)序列化 long 类型
LongWritable longWritable = new LongWritable();
// 创建 VLongWritable,用于变长编码 long 类型
VLongWritable vLongWritable = new VLongWritable();
// 准备三个测试用的数据:小整数、中等整数、大整数(long)
int smallInt = 100;
int mediumInt = 1048576; // 2 的 20 次方
long bigInt = 4589938592L; // 一个超过 int 范围的大整数
// smallInt 使用 IntWritable 进行序列化
System.out.println("使用 IntWritable 序列化 smallInt(100)的结果:");
intWritable.set(smallInt); // 设置值
System.out.println(serializeToByteString(intWritable)); // 序列化并打印十六进制结果
// smallInt 使用 VIntWritable 进行序列化
System.out.println("使用 VIntWritable 序列化 smallInt(100)的结果:");
vIntWritable.set(smallInt);
System.out.println(serializeToByteString(vIntWritable));
// mediumInt 使用 IntWritable 序列化
System.out.println("使用 IntWritable 序列化 mediumInt(1048576)的结果:");
intWritable.set(mediumInt);
System.out.println(serializeToByteString(intWritable));
// mediumInt 使用 VIntWritable 序列化
System.out.println("使用 VIntWritable 序列化 mediumInt(1048576)的结果:");
vIntWritable.set(mediumInt);
System.out.println(serializeToByteString(vIntWritable));
// bigInt 使用 LongWritable 序列化
System.out.println("使用 LongWritable 序列化 bigInt(4589938592L)的结果:");
longWritable.set(bigInt);
System.out.println(serializeToByteString(longWritable));
// bigInt 使用 VLongWritable 序列化
System.out.println("使用 VLongWritable 序列化 bigInt(4589938592L)的结果:");
vLongWritable.set(bigInt);
System.out.println(serializeToByteString(vLongWritable));
}
}
程序使用 IntWritable 和 VIntWritable 作为小整数和中等整数的封装类。对于大整数,则使用 LongWritable 和 VLongWritable。
IntWritable 类始终使用固定的 4 个字节来表示一个整数,无论它存储的值是多少。而 VIntWritable 类更智能,它所使用的字节数取决于数据的实际大小。比如数字 100,VIntWritable 只使用了一个字节。
同样的区别也出现在 LongWritable 和 VLongWritable 的序列化结果中。
4、Hadoop versus Java serialization(Hadoop 与 Java 序列化的对比)
此时会出现一个问题:为什么 Hadoop 使用的是 Writable 接口,而不是依赖 Java 的序列化机制?我们来尝试使用 Java 的数据类型和序列化方式,对前面示例中的值进行序列化:
import org.apache.hadoop.util.StringUtils;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.ObjectOutputStream;
public class JavaSerialization {
public static String javaSerializeToByteString(Object o) throws IOException {
// 创建一个字节输出流,用于临时存储 Java 序列化后的对象数据(字节形式)
// 所有写入的数据都会保存在内存中,后面可以提取为 byte[]
ByteArrayOutputStream outputStream = new ByteArrayOutputStream();
// 创建一个 ObjectOutputStream,它是 Java 自带的序列化工具类
// 可以将实现了 Serializable 接口的对象写成字节流
ObjectOutputStream objectOutputStream = new ObjectOutputStream(outputStream);
// 将传入的对象 o 写入对象输出流中(即进行 Java 标准序列化)
objectOutputStream.writeObject(o);
// 关闭流,确保所有数据都写入到底层 outputStream
objectOutputStream.close();
// 从 outputStream 中提取完整的字节数组(即序列化结果)
byte[] byteArray = outputStream.toByteArray();
// 使用 Hadoop 的 StringUtils 工具,将字节数组转换成十六进制字符串,方便显示和比较
return StringUtils.byteToHexString(byteArray);
}
}
Java 提供了 ObjectOutputStream 类,用于将对象序列化为字节流。ObjectOutputStream 类支持一个 writeObject 方法。下面的代码使用该方法对这三个数字进行了序列化:
import org.apache.hadoop.util.StringUtils;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.ObjectOutputStream;
public class JavaSerialization {
public static String javaSerializeToByteString(Object o) throws IOException {
// 创建一个字节输出流,用于临时存储 Java 序列化后的对象数据(字节形式)
// 所有写入的数据都会保存在内存中,后面可以提取为 byte[]
ByteArrayOutputStream outputStream = new ByteArrayOutputStream();
// 创建一个 ObjectOutputStream,它是 Java 自带的序列化工具类
// 可以将实现了 Serializable 接口的对象写成字节流
ObjectOutputStream objectOutputStream = new ObjectOutputStream(outputStream);
// 将传入的对象 o 写入对象输出流中(即进行 Java 标准序列化)
objectOutputStream.writeObject(o);
// 关闭流,确保所有数据都写入到底层 outputStream
objectOutputStream.close();
// 从 outputStream 中提取完整的字节数组(即序列化结果)
byte[] byteArray = outputStream.toByteArray();
// 使用 Hadoop 的 StringUtils 工具,将字节数组转换成十六进制字符串,方便显示和比较
return StringUtils.byteToHexString(byteArray);
}
public static void main(String[] args) throws IOException {
// 定义三个不同大小的测试数字
int smallInt = 100; // 小整数
int mediumInt = 1048576; // 中等整数(2^20)
long bigInt = 4589938592L; // 大整数(超出 int 范围,使用 long)
// 使用 Java 的序列化机制对 smallInt 进行序列化
System.out.println("使用 Java 序列化器序列化 smallInt(100)的结果:");
System.out.println(javaSerializeToByteString(new Integer(smallInt)));
// 使用 Java 的序列化机制对 mediumInt 进行序列化
System.out.println("使用 Java 序列化器序列化 mediumInt(1048576)的结果:");
System.out.println(javaSerializeToByteString(new Integer(mediumInt)));
// 使用 Java 的序列化机制对 bigInt(long 类型)进行序列化
System.out.println("使用 Java 序列化器序列化 bigInt(4589938592L)的结果:");
System.out.println(javaSerializeToByteString(new Long(bigInt)));
}
}
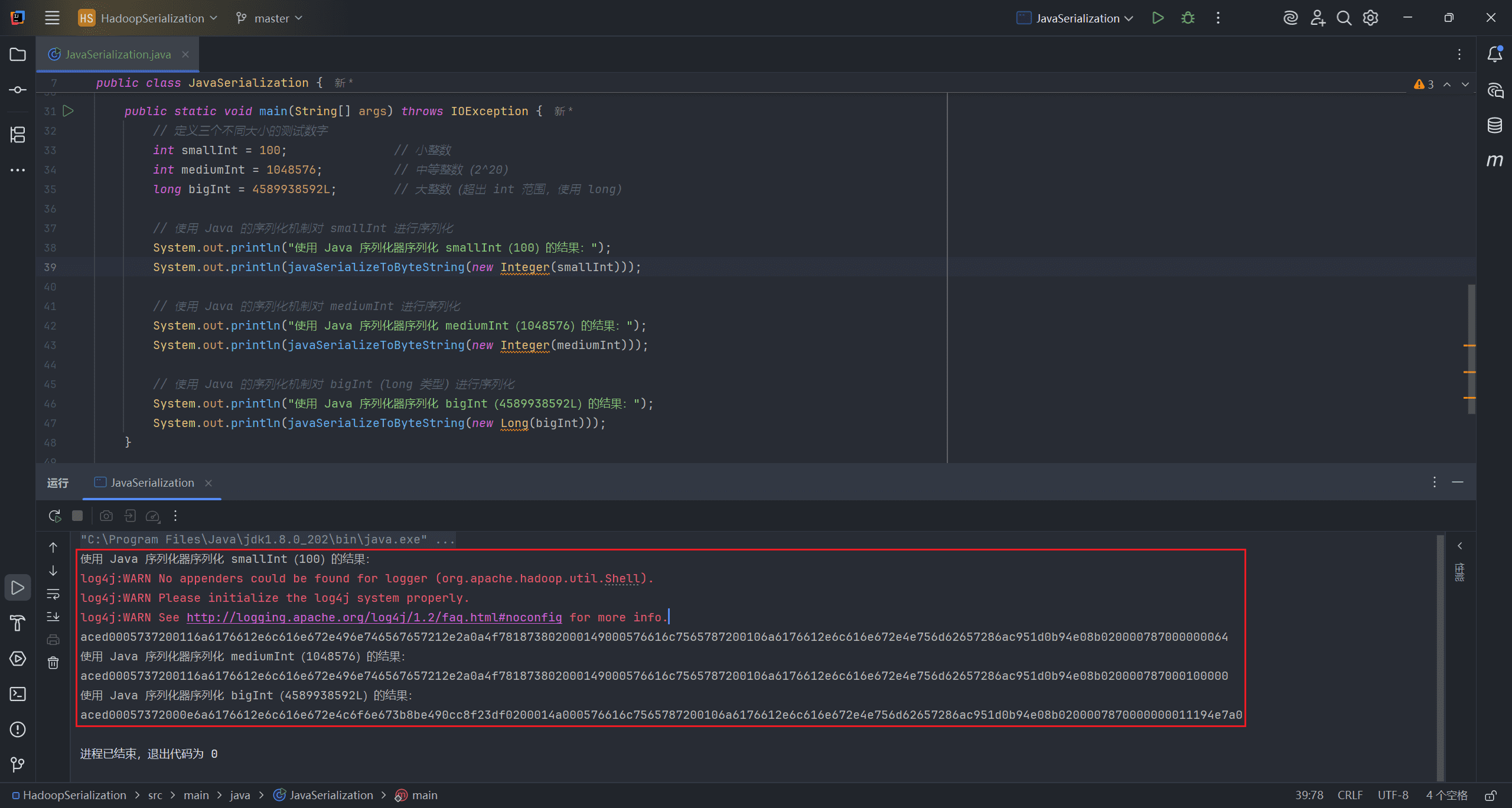
很明显,Java 序列化后的数据要比 Writable 类序列化后的数据大得多。Hadoop 的核心就是围绕磁盘或网络上的序列化与反序列化展开,因此紧凑性非常重要。而 Java 序列化为了表示一个对象,需要消耗更多的字节。
Java 序列化效率低的原因在于:Java 并不会对要序列化的对象所属的类做任何假设。这就意味着,每个被序列化的对象都要带上与类相关的元数据(如类名、结构信息等)。
相比之下,Writable 类是根据字节流直接读取字段,并假设这些字节流一定是它自己的类型。这种机制让数据的表示更加紧凑,从而带来了更高的性能。但代价是:对于 Hadoop 初学者来说,Writable 学习曲线更陡峭。
另一个缺点是:Writable 类只能用于 Java 语言,缺乏跨语言的通用性。
自定义 Writable 类也较为繁琐,开发者必须手动处理字节流中类的格式和字段顺序。为了解决这个问题,Hadoop 曾引入过一个叫 Record IO 的功能。它提供了一种记录定义语言和编译器,可以将记录规范自动转换为 Writable 类。 不过这个功能后来被废弃了,现在推荐使用 Avro 作为替代方案。
二、File Compression(文件压缩)
当我们谈到 Hadoop 时,通常会想到存储在 HDFS 中的超大文件,以及在存储 HDFS 块或运行 MapReduce 任务时,集群节点之间大量的数据传输。如果能够在某种程度上减少文件大小,就能同时减少存储需求和网络中的数据传输量,这正是 Hadoop 中数据压缩发挥作用的地方。
Hadoop 中各个阶段的数据压缩
在 Hadoop 的 MapReduce 流程中,我们可以在多个阶段进行数据压缩:
- 压缩输入文件 —— 我们可以压缩输入文件,以减少 HDFS 中的存储空间。如果输入文件被压缩了,那么在被 MapReduce 作业处理时,这些文件会被自动解压。
- 压缩 map 输出 —— 我们可以压缩中间的 map 输出数据。由于 map 输出会写入磁盘,且多个 map 输出的数据会被 reducer 使用,因此这些 map 输出的数据需要通过网络传输到执行 reduce 任务的节点。
- 压缩输出文件 —— 我们也可以压缩 MapReduce 作业的最终输出结果文件。
Hadoop 常用的压缩格式
下面是 Hadoop 中四种常用压缩格式的对比:
| 压缩格式 | 算法 | 压缩率 | 压缩速度 | 文件扩展名 | 是否可切分 |
|---|---|---|---|---|---|
| gzip | DEFLATE | 非常高 | 较快 | .gz | 否 |
| lzo | lzo | 较高 | 快 | .lzo | 是(如果有索引) |
| snappy | snappy | 较高 | 快 | .snappy | 否 |
| bzip2 | bzip2 | 最高 | 慢 | .bz2 | 是 |
-
gzip
gzip 是 Hadoop 原生支持的压缩格式。gzip 基于 DEFLATE 算法,它结合了 LZ77 和霍夫曼编码(Huffman Coding)。
应用场景:当每个压缩后的文件小于 130MB(即一个 HDFS block 大小以内)时,可以考虑使用 gzip 压缩格式。例如,将一天或一小时的日志压缩成一个 gzip 文件,然后 MapReduce 程序可以通过多个 gzip 文件并发运行。Hive 程序、Streaming 程序以及用 Java 编写的 MapReduce 程序都可以像处理文本一样处理 gzip 文件。压缩后原有程序不需要做任何修改。
// 创建压缩编解码器工厂对象,用于获取指定格式的压缩器 CompressionCodecFactory factory = new CompressionCodecFactory(conf); // 根据类名获取 gzip 对应的压缩编解码器 CompressionCodec codec = factory.getCodecByClassName("org.apache.hadoop.io.compress.GzipCodec"); // 使用 codec 创建压缩输出流,后续写入的数据会被自动以 gzip 格式压缩 CompressionOutputStream compressionOutputStream = codec.createOutputStream(out); -
LZO
LZO 压缩格式由许多较小的(约 256KB)压缩数据块组成,允许任务在块边界上进行切分(split)。此外,LZO 设计之初就追求速度:其解压速度大约是 gzip 的两倍,意味着它足够快以匹配硬盘读取速度。它的压缩率不如 gzip——通常压缩后的文件会比 gzip 版本大约 50%。但相比完全未压缩的文件,LZO 压缩后的大小仍然只有原来的 20%-50%,这意味着 IO 密集型的作业在 map 阶段可提速约 4 倍。
应用场景:适合单个压缩后超过 200MB 的大文本文件。文件越大,LZO 的压缩性能优势越明显。
// 创建压缩编解码器工厂对象 CompressionCodecFactory factory = new CompressionCodecFactory(conf); // 根据类名获取 lzo 对应的压缩编解码器(需使用 Hadoop-LZO 提供的类) CompressionCodec codec = factory.getCodecByClassName("com.hadoop.compression.lzo.LzopCodec"); // 创建 LZO 压缩输出流 CompressionOutputStream compressionOutputStream = codec.createOutputStream(out); -
Snappy
Snappy 是一个压缩/解压缩库。它的目标不是最大压缩率或与其他压缩库兼容,而是追求极高的压缩速度和合理的压缩效果。
例如,与 zlib 的最快压缩模式相比,Snappy 对大多数输入数据的压缩速度快一个数量级,但压缩后的文件可能比 zlib 版本大 20% 到 100%。在 64 位模式下的单核 Core i7 处理器上,Snappy 的压缩速度约为 250 MB/秒或更快,解压速度约为 500 MB/秒或更快。
Snappy 被广泛应用于 Google 内部,从 BigTable、MapReduce 到 RPC 系统都有使用。
应用场景:当 MapReduce 作业的 map 输出数据量大时,可以将 Snappy 用作 map 到 reduce 之间中间数据的压缩格式,也可作为某个 MapReduce 作业的输出格式和另一个 MapReduce 作业的输入格式。
// 创建压缩编解码器工厂对象 CompressionCodecFactory factory = new CompressionCodecFactory(conf); // 根据类名获取 snappy 对应的压缩编解码器 CompressionCodec codec = factory.getCodecByClassName("org.apache.hadoop.io.compress.SnappyCodec"); // 创建 Snappy 压缩输出流 CompressionOutputStream compressionOutputStream = codec.createOutputStream(out); -
bzip2
bzip2 是一个免费、无专利的高质量数据压缩器。它的压缩比通常接近最优秀的技术(例如 PPM 系列统计压缩器)的 10%~15%,但压缩速度约为 PPM 的两倍,解压速度约为 PPM 的六倍。
应用场景:适用于对压缩速度要求不高,但对压缩率要求高的情况。例如,可作为 MapReduce 作业的输出格式;或者用于输出数据量较大的任务,数据处理后需归档压缩以减少磁盘占用和后续数据使用成本;又或者用于对单个大型文本进行压缩,既减少存储空间,又支持切分,同时还能保持与现有程序兼容(即无需修改程序)。
// 创建压缩编解码器工厂对象 CompressionCodecFactory factory = new CompressionCodecFactory(conf); // 根据类名获取 bzip2 对应的压缩编解码器 CompressionCodec codec = factory.getCodecByClassName("org.apache.hadoop.io.compress.BZip2Codec"); // 创建 BZip2 压缩输出流 CompressionOutputStream compressionOutputStream = codec.createOutputStream(out);
三、File Handling(文件处理)
Hadoop 的 HDFS 和 MapReduce 子框架主要是为处理大型数据文件而设计的,对于小文件的处理不仅效率低下,而且会占用大量磁盘空间(每个小文件都会占用一个块,HDFS 默认的块大小为 128MB)。
解决方案通常是选用一种“容器”来统一存储这些小文件。HDFS 提供了两种容器类型:SequenceFile 和 MapFile。
1、SequenceFile Container Class(SequenceFile 容器类)
**SequenceFile 是 Hadoop API 提供的一种二进制文件格式。**这种二进制文件可以直接将 <key, value> 键值对序列化写入文件中。其中 Key 和 Value 都可以是任意类型的 Writable。目前,许多人基于这种文件格式提出了一些将中小文件存储到 HDFS 的解决方案,其基本思路是:将多个小文件合并成一个大文件,并建立这些小文件位置信息的索引。需要注意的是,SequenceFile 中的 Key 并不进行排序。
SequenceFile 的压缩方式
SequenceFile 文件支持三种压缩类型:
- NONE:不进行压缩。
- RECORD:仅压缩每条记录中的 value。
- BLOCK:将一组记录作为一个块整体压缩。
SequenceFile 的结构
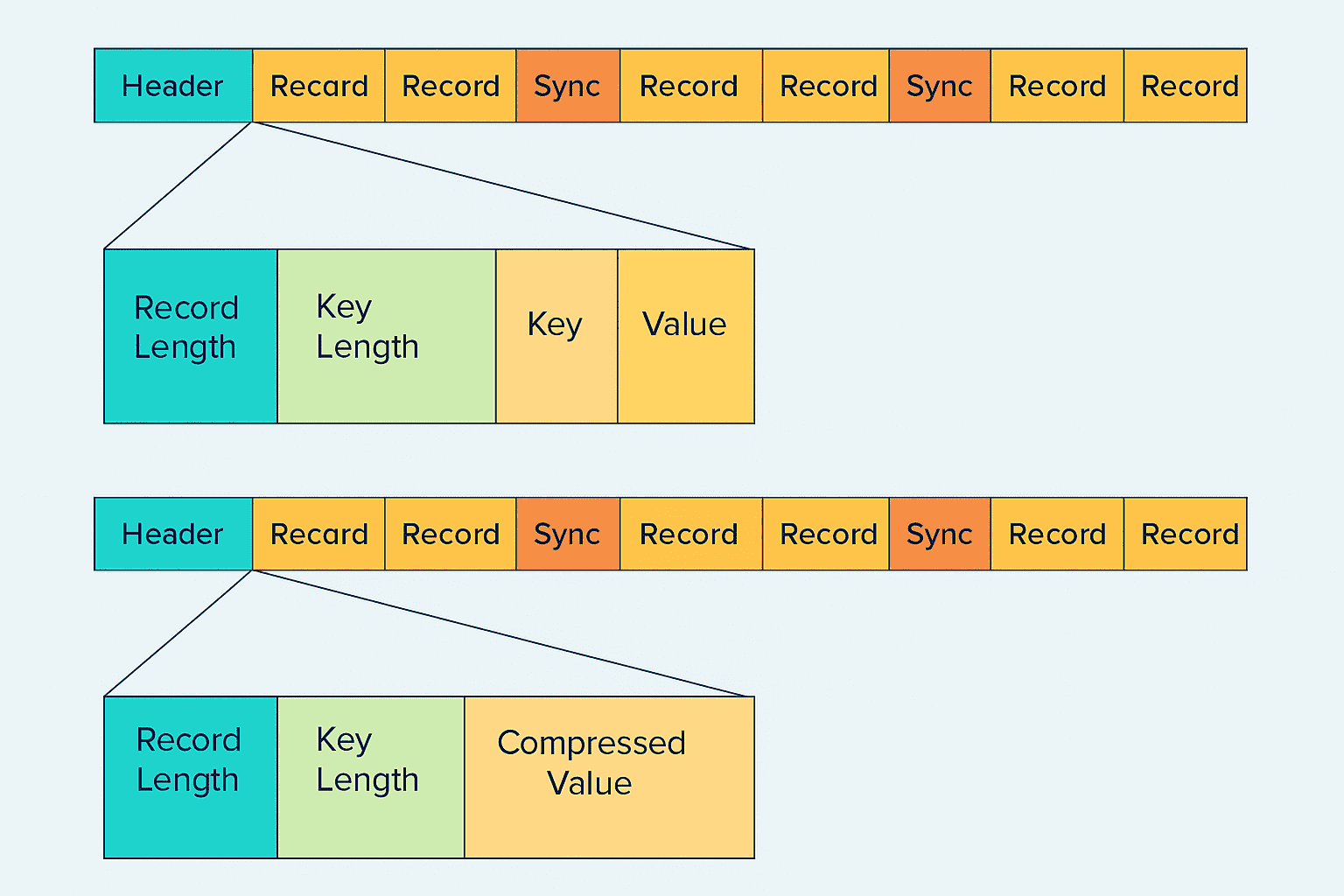
一个 SequenceFile 是由多条记录(Record)组成的。每条记录都是一个 <key, value> 键值对。每条记录中包含以下内容:记录长度(Record Length)、键的长度(Key Length)、键(Key)和值(Value)。此外,文件中某些位置会插入 同步标记(Sync Marker)。在读取或写入 SequenceFile 时,需要提前知道 key 和 value 的类类型,这些类型信息会在文件开头的头部区域(header section)中记录。
SequenceFile 中的同步标记(Sync Marker)
普通压缩文件在大数据环境中无法切分处理,因此只能整体处理。这是因为输入格式中的记录读取器(RecordReader)无法准确地从一个数据块跳转到另一个块中定位记录的起始位置。
而 SequenceFile 中的同步标记(sync marker 或 sync pointer)可以解决这个问题。同步标记记录了数据块之间的边界信息,使得 RecordReader 可以识别块之间的分隔,从而能够正确读取每个数据块中的记录内容。
在下图中你会看到两种 SequenceFile 格式:第一种是未压缩格式,第二种是带压缩格式。如果启用了压缩,那么只有记录中的 value 部分会被压缩,其他元数据(如 key、长度字段等)不会压缩。图中的压缩方式是按记录级别(Record-Level)的压缩。
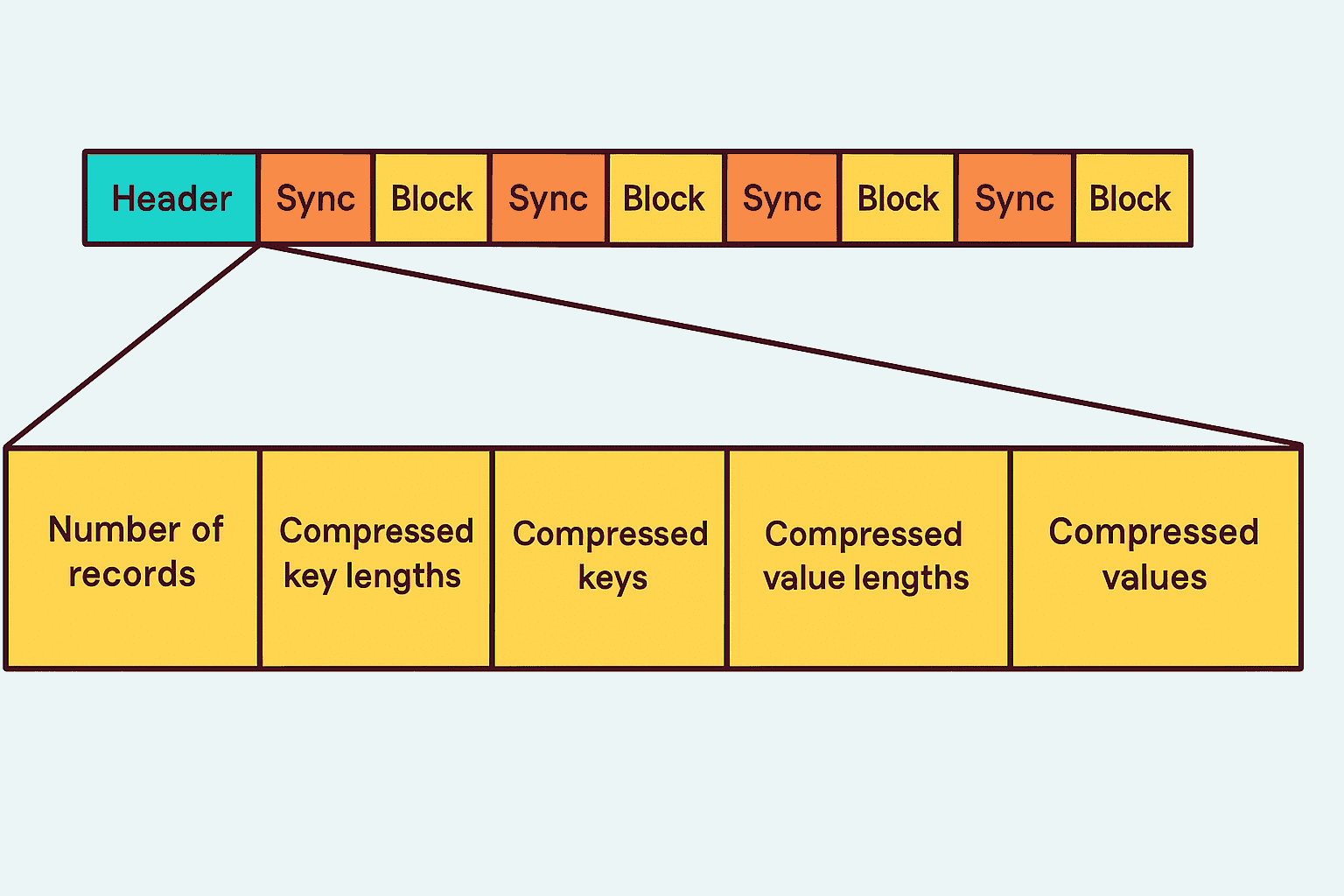
序列文件也可以进行块级压缩。所谓块级压缩,就是将多个记录压缩在一起。下图展示了序列文件中块级压缩的结构。与记录级压缩相比,块级压缩更受青睐,因为它能够利用记录之间的相似性,从而实现比记录级压缩更高效的压缩效果。在进行块级压缩的序列文件中,每个压缩块会包含多个记录。一个块的结构通常包括:未压缩的记录数量、压缩的键长度、压缩的键数据、压缩的值长度,以及实际压缩的值数据。
Sequence 文件格式的优点
该文件格式具有以下优点:
- 压缩可定制:支持压缩,并且可以自定义为基于记录的压缩或基于块的压缩(块级压缩性能更好)。
- 支持任务本地化:由于文件可以被分片,对于 MapReduce 任务的数据本地化支持较好。
- 使用难度低:因为它是 Hadoop 框架提供的 API,业务逻辑端的修改相对简单。
创建 SequenceFile 的步骤
创建 SequenceFile 需要以下步骤:
- 设置 Configuration 配置。
- 获取 FileSystem 文件系统。
- 设置文件输出路径。
- 使用 SequenceFile.createWriter 创建 SequenceFile.Writer 并写入数据。
- 使用 SequenceFile.Writer.append 附加数据。
- 结束写入过程。
